Pablo Marcos-Manchón
@jazzmaniatico.bsky.social
35 followers
62 following
9 posts
ML Engineer trying to do neuroscience
Posts
Media
Videos
Starter Packs

Reposted by Pablo Marcos-Manchón


Reposted by Pablo Marcos-Manchón

![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)
Reposted by Pablo Marcos-Manchón

Xiongbo Wu
@xiongbowu.bsky.social
· Jul 30

Reposted by Pablo Marcos-Manchón

Marta Silva
@martamasilva.bsky.social
· Jul 1
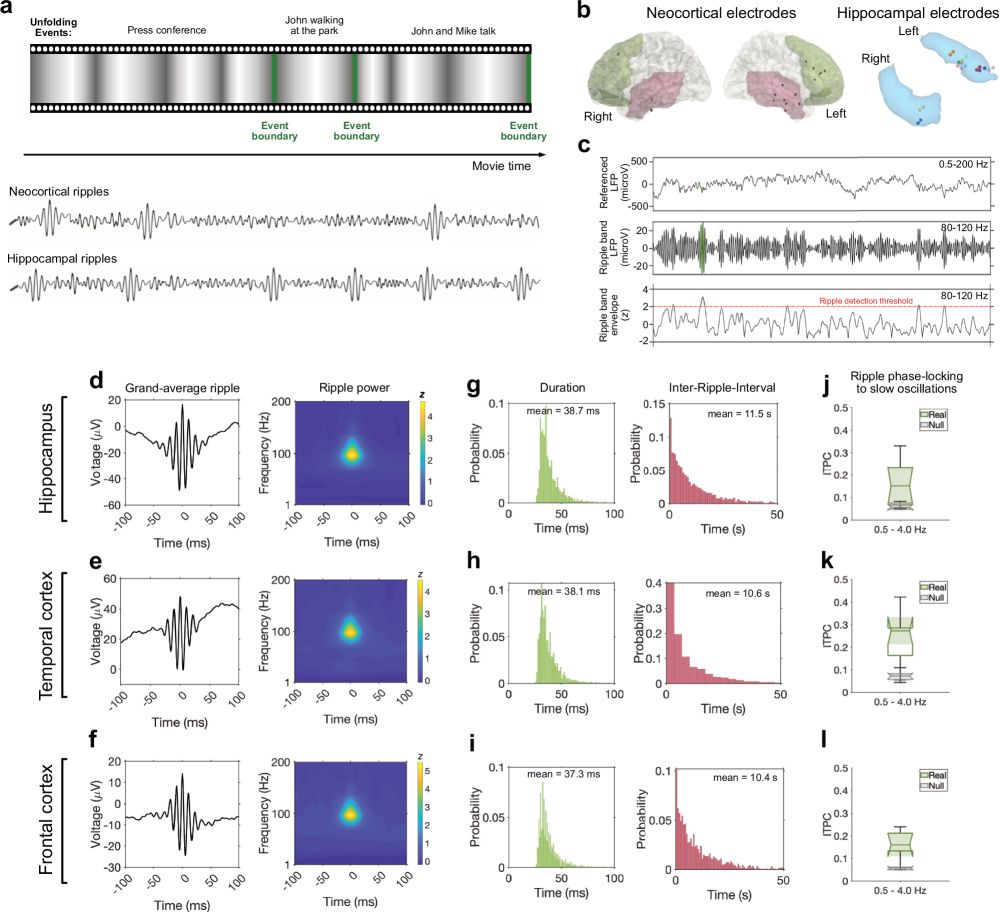
Movie-watching evokes ripple-like activity within events and at event boundaries
Nature Communications - The neural processes involved in memory formation for realistic experiences remain poorly understood. Here, the authors found that ripple-like activity in the human...
rdcu.be









Johannah Völler
@jvoeller.bsky.social
· Apr 23
Reposted by Pablo Marcos-Manchón

Marc Sabio Albert
@msabio.bsky.social
· Oct 11

Anticipating multisensory environments: Evidence for a supra-modal predictive system
Our perceptual experience is generally framed in multisensory environments abundant in predictive information. Previous research on statistical learni…
www.sciencedirect.com