
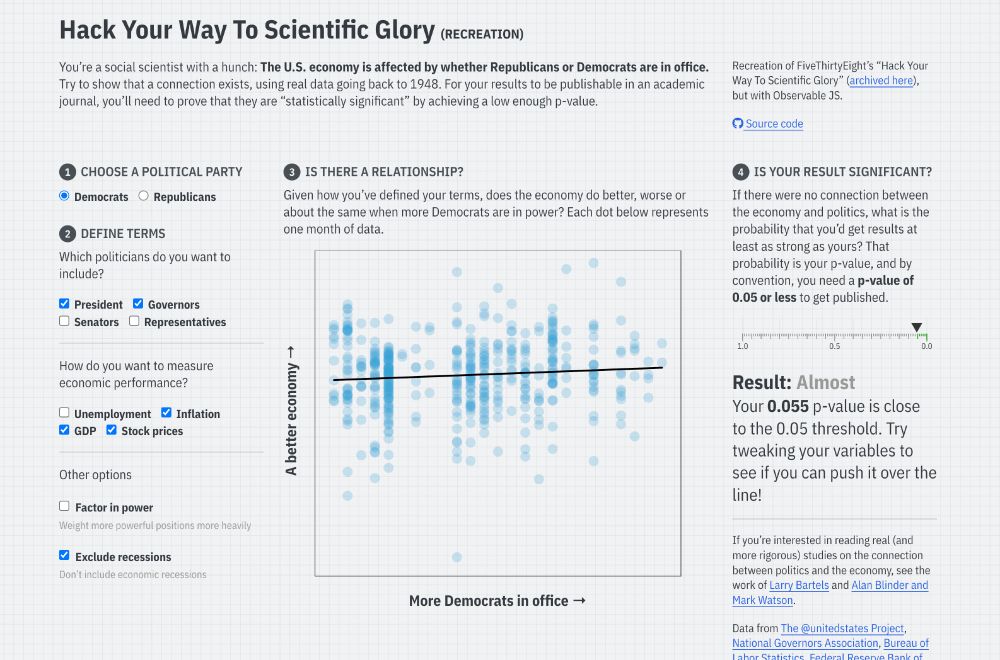
Joe Ornstein
@joeornstein.bsky.social
93 followers
42 following
8 posts
Political Science @ UGA
https://joeornstein.github.io/
Posts
Media
Videos
Starter Packs


Reposted by Joe Ornstein

Reposted by Joe Ornstein




Joe Ornstein
@joeornstein.bsky.social
· Jan 14

promptr: Format and Complete Few-Shot LLM Prompts
Format and submit few-shot prompts to OpenAI's Large Language Models (LLMs). Designed to be particularly useful for text classification problems in the social sciences. Methods are described in Ornste...
cran.r-project.org
Joe Ornstein
@joeornstein.bsky.social
· Jan 14
Joe Ornstein
@joeornstein.bsky.social
· Jan 14
Joe Ornstein
@joeornstein.bsky.social
· Jan 14
Joe Ornstein
@joeornstein.bsky.social
· Jan 14


Reposted by Joe Ornstein

Reposted by Joe Ornstein


Joe Ornstein
@joeornstein.bsky.social
· Sep 21