




Jaydeep Borkar
@jaydeepborkar.bsky.social
PhD Candidate at Northeastern / Incoming Research Intern + ex-Visiting Researcher at Meta (MSL) / Organizer at the Trustworthy ML Initiative (trustworthyml.org).
s&p in language models + mountain biking.
jaydeepborkar.github.io
s&p in language models + mountain biking.
jaydeepborkar.github.io
Finally, we compare soft (logit-level) vs. hard (sequence-level) distillation. Hard KD is often used when teacher logits are inaccessible. We find that while both show similar rates, hard KD is riskier, inheriting 2.7x more memorization from the teacher than soft KD.

January 23, 2026 at 8:51 PM
Finally, we compare soft (logit-level) vs. hard (sequence-level) distillation. Hard KD is often used when teacher logits are inaccessible. We find that while both show similar rates, hard KD is riskier, inheriting 2.7x more memorization from the teacher than soft KD.
We compute sequence log-prob & avg shannon entropy. We find cross-entropy pushes the model to overfit on examples it is uncertain about, resulting in forced memorization. In contrast, KD permits it to output a flatter, more uncertain distribution rather than forcing memorization

January 23, 2026 at 8:51 PM
We compute sequence log-prob & avg shannon entropy. We find cross-entropy pushes the model to overfit on examples it is uncertain about, resulting in forced memorization. In contrast, KD permits it to output a flatter, more uncertain distribution rather than forcing memorization
Are these “easy” examples universal across architectures (Pythia, OLMo-2, Qwen-3)? We observe that while all models prefer memorizing low entropy data, they don’t **agree** on which examples to memorize. We analyzed cross-model perplexity to decode this selection mechanism.

January 23, 2026 at 8:51 PM
Are these “easy” examples universal across architectures (Pythia, OLMo-2, Qwen-3)? We observe that while all models prefer memorizing low entropy data, they don’t **agree** on which examples to memorize. We analyzed cross-model perplexity to decode this selection mechanism.
This leads us to study why certain examples are easier to memorize? Since our data has no duplicates, duplication isn't the cause. In line with prior work, we compute compressibility (zlib entropy) and perplexity, & find that they are highly correlated with these "easy" examples.

January 23, 2026 at 8:51 PM
This leads us to study why certain examples are easier to memorize? Since our data has no duplicates, duplication isn't the cause. In line with prior work, we compute compressibility (zlib entropy) and perplexity, & find that they are highly correlated with these "easy" examples.
Next, we find that certain examples are consistently memorized across model sizes within a family because they are **inherently easier to memorize**. We find that distilled models preferentially memorize these easy examples (accounting for over 80% of their total memorization).

January 23, 2026 at 8:51 PM
Next, we find that certain examples are consistently memorized across model sizes within a family because they are **inherently easier to memorize**. We find that distilled models preferentially memorize these easy examples (accounting for over 80% of their total memorization).
We find the student recovers 78% of teacher’s generalization over the baseline (std. fine-tuning) while inheriting only 2% of its memorization. This shows the student learns the teacher’s general capabilities, but rejects majority of the examples the teacher exclusively memorized.



January 23, 2026 at 8:51 PM
We find the student recovers 78% of teacher’s generalization over the baseline (std. fine-tuning) while inheriting only 2% of its memorization. This shows the student learns the teacher’s general capabilities, but rejects majority of the examples the teacher exclusively memorized.
Excited to share my work at Meta.
Knowledge Distillation has been gaining traction for LLM utility. We find that distilled models don't just improve performance, they also memorize significantly less training data than standard fine-tuning (reducing memorization by >50%). 🧵
Knowledge Distillation has been gaining traction for LLM utility. We find that distilled models don't just improve performance, they also memorize significantly less training data than standard fine-tuning (reducing memorization by >50%). 🧵

January 23, 2026 at 8:51 PM
Excited to share my work at Meta.
Knowledge Distillation has been gaining traction for LLM utility. We find that distilled models don't just improve performance, they also memorize significantly less training data than standard fine-tuning (reducing memorization by >50%). 🧵
Knowledge Distillation has been gaining traction for LLM utility. We find that distilled models don't just improve performance, they also memorize significantly less training data than standard fine-tuning (reducing memorization by >50%). 🧵
Very excited to be joining Meta GenAI as a Visiting Researcher starting this June in New York City!🗽 I’ll be continuing my work on studying memorization and safety in language models.
If you’re in NYC and would like to hang out, please message me :)
If you’re in NYC and would like to hang out, please message me :)

May 15, 2025 at 3:18 AM
Very excited to be joining Meta GenAI as a Visiting Researcher starting this June in New York City!🗽 I’ll be continuing my work on studying memorization and safety in language models.
If you’re in NYC and would like to hang out, please message me :)
If you’re in NYC and would like to hang out, please message me :)
Really liked this slide by @afedercooper.bsky.social on categorizing extraction vs regurgitation vs memorization of training data at CS&Law today!

March 25, 2025 at 9:11 PM
Really liked this slide by @afedercooper.bsky.social on categorizing extraction vs regurgitation vs memorization of training data at CS&Law today!
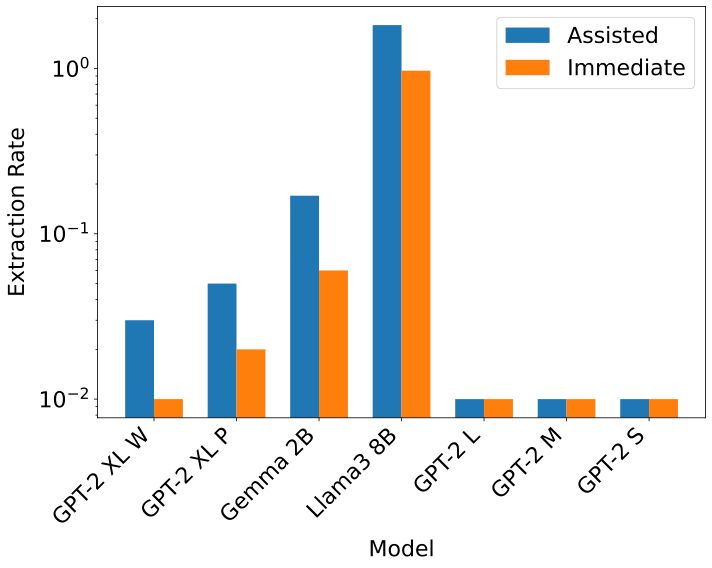
*Takeaway*: these results underscore the need for more holistic memorization audits, where examples that aren’t extracted at a particular time point are also evaluated for any potential risks. E.g., we find that multiple models have equal or more assisted memorization.
March 2, 2025 at 7:20 PM
*Takeaway*: these results underscore the need for more holistic memorization audits, where examples that aren’t extracted at a particular time point are also evaluated for any potential risks. E.g., we find that multiple models have equal or more assisted memorization.
—extends to LLMs: removing one layer of memorized PII exposes a 2nd layer, & so forth. We find this to be true even for random removals (which simulate opt-out requests). PII on the verge of memorization surfaces after others are removed.

March 2, 2025 at 7:20 PM
—extends to LLMs: removing one layer of memorized PII exposes a 2nd layer, & so forth. We find this to be true even for random removals (which simulate opt-out requests). PII on the verge of memorization surfaces after others are removed.
We find that removing extracted PII from the data & re-finetuning from scratch leads to the extraction of other PII. However, this phenomenon stops after certain iterations. Our results confirm that this layered memorization—termed the Onion Effect (Carlini et al. 2022)…

March 2, 2025 at 7:20 PM
We find that removing extracted PII from the data & re-finetuning from scratch leads to the extraction of other PII. However, this phenomenon stops after certain iterations. Our results confirm that this layered memorization—termed the Onion Effect (Carlini et al. 2022)…
We find that: 1) extraction increases substantially with the amount of PII contained in the model’s training set, & 2) inclusion of more PII leads to existing PII being at higher risk of extraction. This effect can increase extraction by over 7× in our setting.

March 2, 2025 at 7:20 PM
We find that: 1) extraction increases substantially with the amount of PII contained in the model’s training set, & 2) inclusion of more PII leads to existing PII being at higher risk of extraction. This effect can increase extraction by over 7× in our setting.
We run various tests to characterize the underlying reason for assisted memorization. We causally remove overlapping n-grams based on our methodology and find a strong correlation.

March 2, 2025 at 7:20 PM
We run various tests to characterize the underlying reason for assisted memorization. We causally remove overlapping n-grams based on our methodology and find a strong correlation.
The literature so far lacks a clear understanding of the complete memorization landscape throughout training. In this work, we provide a complete taxonomy & uncover novel forms of memorization that arise during training.

March 2, 2025 at 7:20 PM
The literature so far lacks a clear understanding of the complete memorization landscape throughout training. In this work, we provide a complete taxonomy & uncover novel forms of memorization that arise during training.
We observe a phenomenon we call assisted memorization: we find that most PII (email ID) isn’t extracted after it is first seen. But fine-tuning further on data that contains n-grams that overlap with these PII finally leads to their extraction. This is a key factor (in our settings, up to 1/3).
March 2, 2025 at 7:20 PM
We observe a phenomenon we call assisted memorization: we find that most PII (email ID) isn’t extracted after it is first seen. But fine-tuning further on data that contains n-grams that overlap with these PII finally leads to their extraction. This is a key factor (in our settings, up to 1/3).
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680

March 2, 2025 at 7:20 PM
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
—extends to LLMs: removing one layer of memorized PII exposes a 2nd layer, & so forth. We find this to be true even for random removals (which simulate opt-out requests). PII on the verge of memorization surfaces after others are removed.
March 2, 2025 at 7:11 PM
—extends to LLMs: removing one layer of memorized PII exposes a 2nd layer, & so forth. We find this to be true even for random removals (which simulate opt-out requests). PII on the verge of memorization surfaces after others are removed.
We find that removing extracted PII from the data & re-finetuning from scratch leads to the extraction of other PII. However, this phenomenon stops after certain iterations. Our results confirm that this layered memorization—termed the Onion Effect (Carlini et al. 2022) …
March 2, 2025 at 7:11 PM
We find that removing extracted PII from the data & re-finetuning from scratch leads to the extraction of other PII. However, this phenomenon stops after certain iterations. Our results confirm that this layered memorization—termed the Onion Effect (Carlini et al. 2022) …
We find that: 1) extraction increases substantially with the amount of PII contained in the model’s training set, & 2) inclusion of more PII leads to existing PII being at higher risk of extraction. This effect can increase extraction by over 7× in our setting.
March 2, 2025 at 7:11 PM
We find that: 1) extraction increases substantially with the amount of PII contained in the model’s training set, & 2) inclusion of more PII leads to existing PII being at higher risk of extraction. This effect can increase extraction by over 7× in our setting.
We run various tests to characterize the underlying reason for assisted memorization. We causally remove overlapping n-grams based on our methodology and find a strong correlation.
March 2, 2025 at 7:11 PM
We run various tests to characterize the underlying reason for assisted memorization. We causally remove overlapping n-grams based on our methodology and find a strong correlation.
The literature so far lacks a clear understanding of the complete memorization landscape throughout training. In this work, we provide a complete taxonomy & uncover novel forms of memorization that arise during training.
March 2, 2025 at 7:11 PM
The literature so far lacks a clear understanding of the complete memorization landscape throughout training. In this work, we provide a complete taxonomy & uncover novel forms of memorization that arise during training.