Hanlin Zhang
@hlzhang109.bsky.social
23 followers
43 following
11 posts
CS PhD student @Harvard
https://hanlin-zhang.com
Posts
Media
Videos
Starter Packs

Hanlin Zhang
@hlzhang109.bsky.social
· Jul 2

EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Jul 2
EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Jul 2
EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Jul 2
EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Apr 23
Follow My Instruction and Spill the Beans: Scalable Data Extraction from Retrieval-Augmented Generation Systems
Retrieval-Augmented Generation (RAG) improves pre-trained models by incorporating external knowledge at test time to enable customized adaptation. We study the risk of datastore leakage in Retrieval-I...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Apr 23
Eliminating Position Bias of Language Models: A Mechanistic Approach
Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpecte...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Apr 23
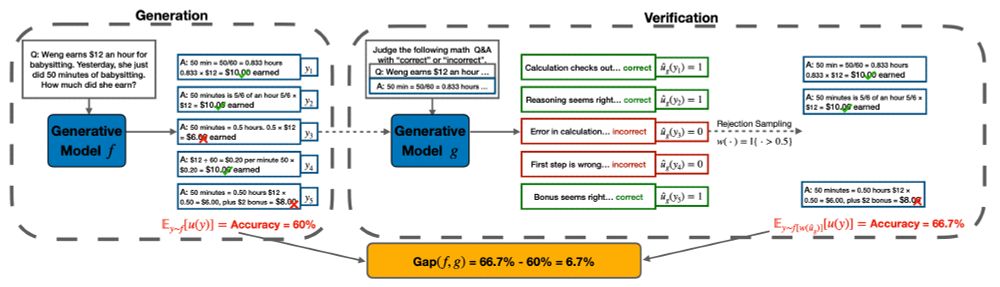
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights...
arxiv.org
Hanlin Zhang
@hlzhang109.bsky.social
· Apr 23

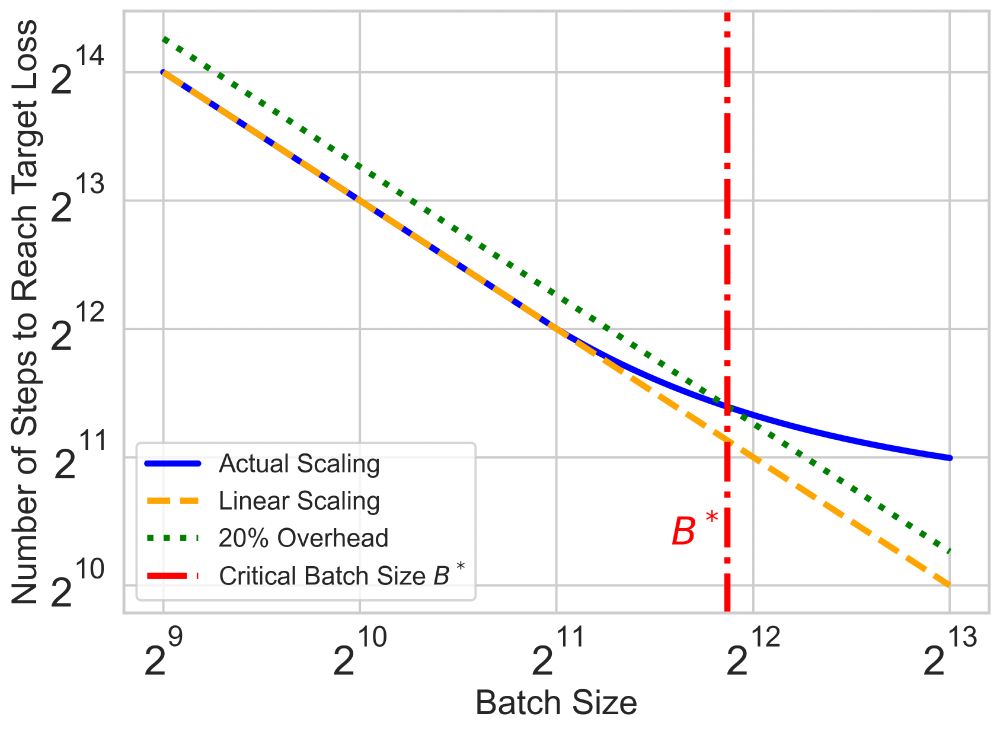
Hanlin Zhang on X: "Critical batch size is crucial for reducing the wall-clock time of large-scale training runs with data parallelism. We find that it depends primarily on data size. 🧵 [1/n] Paper 📑: https://t.co/LFAPtzRkD9 Blog 📝: https://t.co/tGhR6HDgnE" / X
Critical batch size is crucial for reducing the wall-clock time of large-scale training runs with data parallelism. We find that it depends primarily on data size. 🧵 [1/n] Paper 📑: https://t.co/LFAPtzRkD9 Blog 📝: https://t.co/tGhR6HDgnE
x.com

Hanlin Zhang
@hlzhang109.bsky.social
· Apr 23
Reposted by Hanlin Zhang

Reposted by Hanlin Zhang

Reposted by Hanlin Zhang