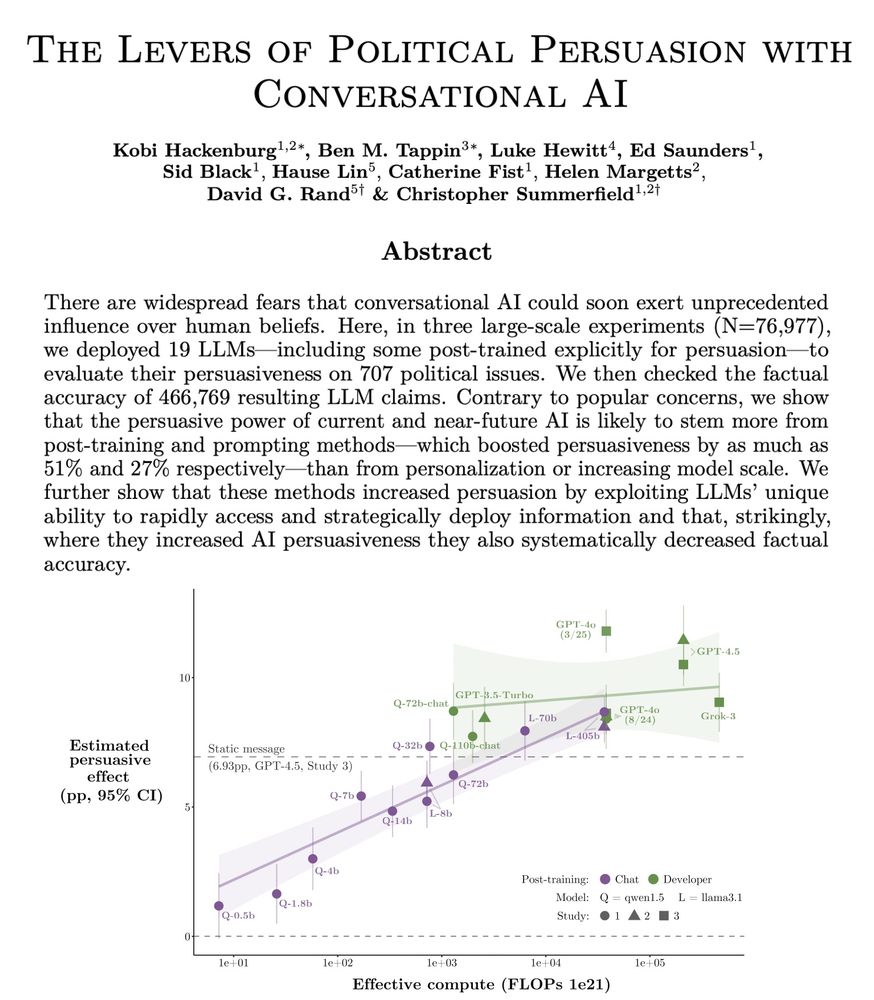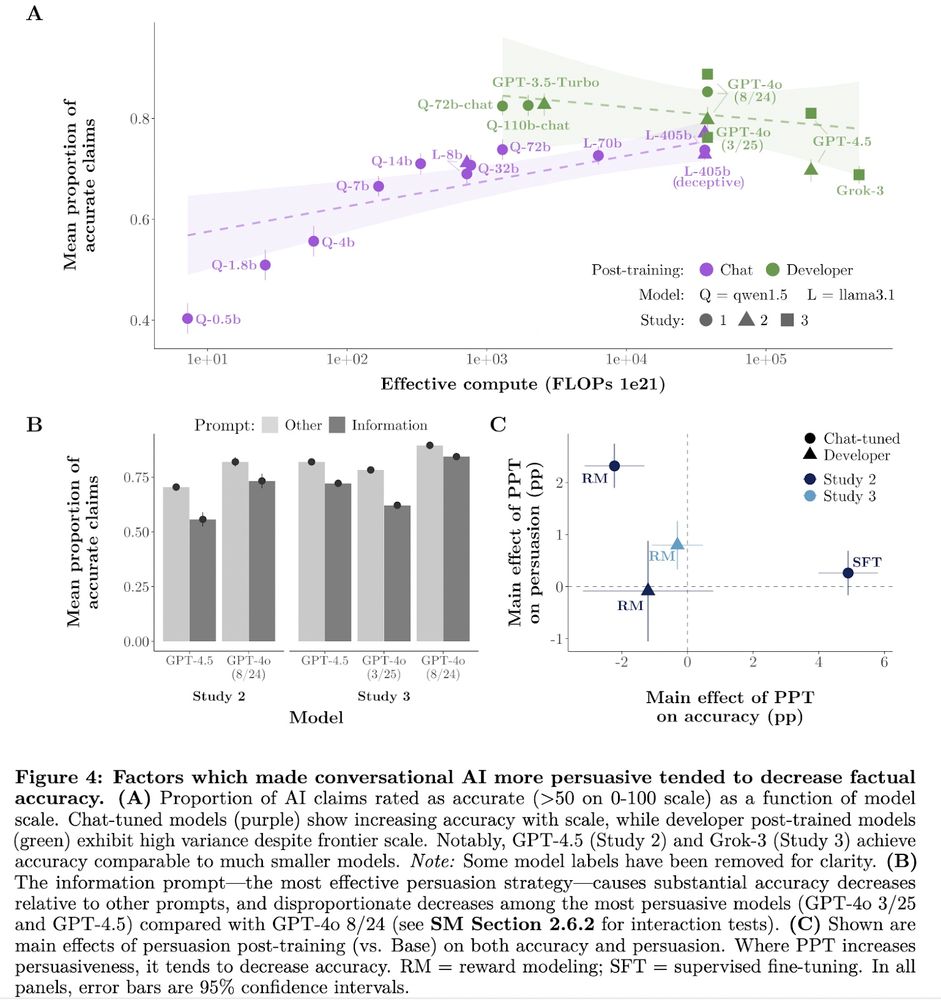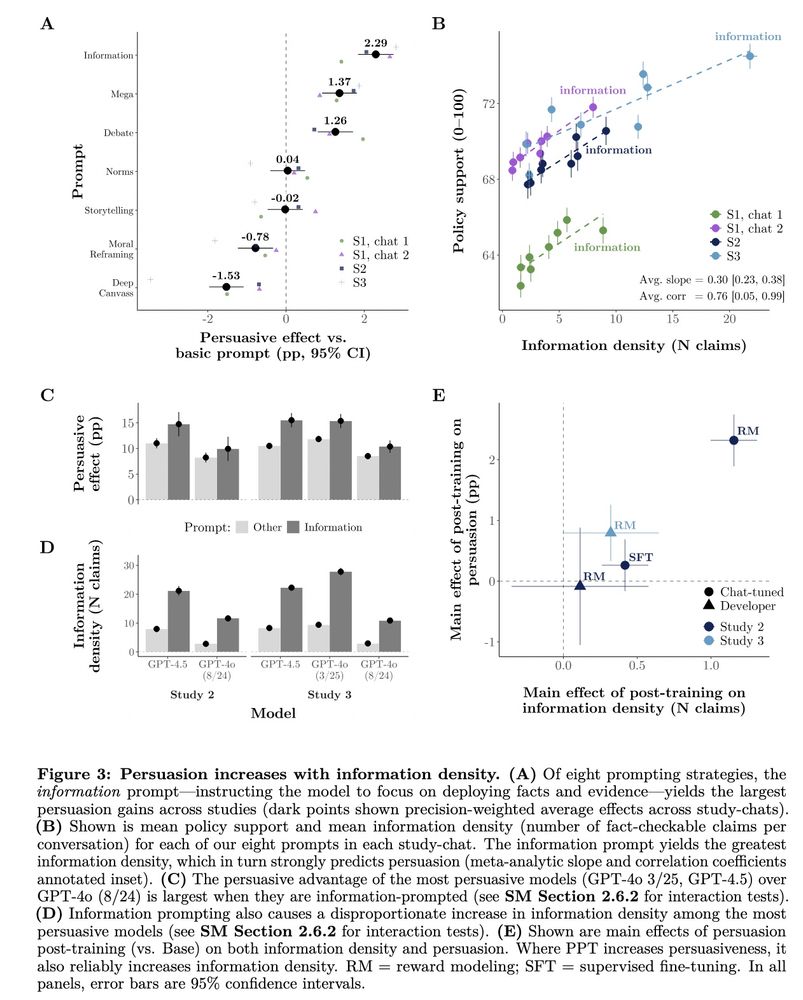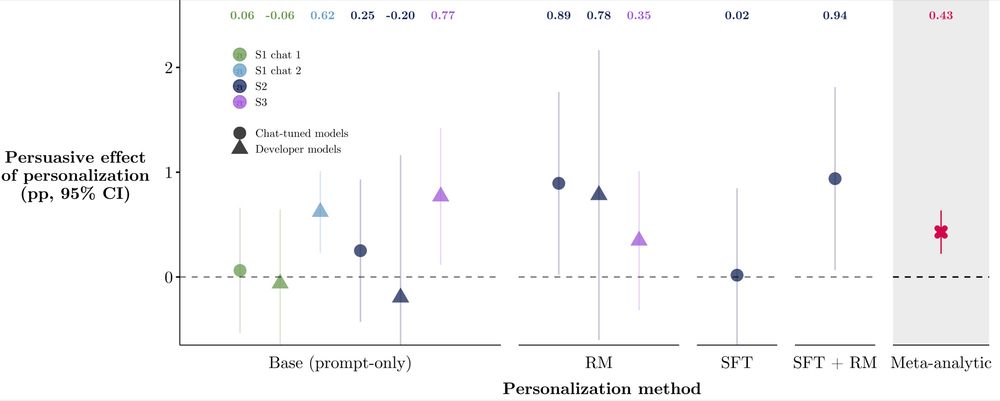
Kobi Hackenburg
@kobihackenburg.bsky.social
350 followers
84 following
31 posts
data science + political communication @oiioxford @uniofoxford
Posts
Media
Videos
Starter Packs
Pinned