




Ksenia Se
@kseniase.bsky.social
Writing TuringPost.com, learning and educating about machine learning and AI.
Working on a book about Citizen Diplomacy.
Living in the woods.
Also - being mom to four boys and one baby girl 🤘🏻
Working on a book about Citizen Diplomacy.
Living in the woods.
Also - being mom to four boys and one baby girl 🤘🏻
The most important features of LFMs (Liquid Foundation Models) from Liquid AI?
Memory-efficiency, inference speed, without compromising model quality.
LFMs have been benchmarked on real hardware, proving that they can beat Transformers.
Liquid AI have also just released Hyena Edge👇
Memory-efficiency, inference speed, without compromising model quality.
LFMs have been benchmarked on real hardware, proving that they can beat Transformers.
Liquid AI have also just released Hyena Edge👇

May 5, 2025 at 8:33 AM
The most important features of LFMs (Liquid Foundation Models) from Liquid AI?
Memory-efficiency, inference speed, without compromising model quality.
LFMs have been benchmarked on real hardware, proving that they can beat Transformers.
Liquid AI have also just released Hyena Edge👇
Memory-efficiency, inference speed, without compromising model quality.
LFMs have been benchmarked on real hardware, proving that they can beat Transformers.
Liquid AI have also just released Hyena Edge👇
7. Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions, @anthropicai.bsky.social
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236

April 30, 2025 at 11:44 PM
7. Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions, @anthropicai.bsky.social
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
6. Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...

April 30, 2025 at 11:44 PM
6. Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
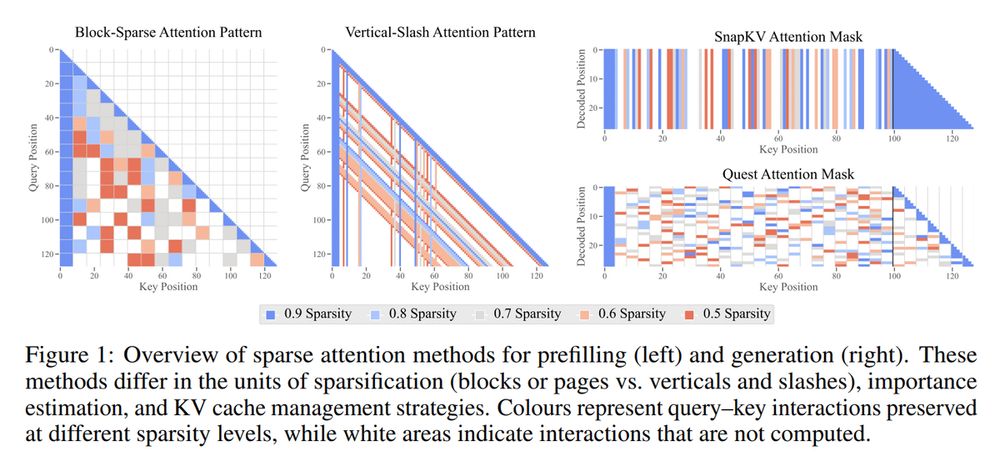
5. The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
April 30, 2025 at 11:44 PM
5. The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
4. Efficient Pretraining Length Scaling
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992

April 30, 2025 at 11:44 PM
4. Efficient Pretraining Length Scaling
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
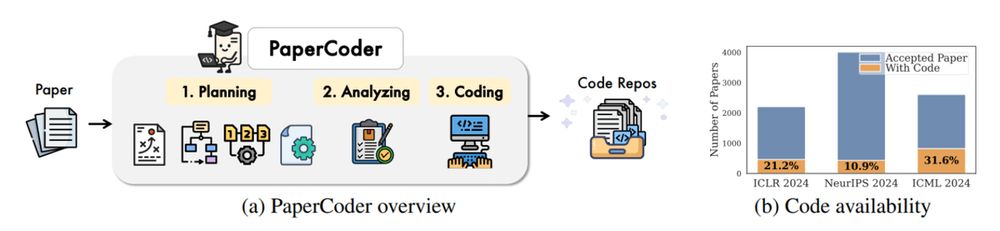
3. Paper2Code
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
April 30, 2025 at 11:44 PM
3. Paper2Code
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
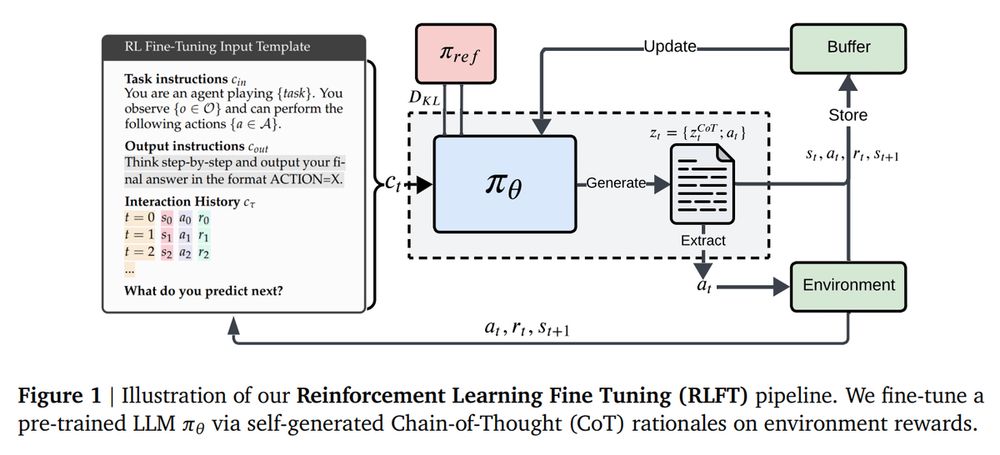
2. LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
April 30, 2025 at 11:44 PM
2. LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
1. TTRL: Test-Time Reinforcement Learning
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL

April 30, 2025 at 11:44 PM
1. TTRL: Test-Time Reinforcement Learning
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Top 7 research papers of the week:
▪️ Test-Time Reinforcement Learning
▪️ LLMs are Greedy Agents
▪️ Paper2Code
▪️ Efficient Pretraining Length Scaling
▪️ The Sparse Frontier
▪️ Roll the dice & look before you leap
▪️ Discovering and Analyzing Values in Real-World Language Model Interactions
🧵
▪️ Test-Time Reinforcement Learning
▪️ LLMs are Greedy Agents
▪️ Paper2Code
▪️ Efficient Pretraining Length Scaling
▪️ The Sparse Frontier
▪️ Roll the dice & look before you leap
▪️ Discovering and Analyzing Values in Real-World Language Model Interactions
🧵
April 30, 2025 at 11:44 PM
Top 7 research papers of the week:
▪️ Test-Time Reinforcement Learning
▪️ LLMs are Greedy Agents
▪️ Paper2Code
▪️ Efficient Pretraining Length Scaling
▪️ The Sparse Frontier
▪️ Roll the dice & look before you leap
▪️ Discovering and Analyzing Values in Real-World Language Model Interactions
🧵
▪️ Test-Time Reinforcement Learning
▪️ LLMs are Greedy Agents
▪️ Paper2Code
▪️ Efficient Pretraining Length Scaling
▪️ The Sparse Frontier
▪️ Roll the dice & look before you leap
▪️ Discovering and Analyzing Values in Real-World Language Model Interactions
🧵
9. Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...

April 29, 2025 at 11:12 AM
9. Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
8. Process Reward Models That Think introduces ThinkPRM
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...

April 29, 2025 at 11:12 AM
8. Process Reward Models That Think introduces ThinkPRM
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
5. Eagle 2.5 by NVIDIA
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/

April 29, 2025 at 11:12 AM
5. Eagle 2.5 by NVIDIA
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
4. Aimo-2 winning solution by Nvidia
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891

April 29, 2025 at 11:12 AM
4. Aimo-2 winning solution by Nvidia
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891
3. Kimi-Audio
Builds a universal audio foundation model for understanding, generating, and conversing in audio and text, achieving SOTA across diverse benchmarks.
arxiv.org/abs/2504.18425
Codes, model checkpoints, the evaluation toolkits: github.com/MoonshotAI/K...
Builds a universal audio foundation model for understanding, generating, and conversing in audio and text, achieving SOTA across diverse benchmarks.
arxiv.org/abs/2504.18425
Codes, model checkpoints, the evaluation toolkits: github.com/MoonshotAI/K...

April 29, 2025 at 11:12 AM
3. Kimi-Audio
Builds a universal audio foundation model for understanding, generating, and conversing in audio and text, achieving SOTA across diverse benchmarks.
arxiv.org/abs/2504.18425
Codes, model checkpoints, the evaluation toolkits: github.com/MoonshotAI/K...
Builds a universal audio foundation model for understanding, generating, and conversing in audio and text, achieving SOTA across diverse benchmarks.
arxiv.org/abs/2504.18425
Codes, model checkpoints, the evaluation toolkits: github.com/MoonshotAI/K...
2. Tina: Tiny Reasoning Models via LoRA:
Achieve strong reasoning capabilities with tiny models by applying cost-efficient low-rank adaptation and reinforcement learning.
arxiv.org/abs/2504.15777
Achieve strong reasoning capabilities with tiny models by applying cost-efficient low-rank adaptation and reinforcement learning.
arxiv.org/abs/2504.15777

April 29, 2025 at 11:12 AM
2. Tina: Tiny Reasoning Models via LoRA:
Achieve strong reasoning capabilities with tiny models by applying cost-efficient low-rank adaptation and reinforcement learning.
arxiv.org/abs/2504.15777
Achieve strong reasoning capabilities with tiny models by applying cost-efficient low-rank adaptation and reinforcement learning.
arxiv.org/abs/2504.15777
9 notable AI models of the week:
▪️ Hyena Edge
▪️ Tina: Tiny Reasoning Models via LoRA
▪️ Kimi-Audio
▪️ Aimo-2 winning solution
▪️ Eagle 2.5
▪️ Trillion-7B
▪️ Surya OCR
▪️ ThinkPRM
▪️ Skywork R1V2
🧵
▪️ Hyena Edge
▪️ Tina: Tiny Reasoning Models via LoRA
▪️ Kimi-Audio
▪️ Aimo-2 winning solution
▪️ Eagle 2.5
▪️ Trillion-7B
▪️ Surya OCR
▪️ ThinkPRM
▪️ Skywork R1V2
🧵
April 29, 2025 at 11:12 AM
9 notable AI models of the week:
▪️ Hyena Edge
▪️ Tina: Tiny Reasoning Models via LoRA
▪️ Kimi-Audio
▪️ Aimo-2 winning solution
▪️ Eagle 2.5
▪️ Trillion-7B
▪️ Surya OCR
▪️ ThinkPRM
▪️ Skywork R1V2
🧵
▪️ Hyena Edge
▪️ Tina: Tiny Reasoning Models via LoRA
▪️ Kimi-Audio
▪️ Aimo-2 winning solution
▪️ Eagle 2.5
▪️ Trillion-7B
▪️ Surya OCR
▪️ ThinkPRM
▪️ Skywork R1V2
🧵
Agent2Agent (A2A) is standardizing how multiple autonomous agents communicate seamlessly across applications.
Yet even with the loud launch and 50 big-name partners, Google's A2A remains underappreciated. Why?
Here are several reasons 👇
www.turingpost.com/p/a2a
Yet even with the loud launch and 50 big-name partners, Google's A2A remains underappreciated. Why?
Here are several reasons 👇
www.turingpost.com/p/a2a

April 26, 2025 at 8:42 PM
Agent2Agent (A2A) is standardizing how multiple autonomous agents communicate seamlessly across applications.
Yet even with the loud launch and 50 big-name partners, Google's A2A remains underappreciated. Why?
Here are several reasons 👇
www.turingpost.com/p/a2a
Yet even with the loud launch and 50 big-name partners, Google's A2A remains underappreciated. Why?
Here are several reasons 👇
www.turingpost.com/p/a2a
10. Scaling Laws in Scientific Discovery
Introduces the Autonomous Generalist Scientist (AGS) and proposes the possibility of new scaling laws in research
arxiv.org/abs/2503.22444
Introduces the Autonomous Generalist Scientist (AGS) and proposes the possibility of new scaling laws in research
arxiv.org/abs/2503.22444

April 8, 2025 at 12:13 PM
10. Scaling Laws in Scientific Discovery
Introduces the Autonomous Generalist Scientist (AGS) and proposes the possibility of new scaling laws in research
arxiv.org/abs/2503.22444
Introduces the Autonomous Generalist Scientist (AGS) and proposes the possibility of new scaling laws in research
arxiv.org/abs/2503.22444
9. MegaScale-Infer
Redesigns large-scale MoE serving with disaggregated attention and FFN modules to boost GPU utilization and cut costs through a tailored pipeline and M2N communication
arxiv.org/abs/2504.02263
Redesigns large-scale MoE serving with disaggregated attention and FFN modules to boost GPU utilization and cut costs through a tailored pipeline and M2N communication
arxiv.org/abs/2504.02263

April 8, 2025 at 12:13 PM
9. MegaScale-Infer
Redesigns large-scale MoE serving with disaggregated attention and FFN modules to boost GPU utilization and cut costs through a tailored pipeline and M2N communication
arxiv.org/abs/2504.02263
Redesigns large-scale MoE serving with disaggregated attention and FFN modules to boost GPU utilization and cut costs through a tailored pipeline and M2N communication
arxiv.org/abs/2504.02263
8. ZClip
A z-score-based dynamic gradient clipping method that reduces loss spikes during LLM pretraining more effectively than traditional methods
arxiv.org/abs/2504.02507
Code: github.com/bluorion-com...
A z-score-based dynamic gradient clipping method that reduces loss spikes during LLM pretraining more effectively than traditional methods
arxiv.org/abs/2504.02507
Code: github.com/bluorion-com...

April 8, 2025 at 12:13 PM
8. ZClip
A z-score-based dynamic gradient clipping method that reduces loss spikes during LLM pretraining more effectively than traditional methods
arxiv.org/abs/2504.02507
Code: github.com/bluorion-com...
A z-score-based dynamic gradient clipping method that reduces loss spikes during LLM pretraining more effectively than traditional methods
arxiv.org/abs/2504.02507
Code: github.com/bluorion-com...
7. KnowSelf
Proposes “agentic knowledgeable self-awareness” for agent models, enabling dynamic self-regulation of knowledge use during planning and decision-making
arxiv.org/abs/2504.03553
Code: github.com/zjunlp/KnowS...
Proposes “agentic knowledgeable self-awareness” for agent models, enabling dynamic self-regulation of knowledge use during planning and decision-making
arxiv.org/abs/2504.03553
Code: github.com/zjunlp/KnowS...

April 8, 2025 at 12:13 PM
7. KnowSelf
Proposes “agentic knowledgeable self-awareness” for agent models, enabling dynamic self-regulation of knowledge use during planning and decision-making
arxiv.org/abs/2504.03553
Code: github.com/zjunlp/KnowS...
Proposes “agentic knowledgeable self-awareness” for agent models, enabling dynamic self-regulation of knowledge use during planning and decision-making
arxiv.org/abs/2504.03553
Code: github.com/zjunlp/KnowS...
6. Agent S2
A compositional generalist-specialist framework for GUI automation. Introduces Mixture-of-Grounding and Proactive Hierarchical Planning
arxiv.org/abs/2504.00906
Code: github.com/simular-ai/A...
A compositional generalist-specialist framework for GUI automation. Introduces Mixture-of-Grounding and Proactive Hierarchical Planning
arxiv.org/abs/2504.00906
Code: github.com/simular-ai/A...

April 8, 2025 at 12:13 PM
6. Agent S2
A compositional generalist-specialist framework for GUI automation. Introduces Mixture-of-Grounding and Proactive Hierarchical Planning
arxiv.org/abs/2504.00906
Code: github.com/simular-ai/A...
A compositional generalist-specialist framework for GUI automation. Introduces Mixture-of-Grounding and Proactive Hierarchical Planning
arxiv.org/abs/2504.00906
Code: github.com/simular-ai/A...
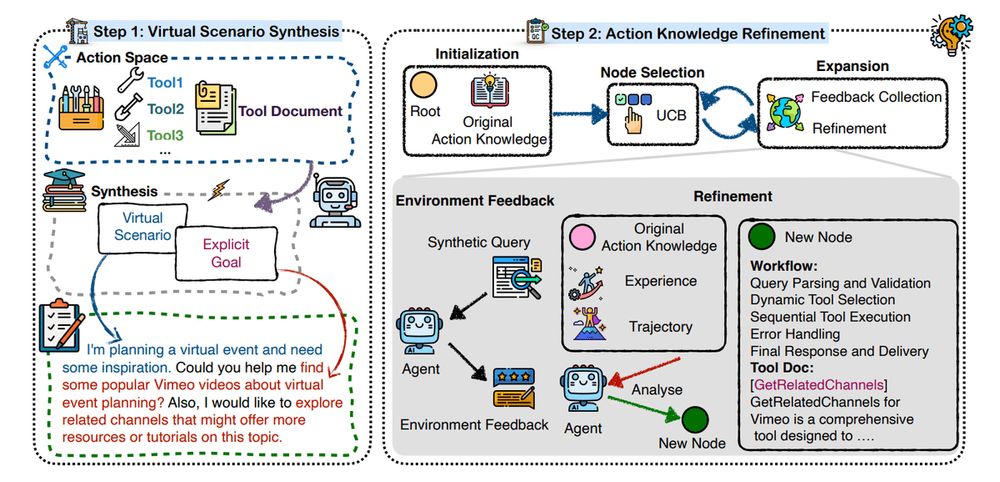
5. SynWorld
Equips LLM-based agents with scenario simulation and MCTS-based refinement of action knowledge
arxiv.org/abs/2504.03561
Equips LLM-based agents with scenario simulation and MCTS-based refinement of action knowledge
arxiv.org/abs/2504.03561
April 8, 2025 at 12:13 PM
5. SynWorld
Equips LLM-based agents with scenario simulation and MCTS-based refinement of action knowledge
arxiv.org/abs/2504.03561
Equips LLM-based agents with scenario simulation and MCTS-based refinement of action knowledge
arxiv.org/abs/2504.03561
4. Open-Reasoner-Zero
Open-source implementation of a minimalist RL training approach for LLMs, mirroring DeepSeek-R1-Zero’s effectiveness with fewer steps
arxiv.org/abs/2503.24290
GitHub: github.com/Open-Reasone...
Open-source implementation of a minimalist RL training approach for LLMs, mirroring DeepSeek-R1-Zero’s effectiveness with fewer steps
arxiv.org/abs/2503.24290
GitHub: github.com/Open-Reasone...

April 8, 2025 at 12:13 PM
4. Open-Reasoner-Zero
Open-source implementation of a minimalist RL training approach for LLMs, mirroring DeepSeek-R1-Zero’s effectiveness with fewer steps
arxiv.org/abs/2503.24290
GitHub: github.com/Open-Reasone...
Open-source implementation of a minimalist RL training approach for LLMs, mirroring DeepSeek-R1-Zero’s effectiveness with fewer steps
arxiv.org/abs/2503.24290
GitHub: github.com/Open-Reasone...
3. Inference-Time Scaling for Complex Tasks by @microsoft.com Research
Benchmarks scaling strategies across tasks and models, showing mixed results depending on domain and verifier use
arxiv.org/abs/2504.00294
Code: github.com/microsoft/eu...
Benchmarks scaling strategies across tasks and models, showing mixed results depending on domain and verifier use
arxiv.org/abs/2504.00294
Code: github.com/microsoft/eu...

April 8, 2025 at 12:13 PM
3. Inference-Time Scaling for Complex Tasks by @microsoft.com Research
Benchmarks scaling strategies across tasks and models, showing mixed results depending on domain and verifier use
arxiv.org/abs/2504.00294
Code: github.com/microsoft/eu...
Benchmarks scaling strategies across tasks and models, showing mixed results depending on domain and verifier use
arxiv.org/abs/2504.00294
Code: github.com/microsoft/eu...