Jirui Qi
@jiruiqi.bsky.social
82 followers
59 following
31 posts
Ph.D Candidate @GroNLP, University of Groningen #NLProc
https://betswish.github.io
Posts
Media
Videos
Starter Packs
Pinned


Jirui Qi
@jiruiqi.bsky.social
· Aug 20
Reposted by Jirui Qi


Reposted by Jirui Qi

Francesca Padovani
@frap98.bsky.social
· May 30

Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of ...
arxiv.org

Jirui Qi
@jiruiqi.bsky.social
· May 30





Jirui Qi
@jiruiqi.bsky.social
· May 30
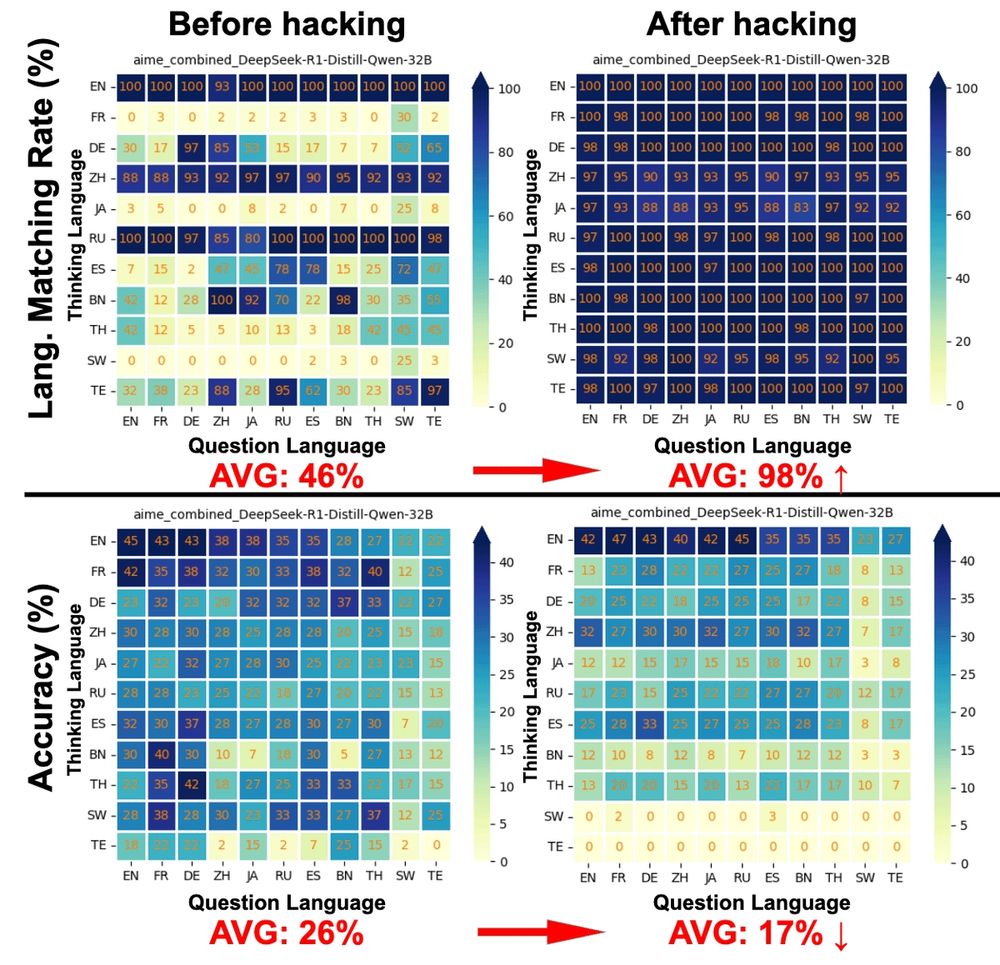





Jirui Qi
@jiruiqi.bsky.social
· Apr 11


Jirui Qi
@jiruiqi.bsky.social
· Apr 11



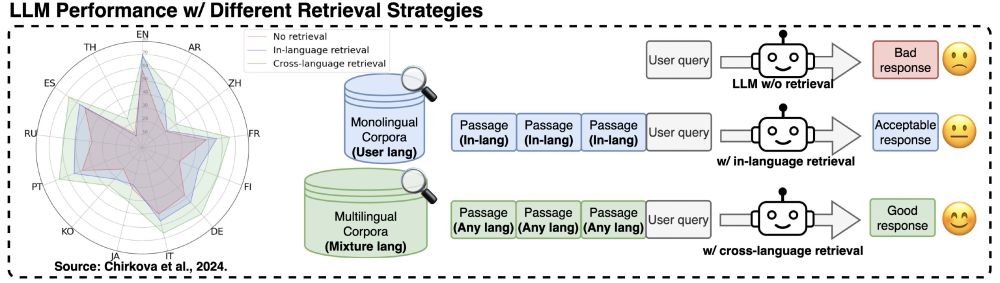

Jirui Qi
@jiruiqi.bsky.social
· Jan 24
Jirui Qi
@jiruiqi.bsky.social
· Jan 24