Kenneth Marino
@kennethmarino.bsky.social
2.9K followers
740 following
75 posts
Assistant Prof at University of Utah Fall 2025. NLP+CV+RL. RS at Google DeepMind. PhD from CMU MLD, undergrad Georgia Tech. Sometimes researcher, frequent shitposter.
Posts
Media
Videos
Starter Packs

Kenneth Marino
@kennethmarino.bsky.social
· Aug 29





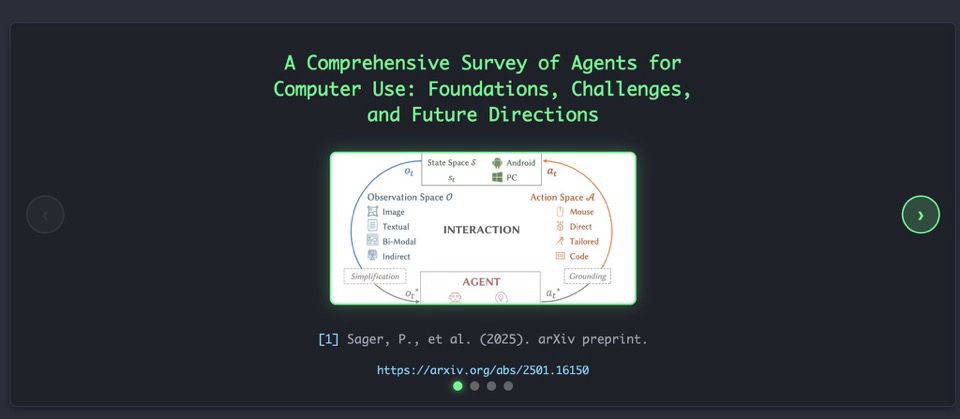

Reposted by Kenneth Marino


Kenneth Marino
@kennethmarino.bsky.social
· Jul 16


Reposted by Kenneth Marino


Reposted by Kenneth Marino
Kenneth Marino
@kennethmarino.bsky.social
· May 16


Kenneth Marino
@kennethmarino.bsky.social
· May 15
Kenneth Marino
@kennethmarino.bsky.social
· Mar 18

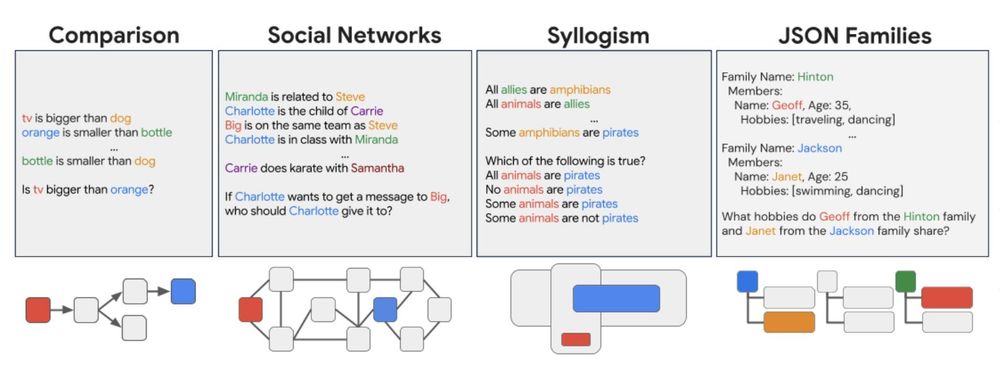
Kenneth Marino
@kennethmarino.bsky.social
· Feb 19
Kenneth Marino
@kennethmarino.bsky.social
· Feb 19
Kenneth Marino
@kennethmarino.bsky.social
· Feb 19
Kenneth Marino
@kennethmarino.bsky.social
· Jan 20
Kenneth Marino
@kennethmarino.bsky.social
· Jan 19

