




Jim RB
@jbohnslav.bsky.social
computer vision + machine learning. Perception at Zoox. Prev: Cobot, PhD. Arxiv every day.
ZEBRA-CoT
Dataset for vision-language reasoning where the model *generates images during the CoT*. Example: for geometry problems, it's helpful to draw lines in image space.
182K CoT labels: math, visual search, robot planning, and more.
Only downside: cc-by-nc license :(
Dataset for vision-language reasoning where the model *generates images during the CoT*. Example: for geometry problems, it's helpful to draw lines in image space.
182K CoT labels: math, visual search, robot planning, and more.
Only downside: cc-by-nc license :(

July 24, 2025 at 1:01 PM
ZEBRA-CoT
Dataset for vision-language reasoning where the model *generates images during the CoT*. Example: for geometry problems, it's helpful to draw lines in image space.
182K CoT labels: math, visual search, robot planning, and more.
Only downside: cc-by-nc license :(
Dataset for vision-language reasoning where the model *generates images during the CoT*. Example: for geometry problems, it's helpful to draw lines in image space.
182K CoT labels: math, visual search, robot planning, and more.
Only downside: cc-by-nc license :(
Cool technique: RASA, Removal of Absolute Spatial Attributes. They decode grid coords and find the plane in feature space that encodes position. They basically subtract this off, baking it into the last linear layer to leave the forward pass unchanged.

July 23, 2025 at 12:17 PM
Cool technique: RASA, Removal of Absolute Spatial Attributes. They decode grid coords and find the plane in feature space that encodes position. They basically subtract this off, baking it into the last linear layer to leave the forward pass unchanged.
Beats or is competitive to SigLIP/2, DinoV2 on linear eval, OOD detection, linear segmentation.

July 23, 2025 at 12:17 PM
Beats or is competitive to SigLIP/2, DinoV2 on linear eval, OOD detection, linear segmentation.
Franca
Fully open vision encoder. Masks image, encodes patches, then trains student to match teacher's clusters. Key advance: Matryoshka clustering. Each slice of the embedding gets its own projection head and clustering objective. Fewer features == fewer clusters to match.
Fully open vision encoder. Masks image, encodes patches, then trains student to match teacher's clusters. Key advance: Matryoshka clustering. Each slice of the embedding gets its own projection head and clustering objective. Fewer features == fewer clusters to match.

July 23, 2025 at 12:17 PM
Franca
Fully open vision encoder. Masks image, encodes patches, then trains student to match teacher's clusters. Key advance: Matryoshka clustering. Each slice of the embedding gets its own projection head and clustering objective. Fewer features == fewer clusters to match.
Fully open vision encoder. Masks image, encodes patches, then trains student to match teacher's clusters. Key advance: Matryoshka clustering. Each slice of the embedding gets its own projection head and clustering objective. Fewer features == fewer clusters to match.
VRU-Accident
New benchmark of 1K videos, 1K captions, and 6K MCQs from accidents involving VRUs. Example: "why did the accident happen?" "(B): pedestrian moves or stays on the road."
Current VLMs get ~50-65% accuracy, much worse than humans (95%).
New benchmark of 1K videos, 1K captions, and 6K MCQs from accidents involving VRUs. Example: "why did the accident happen?" "(B): pedestrian moves or stays on the road."
Current VLMs get ~50-65% accuracy, much worse than humans (95%).

July 15, 2025 at 3:13 PM
VRU-Accident
New benchmark of 1K videos, 1K captions, and 6K MCQs from accidents involving VRUs. Example: "why did the accident happen?" "(B): pedestrian moves or stays on the road."
Current VLMs get ~50-65% accuracy, much worse than humans (95%).
New benchmark of 1K videos, 1K captions, and 6K MCQs from accidents involving VRUs. Example: "why did the accident happen?" "(B): pedestrian moves or stays on the road."
Current VLMs get ~50-65% accuracy, much worse than humans (95%).
Side note: I've always liked Pali/Gemma's Prefix-LM masking. Why have causal attention for image tokens?


July 15, 2025 at 1:56 PM
Side note: I've always liked Pali/Gemma's Prefix-LM masking. Why have causal attention for image tokens?
BlindSight
AMD paper: they find attention heads often have stereotyped sparsity patterns (e.g. only attending within an image, not across). They generate sparse attention variants for each prompt. Theoretically saves ~35% FLOPs for 1-2% worse on benches.
AMD paper: they find attention heads often have stereotyped sparsity patterns (e.g. only attending within an image, not across). They generate sparse attention variants for each prompt. Theoretically saves ~35% FLOPs for 1-2% worse on benches.

July 15, 2025 at 1:56 PM
BlindSight
AMD paper: they find attention heads often have stereotyped sparsity patterns (e.g. only attending within an image, not across). They generate sparse attention variants for each prompt. Theoretically saves ~35% FLOPs for 1-2% worse on benches.
AMD paper: they find attention heads often have stereotyped sparsity patterns (e.g. only attending within an image, not across). They generate sparse attention variants for each prompt. Theoretically saves ~35% FLOPs for 1-2% worse on benches.
Long-RL
Nvidia paper scaling RL to long videos. First trains with SFT on a synthetic long CoT dataset, then does GRPO with up to 512 video frames. Uses cached image embeddings + sequence parallelism, speeding up rollouts >2X.
Bonus: code is already up!
Nvidia paper scaling RL to long videos. First trains with SFT on a synthetic long CoT dataset, then does GRPO with up to 512 video frames. Uses cached image embeddings + sequence parallelism, speeding up rollouts >2X.
Bonus: code is already up!

July 11, 2025 at 1:18 PM
Long-RL
Nvidia paper scaling RL to long videos. First trains with SFT on a synthetic long CoT dataset, then does GRPO with up to 512 video frames. Uses cached image embeddings + sequence parallelism, speeding up rollouts >2X.
Bonus: code is already up!
Nvidia paper scaling RL to long videos. First trains with SFT on a synthetic long CoT dataset, then does GRPO with up to 512 video frames. Uses cached image embeddings + sequence parallelism, speeding up rollouts >2X.
Bonus: code is already up!
They identify entropy of "wait" or "alternatively" to be strongly correlated with MMMU. Neat!

July 9, 2025 at 3:41 PM
They identify entropy of "wait" or "alternatively" to be strongly correlated with MMMU. Neat!
Fine-tuning the connector at the end gives a point or two of MMMU. I wonder how much of this is benchmaxxing--I haven't seen an additional SFT stage after RL before.

July 9, 2025 at 3:41 PM
Fine-tuning the connector at the end gives a point or two of MMMU. I wonder how much of this is benchmaxxing--I haven't seen an additional SFT stage after RL before.
They construct their warm-start SFT data with synthetic traces from Skywork-R1V2.
GRPO is pretty standard, interesting that they just did math instead of math, grounding, other possible RLVR tasks. Qwen-2.5-Instruct 32B to judges the accuracy of the answer in addition to rule-based verification.
GRPO is pretty standard, interesting that they just did math instead of math, grounding, other possible RLVR tasks. Qwen-2.5-Instruct 32B to judges the accuracy of the answer in addition to rule-based verification.

July 9, 2025 at 3:41 PM
They construct their warm-start SFT data with synthetic traces from Skywork-R1V2.
GRPO is pretty standard, interesting that they just did math instead of math, grounding, other possible RLVR tasks. Qwen-2.5-Instruct 32B to judges the accuracy of the answer in addition to rule-based verification.
GRPO is pretty standard, interesting that they just did math instead of math, grounding, other possible RLVR tasks. Qwen-2.5-Instruct 32B to judges the accuracy of the answer in addition to rule-based verification.
Skywork-R1V3: new reasoning VLM with 76% MMMU.
InternViT-6B stitched with QwQ-32B. SFT warmup, GRPO on math, then a small SFT fine-tune at the end.
Good benches, actual ablations, and interesting discussion.
Details: 🧵
InternViT-6B stitched with QwQ-32B. SFT warmup, GRPO on math, then a small SFT fine-tune at the end.
Good benches, actual ablations, and interesting discussion.
Details: 🧵

July 9, 2025 at 3:41 PM
Skywork-R1V3: new reasoning VLM with 76% MMMU.
InternViT-6B stitched with QwQ-32B. SFT warmup, GRPO on math, then a small SFT fine-tune at the end.
Good benches, actual ablations, and interesting discussion.
Details: 🧵
InternViT-6B stitched with QwQ-32B. SFT warmup, GRPO on math, then a small SFT fine-tune at the end.
Good benches, actual ablations, and interesting discussion.
Details: 🧵
Training: use verl with vLLM for rollouts. Limit image resolution to 1280 visual tokens. Train on 32 H100s.
Results: +18 points better on V* compared to Qwen2.5-VL, and +5 points better than GRPO alone.
Results: +18 points better on V* compared to Qwen2.5-VL, and +5 points better than GRPO alone.

July 9, 2025 at 3:24 PM
Training: use verl with vLLM for rollouts. Limit image resolution to 1280 visual tokens. Train on 32 H100s.
Results: +18 points better on V* compared to Qwen2.5-VL, and +5 points better than GRPO alone.
Results: +18 points better on V* compared to Qwen2.5-VL, and +5 points better than GRPO alone.
RL: GRPO. Reward: only correct answer, not valid grounding coordinates. Seems weird to not add that though.
Data: training subset of MME-RealWorld. Evaluate on V*.
Data: training subset of MME-RealWorld. Evaluate on V*.

July 9, 2025 at 3:24 PM
RL: GRPO. Reward: only correct answer, not valid grounding coordinates. Seems weird to not add that though.
Data: training subset of MME-RealWorld. Evaluate on V*.
Data: training subset of MME-RealWorld. Evaluate on V*.
MGPO: multi-turn grounding-based policy optimization.
I've been waiting for a paper like this! Trains the LLM to iteratively crop regions of interest to answer a question, and the only reward is the final answer.
Details in thread 👇
I've been waiting for a paper like this! Trains the LLM to iteratively crop regions of interest to answer a question, and the only reward is the final answer.
Details in thread 👇

July 9, 2025 at 3:24 PM
MGPO: multi-turn grounding-based policy optimization.
I've been waiting for a paper like this! Trains the LLM to iteratively crop regions of interest to answer a question, and the only reward is the final answer.
Details in thread 👇
I've been waiting for a paper like this! Trains the LLM to iteratively crop regions of interest to answer a question, and the only reward is the final answer.
Details in thread 👇
Using automatically generated risk category labels and the front-facing view, they have GPT4o caption the scenarios. The metrics are based on caption similarity + classification metrics on riskiness-type.

July 8, 2025 at 2:03 PM
Using automatically generated risk category labels and the front-facing view, they have GPT4o caption the scenarios. The metrics are based on caption similarity + classification metrics on riskiness-type.
DriveMRP: interesting method to get a VLM to understand BEV maps + driving scenarios
They synthesize high-risk scenes derived from NuPlan. They render it as both a bird's eye view image and a front camera view.
👇
They synthesize high-risk scenes derived from NuPlan. They render it as both a bird's eye view image and a front camera view.
👇

July 8, 2025 at 2:03 PM
DriveMRP: interesting method to get a VLM to understand BEV maps + driving scenarios
They synthesize high-risk scenes derived from NuPlan. They render it as both a bird's eye view image and a front camera view.
👇
They synthesize high-risk scenes derived from NuPlan. They render it as both a bird's eye view image and a front camera view.
👇
SeqGrowGraph
Instead of segment + postprocess, generate lane graphs autoregressively. Node == vertex in BEV space, edge == control point for Bezier curves. At each step, a vertex is added and the adjacency matrix adds one row + column.
They formulate this process as next token prediction. Neat!
Instead of segment + postprocess, generate lane graphs autoregressively. Node == vertex in BEV space, edge == control point for Bezier curves. At each step, a vertex is added and the adjacency matrix adds one row + column.
They formulate this process as next token prediction. Neat!

July 8, 2025 at 1:51 PM
SeqGrowGraph
Instead of segment + postprocess, generate lane graphs autoregressively. Node == vertex in BEV space, edge == control point for Bezier curves. At each step, a vertex is added and the adjacency matrix adds one row + column.
They formulate this process as next token prediction. Neat!
Instead of segment + postprocess, generate lane graphs autoregressively. Node == vertex in BEV space, edge == control point for Bezier curves. At each step, a vertex is added and the adjacency matrix adds one row + column.
They formulate this process as next token prediction. Neat!
Excitingly, in one of their few shown results, multi-domain RL shows positive cross-task-transfer. Training on GUI agent data improves STEM answers, OCR, and grounding.

July 2, 2025 at 1:57 PM
Excitingly, in one of their few shown results, multi-domain RL shows positive cross-task-transfer. Training on GUI agent data improves STEM answers, OCR, and grounding.
They use a ton of specialized verifiers, judges, and reward models for RL.

July 2, 2025 at 1:57 PM
They use a ton of specialized verifiers, judges, and reward models for RL.
RL: both RLHF and RLVR with GRPO. They use humans and pass@k from prior checkpoints to judge difficulty.
When training with many RL tasks, they found weakness in any one task leads to model collapse for all tasks: "effective RL demands finely tuned, hack-resistant verifiers in every domain"
When training with many RL tasks, they found weakness in any one task leads to model collapse for all tasks: "effective RL demands finely tuned, hack-resistant verifiers in every domain"

July 2, 2025 at 1:57 PM
RL: both RLHF and RLVR with GRPO. They use humans and pass@k from prior checkpoints to judge difficulty.
When training with many RL tasks, they found weakness in any one task leads to model collapse for all tasks: "effective RL demands finely tuned, hack-resistant verifiers in every domain"
When training with many RL tasks, they found weakness in any one task leads to model collapse for all tasks: "effective RL demands finely tuned, hack-resistant verifiers in every domain"
Pretraining recipe: stage 1, train all parameters for 120K steps at 8192 sequence length. Stage 2, interleaved + video data at 32K sequence length with tensor parallelism + context parallelism.

July 2, 2025 at 1:57 PM
Pretraining recipe: stage 1, train all parameters for 120K steps at 8192 sequence length. Stage 2, interleaved + video data at 32K sequence length with tensor parallelism + context parallelism.
Pretraining data 📚📷
* Captioning: 10B image-text pairs from the web
* Interleaved data: websites, papers, and 100 million digitized books
* OCR: 220 million images
* Grounding: use GLIPv2 for images, playwright for GUIs
* Video: "academic, web, and proprietary sources"
* Instruction: 50M samples
* Captioning: 10B image-text pairs from the web
* Interleaved data: websites, papers, and 100 million digitized books
* OCR: 220 million images
* Grounding: use GLIPv2 for images, playwright for GUIs
* Video: "academic, web, and proprietary sources"
* Instruction: 50M samples

July 2, 2025 at 1:57 PM
Pretraining data 📚📷
* Captioning: 10B image-text pairs from the web
* Interleaved data: websites, papers, and 100 million digitized books
* OCR: 220 million images
* Grounding: use GLIPv2 for images, playwright for GUIs
* Video: "academic, web, and proprietary sources"
* Instruction: 50M samples
* Captioning: 10B image-text pairs from the web
* Interleaved data: websites, papers, and 100 million digitized books
* OCR: 220 million images
* Grounding: use GLIPv2 for images, playwright for GUIs
* Video: "academic, web, and proprietary sources"
* Instruction: 50M samples
Model details: Uses AIMv2 as the vision encoder and GLM for the LLM, both unique choices. They add 3D convs to the vision encoder to downsample videos by 2X like Qwen 2-VL.
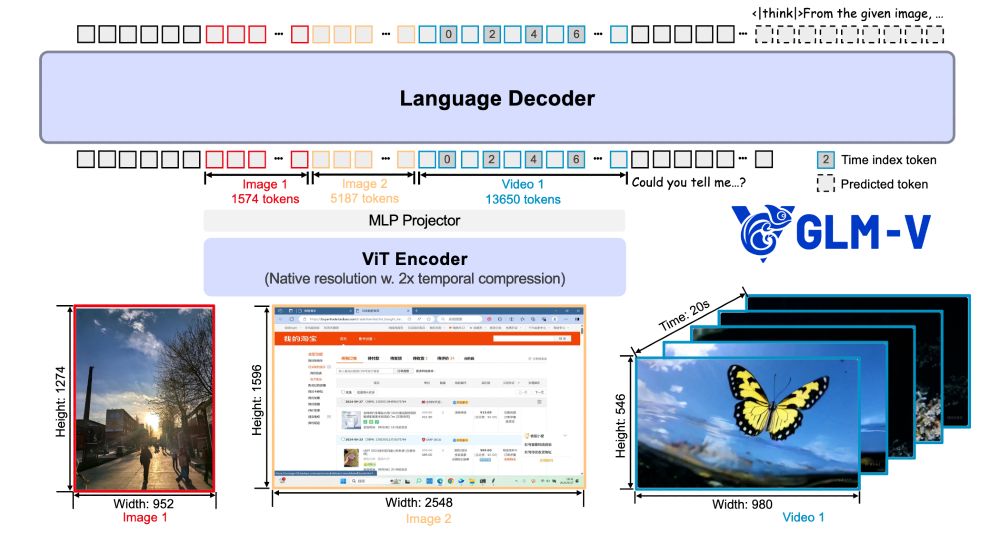
July 2, 2025 at 1:57 PM
Model details: Uses AIMv2 as the vision encoder and GLM for the LLM, both unique choices. They add 3D convs to the vision encoder to downsample videos by 2X like Qwen 2-VL.
GLM-4.1V-Thinking: new reasoning VLM with heavy emphasis on RL.
Tons of hints but few ablations 😞 eg they upweight difficult-but-learnable samples every iteration, but don't show how it compares to baseline.
9B variant beats Qwen2.5-VL-7B on many standard benchmarks.
Details in thread 👇
Tons of hints but few ablations 😞 eg they upweight difficult-but-learnable samples every iteration, but don't show how it compares to baseline.
9B variant beats Qwen2.5-VL-7B on many standard benchmarks.
Details in thread 👇

July 2, 2025 at 1:57 PM
GLM-4.1V-Thinking: new reasoning VLM with heavy emphasis on RL.
Tons of hints but few ablations 😞 eg they upweight difficult-but-learnable samples every iteration, but don't show how it compares to baseline.
9B variant beats Qwen2.5-VL-7B on many standard benchmarks.
Details in thread 👇
Tons of hints but few ablations 😞 eg they upweight difficult-but-learnable samples every iteration, but don't show how it compares to baseline.
9B variant beats Qwen2.5-VL-7B on many standard benchmarks.
Details in thread 👇