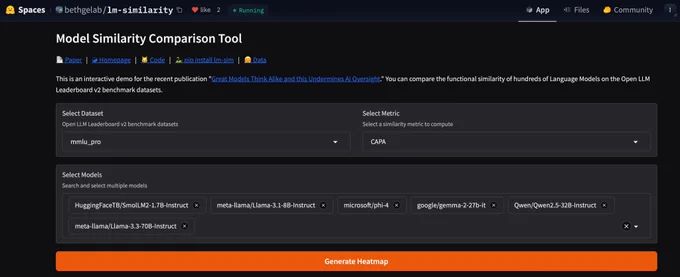
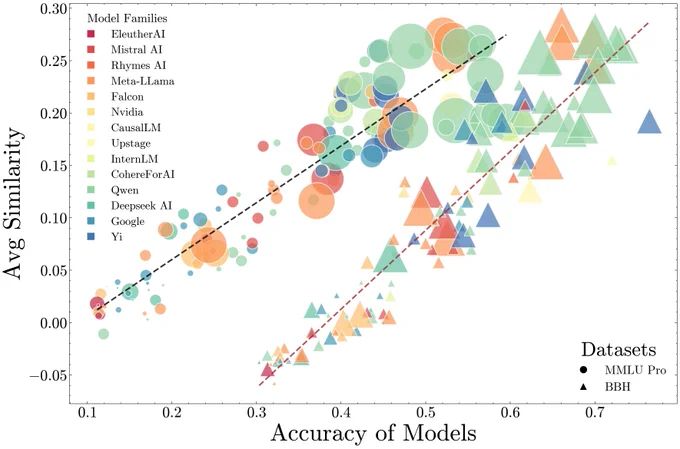
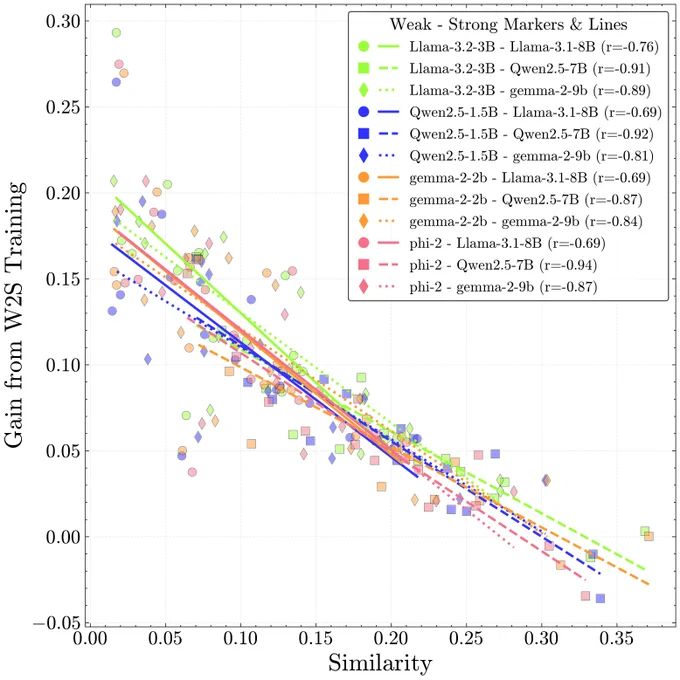
Joschka Strüber @ICML2025 🇨🇦
@joschkastrueber.bsky.social
77 followers
320 following
9 posts
PhD student at the University of Tübingen, member of @bethgelab.bsky.social
Posts
Media
Videos
Starter Packs
Pinned
Reposted by Joschka Strüber @ICML2025 🇨🇦


Reposted by Joschka Strüber @ICML2025 🇨🇦


Reposted by Joschka Strüber @ICML2025 🇨🇦

Reposted by Joschka Strüber @ICML2025 🇨🇦

Reposted by Joschka Strüber @ICML2025 🇨🇦