Hope Schroeder
@hopeschroeder.bsky.social
330 followers
280 following
54 posts
Studying NLP, CSS, and Human-AI interaction. PhD student @MIT. Previously at Microsoft FATE + CSS, Oxford Internet Institute, Stanford Symbolic Systems
hopeschroeder.com
Posts
Media
Videos
Starter Packs


Hope Schroeder
@hopeschroeder.bsky.social
· Jul 24
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 23
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22

Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Subjective Tasks
LLM use in annotation is becoming widespread, and given LLMs' overall promising performance and speed, simply "reviewing" LLM annotations in interpretive tasks can be tempting. In subjective annotatio...
arxiv.org
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22

Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
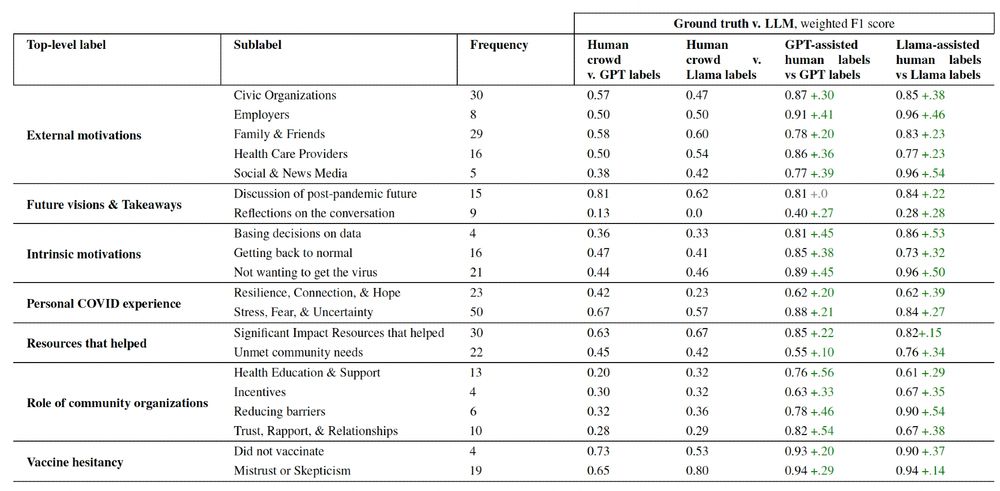
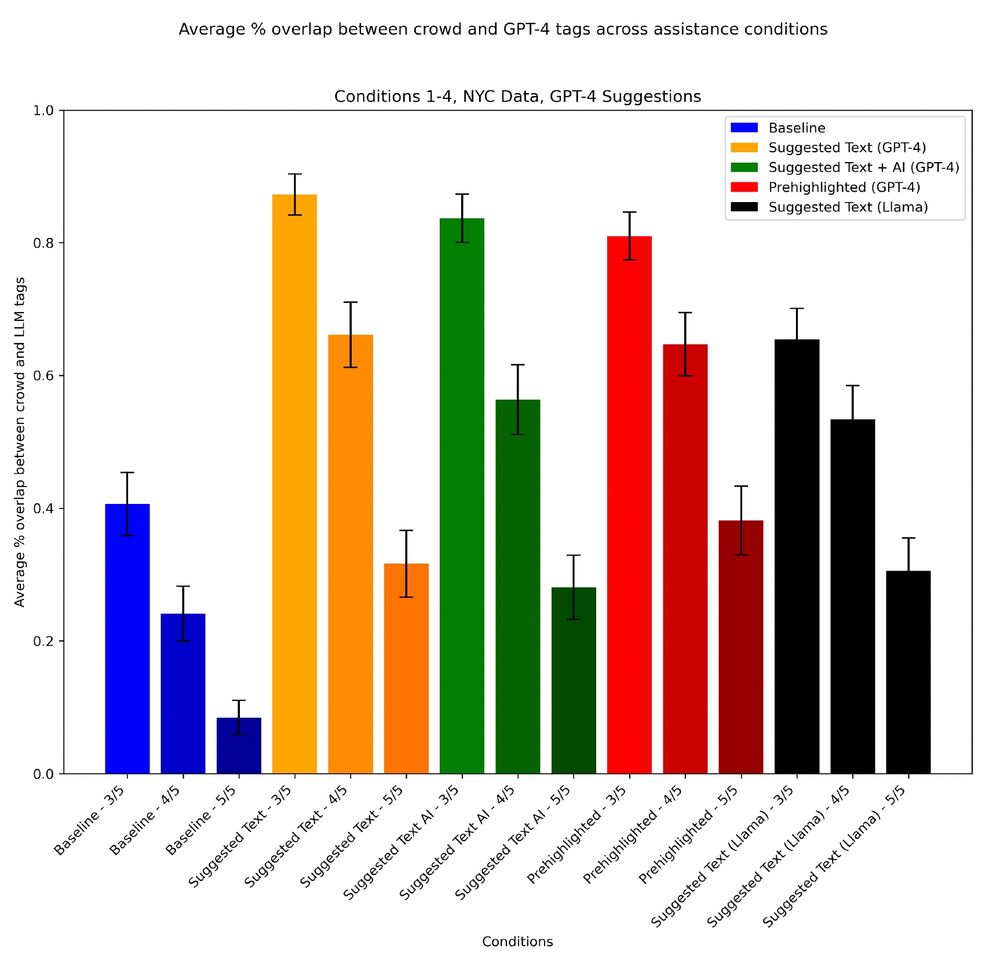
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
Hope Schroeder
@hopeschroeder.bsky.social
· Jul 22
Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Subjective Tasks
LLM use in annotation is becoming widespread, and given LLMs' overall promising performance and speed, simply "reviewing" LLM annotations in interpretive tasks can be tempting. In subjective annotatio...
arxiv.org
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 25
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 24

Disclosure without Engagement: An Empirical Review of Positionality Statements at FAccT | Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
You will be notified whenever a record that you have chosen has been cited.
dl.acm.org
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 24
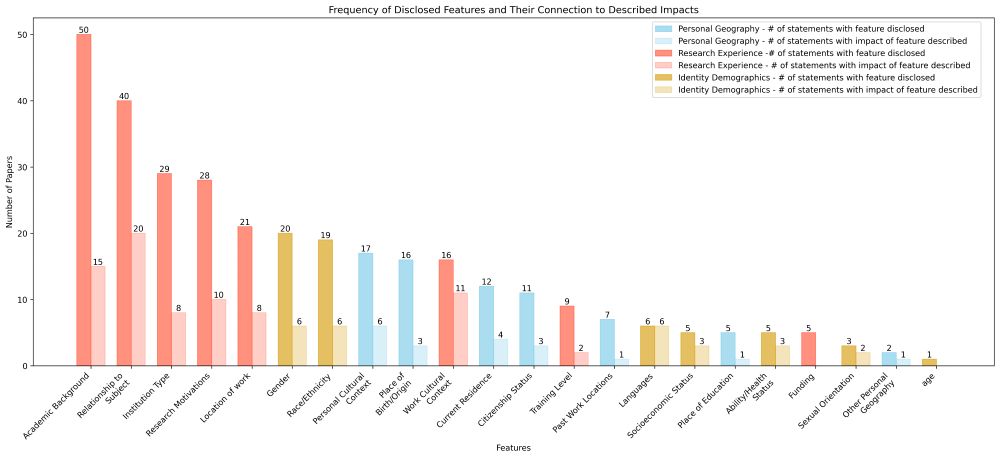
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 24
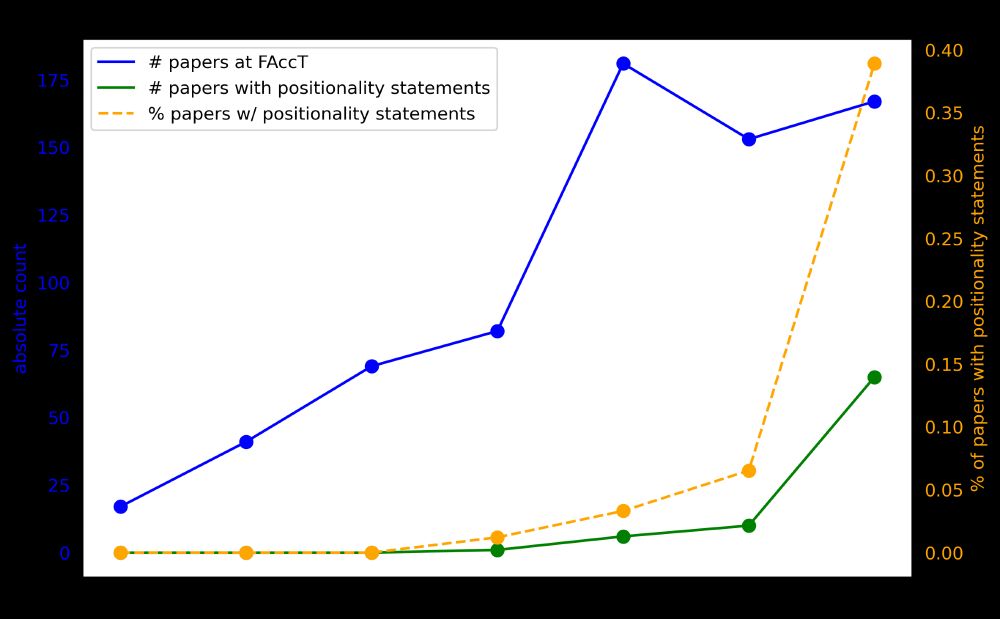
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 24
Hope Schroeder
@hopeschroeder.bsky.social
· Jun 24


Reposted by Hope Schroeder

Hanna Wallach
@hannawallach.bsky.social
· May 20
FATE Research Assistant (“Pre-doc”) - Microsoft Research
The Fairness, Accountability, Transparency, and Ethics (FATE) Research group at Microsoft Research New York City (MSR NYC) is looking for a pre-doctoral research assistant (pre-doc) to start August 20...
www.microsoft.com
Reposted by Hope Schroeder



