



Josh McDermott
@joshhmcdermott.bsky.social
Working to understand how humans and machines hear. Prof at MIT; director of Lab for Computational Audition. https://mcdermottlab.mit.edu/
82. A model of continuous speech recognition reveals the role of context in human speech perception - Gasser Elbanna
96. Machine learning models of hearing demonstrate the limits of attentional selection of speech heard through cochlear implants - Annesya Banerjee
96. Machine learning models of hearing demonstrate the limits of attentional selection of speech heard through cochlear implants - Annesya Banerjee
November 14, 2025 at 3:27 PM
82. A model of continuous speech recognition reveals the role of context in human speech perception - Gasser Elbanna
96. Machine learning models of hearing demonstrate the limits of attentional selection of speech heard through cochlear implants - Annesya Banerjee
96. Machine learning models of hearing demonstrate the limits of attentional selection of speech heard through cochlear implants - Annesya Banerjee
58. Optimized models of uncertainty explain human confidence in auditory perception - Lakshmi Govindarajan
64. Source-location binding errors in auditory scene perception - Sagarika Alavilli
64. Source-location binding errors in auditory scene perception - Sagarika Alavilli
November 14, 2025 at 3:27 PM
58. Optimized models of uncertainty explain human confidence in auditory perception - Lakshmi Govindarajan
64. Source-location binding errors in auditory scene perception - Sagarika Alavilli
64. Source-location binding errors in auditory scene perception - Sagarika Alavilli
Lakshmi happens to be on the job market right now, so I will end by recommending that everyone try to hire him. He is a wonderful colleague, and I expect he will do many other important things. (end)
November 9, 2025 at 9:34 PM
Lakshmi happens to be on the job market right now, so I will end by recommending that everyone try to hire him. He is a wonderful colleague, and I expect he will do many other important things. (end)
Added bonus: expressing stimulus-dependent uncertainty enables models that perform regression (i.e., yielding continuous valued outputs), which has previously not worked very well. (15/n)
November 9, 2025 at 9:34 PM
Added bonus: expressing stimulus-dependent uncertainty enables models that perform regression (i.e., yielding continuous valued outputs), which has previously not worked very well. (15/n)
Lots more in the paper. The approach is applicable to any perceptual estimation problem. We hope it will enable the study of confidence to be extended to more realistic conditions, via models that can operate on images or sounds. (14/n)
November 9, 2025 at 9:34 PM
Lots more in the paper. The approach is applicable to any perceptual estimation problem. We hope it will enable the study of confidence to be extended to more realistic conditions, via models that can operate on images or sounds. (14/n)
He measured human confidence for pitch, and found that confidence was higher for conditions with lower discrimination thresholds. The model reproduced this general trend. (13/n)

November 9, 2025 at 9:34 PM
He measured human confidence for pitch, and found that confidence was higher for conditions with lower discrimination thresholds. The model reproduced this general trend. (13/n)
Lakshmi used the same framework to build models of pitch perception that represent uncertainty. The models generate a distribution over fundamental frequency. (12/n)

November 9, 2025 at 9:34 PM
Lakshmi used the same framework to build models of pitch perception that represent uncertainty. The models generate a distribution over fundamental frequency. (12/n)
By contrast, simulating bets using the softmax distribution of a standard classification-based neural network does not yield human-like confidence, presumably because the distribution is not incentivized to have correct uncertainty. (11/n)

November 9, 2025 at 9:34 PM
By contrast, simulating bets using the softmax distribution of a standard classification-based neural network does not yield human-like confidence, presumably because the distribution is not incentivized to have correct uncertainty. (11/n)
The model can also be used to select natural sounds whose localization is certain or uncertain. When presented to humans, humans place higher bets on the sounds with low model uncertainty, and vice versa. (10/n)

November 9, 2025 at 9:34 PM
The model can also be used to select natural sounds whose localization is certain or uncertain. When presented to humans, humans place higher bets on the sounds with low model uncertainty, and vice versa. (10/n)
The model replicates patterns of localization accuracy (like previous models) but also replicates the dependence of confidence on conditions. Here confidence is lower for sounds with narrower spectra, and at peripheral locations: (9/n)

November 9, 2025 at 9:34 PM
The model replicates patterns of localization accuracy (like previous models) but also replicates the dependence of confidence on conditions. Here confidence is lower for sounds with narrower spectra, and at peripheral locations: (9/n)
To simulate betting behavior from the model, he mapped a measure of the model posterior spread to a bet (in cents). (8/n)

November 9, 2025 at 9:34 PM
To simulate betting behavior from the model, he mapped a measure of the model posterior spread to a bet (in cents). (8/n)
Lakshmi then tested whether the model’s uncertainty was predictive of human confidence judgments. He ran experiments in which people localized sounds and then placed bets on their localization judgment: (7/n)

November 9, 2025 at 9:34 PM
Lakshmi then tested whether the model’s uncertainty was predictive of human confidence judgments. He ran experiments in which people localized sounds and then placed bets on their localization judgment: (7/n)
The model was trained on spatial renderings of lots of natural sounds in lots of different rooms. Once trained, it produces narrow posteriors for some sounds, and broad posteriors for others: (6/n)

November 9, 2025 at 9:34 PM
The model was trained on spatial renderings of lots of natural sounds in lots of different rooms. Once trained, it produces narrow posteriors for some sounds, and broad posteriors for others: (6/n)
He first applied this idea to sound localization. The model takes binaural audio as input and estimates parameters of a mixture distribution over a sphere. Distributions can be narrow, broad, or multi-modal, depending on the stimulus. (5/n)

November 9, 2025 at 9:34 PM
He first applied this idea to sound localization. The model takes binaural audio as input and estimates parameters of a mixture distribution over a sphere. Distributions can be narrow, broad, or multi-modal, depending on the stimulus. (5/n)
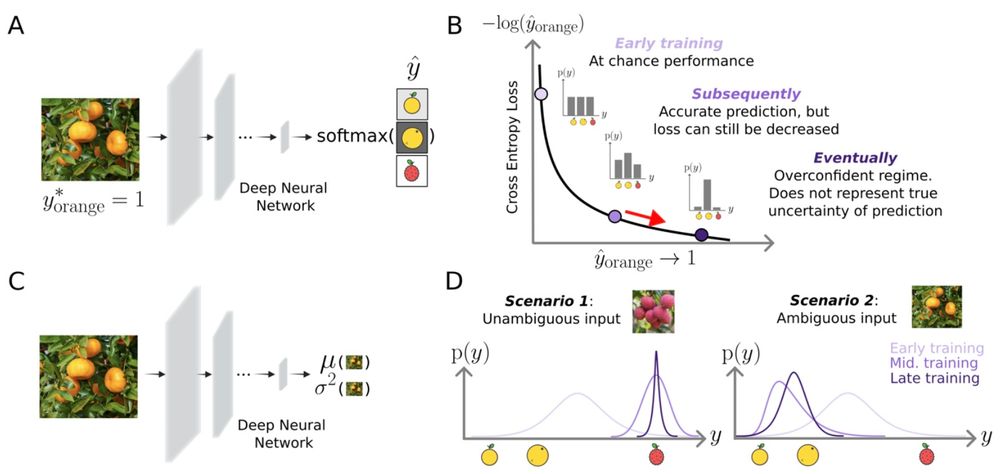
Lakshmi realized that models could be trained to output parameters of distributions, and that by optimizing models with a log-likelihood loss function, the model is incentivized to correctly represent uncertainty. (4/n)
November 9, 2025 at 9:34 PM
Lakshmi realized that models could be trained to output parameters of distributions, and that by optimizing models with a log-likelihood loss function, the model is incentivized to correctly represent uncertainty. (4/n)
Standard neural networks are not suitable for several reasons, including because cross-entropy loss is known to induce over-confidence. (3/n)
November 9, 2025 at 9:34 PM
Standard neural networks are not suitable for several reasons, including because cross-entropy loss is known to induce over-confidence. (3/n)
Uncertainty is inevitable in perception. It seems like it would be useful for people to explicitly represent it. But it has been hard to study in realistic conditions, as we haven’t had stimulus-computable models. (2/n)
November 9, 2025 at 9:34 PM
Uncertainty is inevitable in perception. It seems like it would be useful for people to explicitly represent it. But it has been hard to study in realistic conditions, as we haven’t had stimulus-computable models. (2/n)