



Sham Kakade
@shamkakade.bsky.social
Reposted by Sham Kakade

NEW blog post: Do modern #LLMs capture the conceptual diversity of human populations? #KempnerInstitute researchers find #alignment reduces conceptual diversity of language models. bit.ly/4hNjtiI
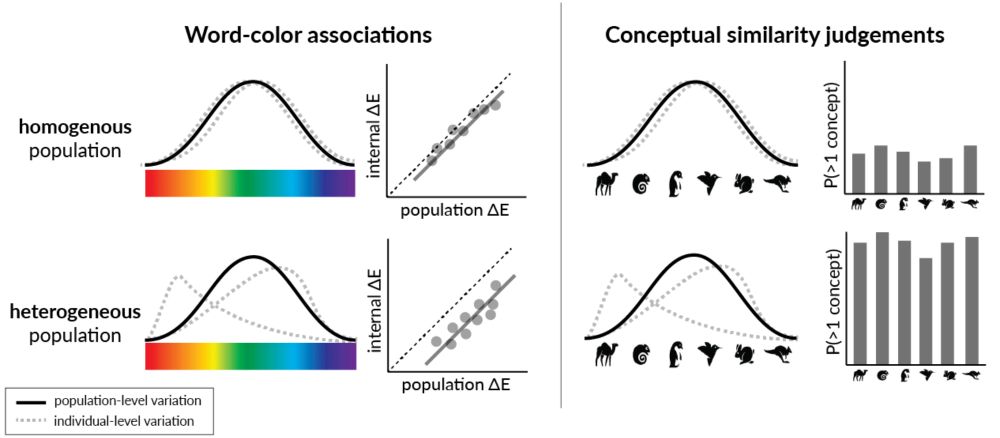
Alignment reduces conceptual diversity of language models - Kempner Institute
As large language models (LLMs) have become more sophisticated, there’s been growing interest in using LLM-generated responses in place of human data for tasks such as polling, user studies, and […]
bit.ly
February 10, 2025 at 3:19 PM
NEW blog post: Do modern #LLMs capture the conceptual diversity of human populations? #KempnerInstitute researchers find #alignment reduces conceptual diversity of language models. bit.ly/4hNjtiI
Reposted by Sham Kakade
NEW in the #KempnerInstitute blog: learn about ProCyon, a multimodal foundation model to model, generate & predict protein phenotypes. Read it here: bit.ly/4fA8xUk

December 19, 2024 at 7:22 PM
NEW in the #KempnerInstitute blog: learn about ProCyon, a multimodal foundation model to model, generate & predict protein phenotypes. Read it here: bit.ly/4fA8xUk
Reposted by Sham Kakade
Calling college grads interested in intelligence research: the application for the #KempnerInstitute's post-bac program w/ the Harvard Kenneth C. Griffin Graduate School of Arts and Sciences Office for Equity, Diversity, Inclusion & Belonging is now open! Apply by Feb. 1, 2025.
t.co/jdJrzRegL0
t.co/jdJrzRegL0
https://bit.ly/4iohnqE
t.co
December 9, 2024 at 7:43 PM
Calling college grads interested in intelligence research: the application for the #KempnerInstitute's post-bac program w/ the Harvard Kenneth C. Griffin Graduate School of Arts and Sciences Office for Equity, Diversity, Inclusion & Belonging is now open! Apply by Feb. 1, 2025.
t.co/jdJrzRegL0
t.co/jdJrzRegL0
Reposted by Sham Kakade
NEW in the #KempnerInstitute blog: A method to predict how #LLMs scale w/ compute across different datasets. Read it here:

Loss-to-Loss Prediction - Kempner Institute
Scaling laws – which reliably predict the performance of large language models (LLMs) as a function of their size and the amount of data they have been trained on – […]
bit.ly
December 9, 2024 at 8:44 PM
NEW in the #KempnerInstitute blog: A method to predict how #LLMs scale w/ compute across different datasets. Read it here:
Reposted by Sham Kakade

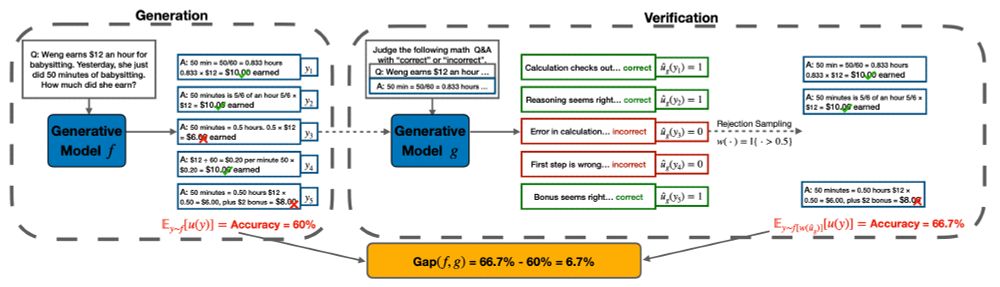
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
December 6, 2024 at 6:02 PM
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
Reposted by Sham Kakade
NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
#ML #AI

December 3, 2024 at 1:24 AM
NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
#ML #AI
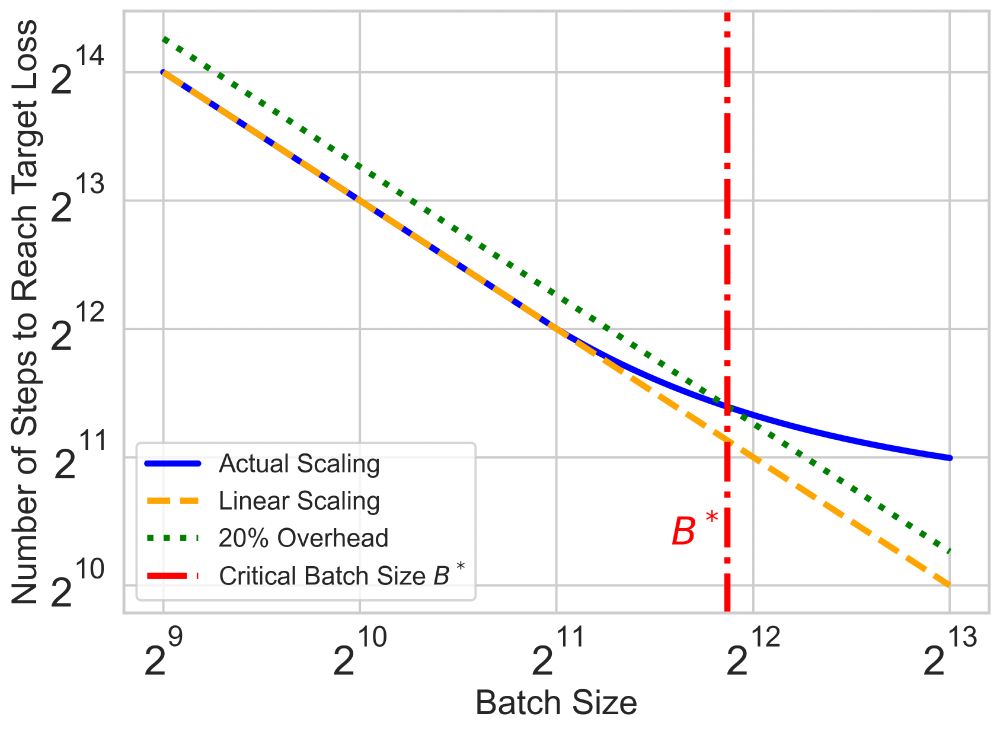
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
November 22, 2024 at 8:19 PM
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
Reposted by Sham Kakade

How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.

November 21, 2024 at 3:11 PM
How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.