



@jpoberhauser.bsky.social
Computer vision | multi modal learning | machine learning
Pinned

GitHub - jpoberhauser/multi-object-trackers-collection: Keeping up with multi-object trackers
Keeping up with multi-object trackers. Contribute to jpoberhauser/multi-object-trackers-collection development by creating an account on GitHub.
github.com
I cleaned up my literature review on multi object trackers and Reid/representation learning. Check it out here and let me know if anything is missing: github.com/jpoberhauser...
Digging into a new tracker paper: arxiv.org/abs/2411.16466. Motion through detection for people tracking

No Identity, no problem: Motion through detection for people tracking
Tracking-by-detection has become the de facto standard approach to people tracking. To increase robustness, some approaches incorporate re-identification using appearance models and regressing motion ...
arxiv.org
November 29, 2024 at 9:56 PM
Digging into a new tracker paper: arxiv.org/abs/2411.16466. Motion through detection for people tracking
Ok we have been exploring masked autoencoders for video lately. But let’s go back to basics and revisit the MAE are scalable vision learners to really understand this technique and why it has gathered so much attention in the vision world (apart from VLMs)
November 26, 2024 at 4:24 PM
Ok we have been exploring masked autoencoders for video lately. But let’s go back to basics and revisit the MAE are scalable vision learners to really understand this technique and why it has gathered so much attention in the vision world (apart from VLMs)
and for (arxiv.org/pdf/2411.05222) RLT:
- RLT significantly reduces fine-tuning time (up to 40%) without compromising accuracy
- RLT shows greater token reduction on datasets with higher frames per second (FPS)
...
- RLT significantly reduces fine-tuning time (up to 40%) without compromising accuracy
- RLT shows greater token reduction on datasets with higher frames per second (FPS)
...
arxiv.org
November 25, 2024 at 2:08 PM
and for (arxiv.org/pdf/2411.05222) RLT:
- RLT significantly reduces fine-tuning time (up to 40%) without compromising accuracy
- RLT shows greater token reduction on datasets with higher frames per second (FPS)
...
- RLT significantly reduces fine-tuning time (up to 40%) without compromising accuracy
- RLT shows greater token reduction on datasets with higher frames per second (FPS)
...
so basically, for LVMAE (arxiv.org/pdf/2411.136... Informative masking significantly outperforms random and uniform masking strategies.
.
.
arxiv.org
November 25, 2024 at 2:07 PM
so basically, for LVMAE (arxiv.org/pdf/2411.136... Informative masking significantly outperforms random and uniform masking strategies.
.
.
Today we do a deep dive into video MAE (Masked Auto Encoders) introduced here : arxiv.org/pdf/2203.12602 with huggingface space here: huggingface.co/docs/transfo...
arxiv.org
November 25, 2024 at 1:57 PM
Today we do a deep dive into video MAE (Masked Auto Encoders) introduced here : arxiv.org/pdf/2203.12602 with huggingface space here: huggingface.co/docs/transfo...
Reposted

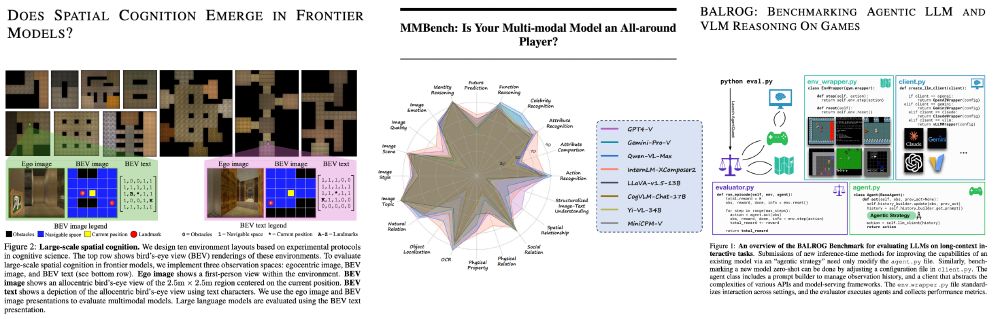
There are now several benchmarks testing spatial reasoning and agent capabilities of LLMs and VLMs:
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
November 24, 2024 at 5:19 PM
There are now several benchmarks testing spatial reasoning and agent capabilities of LLMs and VLMs:
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
Continuing with: arxiv.org/abs/2203.12602. Loss is simply MSE between normalized masked tokens and the reconstructed ones in pixel space.
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (...
arxiv.org
November 24, 2024 at 5:14 PM
Continuing with: arxiv.org/abs/2203.12602. Loss is simply MSE between normalized masked tokens and the reconstructed ones in pixel space.
Weekend read: arxiv.org/abs/2203.12602
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (...
arxiv.org
November 23, 2024 at 4:44 PM
Weekend read: arxiv.org/abs/2203.12602
One of my favorites is GHOST: github.com/dvl-tum/GHOST
It shows that good old fashioned appearance and motion cues are enough for a SOTA tracker (if done right)
It shows that good old fashioned appearance and motion cues are enough for a SOTA tracker (if done right)

GitHub - dvl-tum/GHOST: Repository for GHOST: Simple Cues Lead to a Strong Multi-Object Tracker (CVPR 2023)
Repository for GHOST: Simple Cues Lead to a Strong Multi-Object Tracker (CVPR 2023) - dvl-tum/GHOST
github.com
November 22, 2024 at 10:34 PM
One of my favorites is GHOST: github.com/dvl-tum/GHOST
It shows that good old fashioned appearance and motion cues are enough for a SOTA tracker (if done right)
It shows that good old fashioned appearance and motion cues are enough for a SOTA tracker (if done right)
I cleaned up my literature review on multi object trackers and Reid/representation learning. Check it out here and let me know if anything is missing: github.com/jpoberhauser...
GitHub - jpoberhauser/multi-object-trackers-collection: Keeping up with multi-object trackers
Keeping up with multi-object trackers. Contribute to jpoberhauser/multi-object-trackers-collection development by creating an account on GitHub.
github.com
November 22, 2024 at 10:32 PM
I cleaned up my literature review on multi object trackers and Reid/representation learning. Check it out here and let me know if anything is missing: github.com/jpoberhauser...