I'm thrilled to share my first PhD project, a joint work with
@vamvas.bsky.social and
@ricosennrich.bsky.social Paper link:
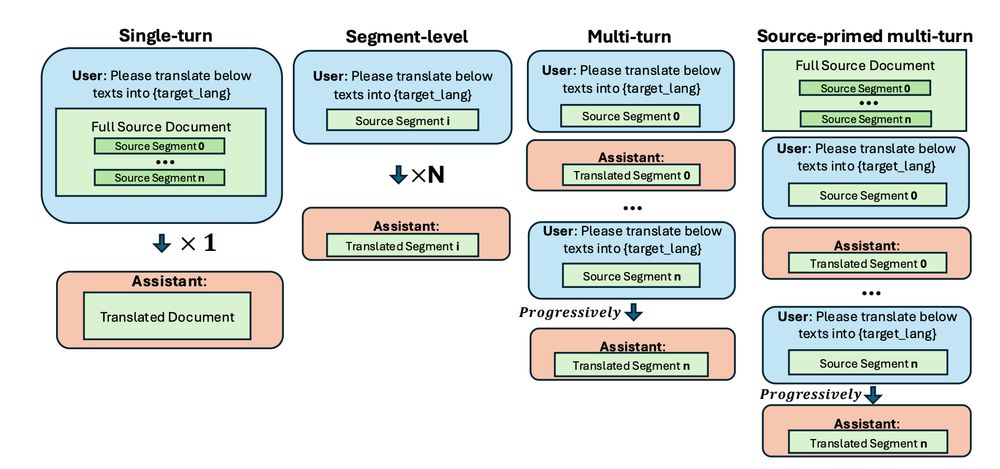
arxiv.org/pdf/2503.10494Long context LLMs have paved the way for document translation, but is simply inputting the whole content the optimal way?
Here's the thread 🧵 [1/n]