




yamakatz
@kyama0321.bsky.social
Auditory Signal Processing/Objective Metrics/Hearing Assistive Technologies.
Twitter: @kyama0321
WEB: https://sites.google.com/site/kyama0321/en
Pinned
yamakatz
@kyama0321.bsky.social
· Nov 18



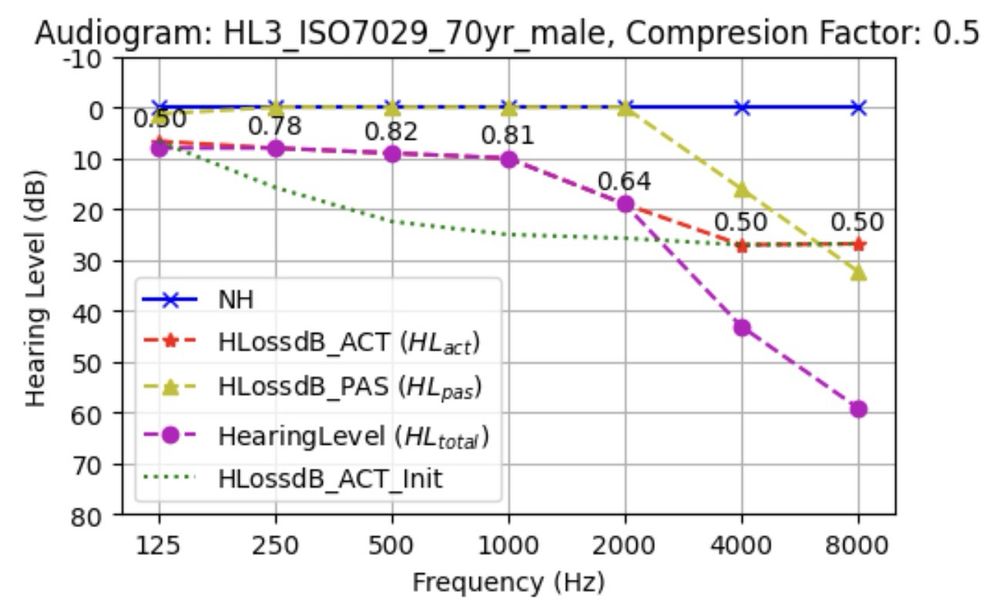
I have released the new version of GammachirPy. The v234 model can simulate an auditory filter output with listeners' audiograms and compression healthiness🦻Moreover, the frame-based processing speed is 3x faster than the previous sample-based version🚗
github.com/kyama0321/ga...
github.com/kyama0321/ga...
At the IEEE #ASRU2025, we presented our automatic evaluation system for generated audio, which won first place in the AudioMOS Challenge 2025 Track 2🥇. At the start of the session, an award ceremony was held, and I accepted the certificate on behalf of the team.



December 15, 2025 at 2:09 PM
At the IEEE #ASRU2025, we presented our automatic evaluation system for generated audio, which won first place in the AudioMOS Challenge 2025 Track 2🥇. At the start of the session, an award ceremony was held, and I accepted the certificate on behalf of the team.
December 9, 2025 at 8:19 PM
On Dec 9th, 4:00 PM, we will be giving a poster presentation titled “The T12 System for AudioMOS Challenge 2025: Audio Aesthetics Score Prediction System Using KAN- and VERSA-based Models” at ASRU2025 in Honolulu. #ASRU2025
Preprint: arxiv.org/abs/2512.05592
Preprint: arxiv.org/abs/2512.05592
December 8, 2025 at 3:12 AM
On Dec 9th, 4:00 PM, we will be giving a poster presentation titled “The T12 System for AudioMOS Challenge 2025: Audio Aesthetics Score Prediction System Using KAN- and VERSA-based Models” at ASRU2025 in Honolulu. #ASRU2025
Preprint: arxiv.org/abs/2512.05592
Preprint: arxiv.org/abs/2512.05592



Thank you for attending my talk. I'm happy to contribute to the special session on spectrotemporal modulation!
eppro02.ativ.me/web/index.ph...
eppro02.ativ.me/web/index.ph...


December 4, 2025 at 6:54 AM
Thank you for attending my talk. I'm happy to contribute to the special session on spectrotemporal modulation!
eppro02.ativ.me/web/index.ph...
eppro02.ativ.me/web/index.ph...
On Dec 3rd, 4:00 PM, I will be giving an invited talk titled "Towards Machine Learning-Driven Speech Intelligibility Prediction Models: Examining Relationships with Spectrotemporal Modulation" at the 6th ASA/ASJ joint meeting in Honolulu🏝️🌺 #ASAASJ25
eppro02.ativ.me//web/index.p...
eppro02.ativ.me//web/index.p...

December 3, 2025 at 6:37 PM
On Dec 3rd, 4:00 PM, I will be giving an invited talk titled "Towards Machine Learning-Driven Speech Intelligibility Prediction Models: Examining Relationships with Spectrotemporal Modulation" at the 6th ASA/ASJ joint meeting in Honolulu🏝️🌺 #ASAASJ25
eppro02.ativ.me//web/index.p...
eppro02.ativ.me//web/index.p...
Reposted by yamakatz

Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
August 19, 2025 at 9:23 PM
Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
I finished my presentation. Thank you for attending the session and discussion! #Interspeech2025

August 21, 2025 at 6:32 PM
I finished my presentation. Thank you for attending the session and discussion! #Interspeech2025




August 20, 2025 at 9:29 PM
Bauquet at Stadshaven Brouwerij & Gastropub🍻🎸🥁🎺🎹⛴️ #Interspeech2025
August 20, 2025 at 5:53 PM
Bauquet at Stadshaven Brouwerij & Gastropub🍻🎸🥁🎺🎹⛴️ #Interspeech2025
I'm attending #Interspeech2025 in Rotterdam 🇳🇱



August 17, 2025 at 11:56 AM
I'm attending #Interspeech2025 in Rotterdam 🇳🇱
Reposted by yamakatz

Our paper has been accepted for #Interspeech2025
Non-Intrusive Binaural Speech Intelligibility Prediction Using Mamba for Hearing-Impaired Listeners 🦻🐍
See you in Rotterdam🇳🇱
Non-Intrusive Binaural Speech Intelligibility Prediction Using Mamba for Hearing-Impaired Listeners 🦻🐍
See you in Rotterdam🇳🇱
May 19, 2025 at 12:03 PM
Our paper has been accepted for #Interspeech2025
Non-Intrusive Binaural Speech Intelligibility Prediction Using Mamba for Hearing-Impaired Listeners 🦻🐍
See you in Rotterdam🇳🇱
Non-Intrusive Binaural Speech Intelligibility Prediction Using Mamba for Hearing-Impaired Listeners 🦻🐍
See you in Rotterdam🇳🇱
Our team's year-end party was held in Shibuya, Tokyo🍶 My colleagues gave me a wedding gift🎁 Thanks!




December 23, 2024 at 2:39 PM
Our team's year-end party was held in Shibuya, Tokyo🍶 My colleagues gave me a wedding gift🎁 Thanks!
Reposted by yamakatz

Do you want to work with me for some months? Two internship positions available at the Music Team of Sony AI in Barcelona!
👇
👇

December 23, 2024 at 8:13 AM
Do you want to work with me for some months? Two internship positions available at the Music Team of Sony AI in Barcelona!
👇
👇
Unfortunately, my paper for ICASSP 2025 was rejected🥺 Thanks to the reviewers and AC for the peer review🙏 I will work hard on my next submission, reflecting the useful comments I received on my research.
December 21, 2024 at 12:13 AM
Unfortunately, my paper for ICASSP 2025 was rejected🥺 Thanks to the reviewers and AC for the peer review🙏 I will work hard on my next submission, reflecting the useful comments I received on my research.
Reposted by yamakatz

📣Amazing opportunity for #speech researchers!
Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition, Radboud University, Nijmegen, the Netherlands
More info: www.ru.nl/en/working-a...
Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition, Radboud University, Nijmegen, the Netherlands
More info: www.ru.nl/en/working-a...

Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition | Radboud University
Do you want to work as a Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition at the Faculty of Social Sciences? Check our vacancy!
www.ru.nl
December 20, 2024 at 9:48 AM
📣Amazing opportunity for #speech researchers!
Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition, Radboud University, Nijmegen, the Netherlands
More info: www.ru.nl/en/working-a...
Postdoc Position: Computational Modelling of Speech Recognition at the Donders Centre for Cognition, Radboud University, Nijmegen, the Netherlands
More info: www.ru.nl/en/working-a...
👀🦻 > Multi-objective non-intrusive hearing-aid speech assessment model
pubs.aip.org/asa/jasa/art...
pubs.aip.org/asa/jasa/art...

Multi-objective non-intrusive hearing-aid speech assessment model
Because a reference signal is often unavailable in real-world scenarios, reference-free speech quality and intelligibility assessment models are important for m
pubs.aip.org
December 10, 2024 at 11:04 PM
👀🦻 > Multi-objective non-intrusive hearing-aid speech assessment model
pubs.aip.org/asa/jasa/art...
pubs.aip.org/asa/jasa/art...
🤖👂 > SPS SLTC/AASP TECHNICAL COMMITTEE WEBINAR
Audio Signal Enhancement: A Weakly Supervised Deep Learning Approach
15 January 2025
Presented by Dr. Nobutaka Ito & Dr. Yoshiaki Bando
landing.signalprocessingsociety.org/jan-15-2024
Audio Signal Enhancement: A Weakly Supervised Deep Learning Approach
15 January 2025
Presented by Dr. Nobutaka Ito & Dr. Yoshiaki Bando
landing.signalprocessingsociety.org/jan-15-2024
IEEE SPS Webinars | 15 Jan 2025
Join us for an expert-led webinar to explore cutting-edge topics in signal processing. Register now and stay updated on upcoming events!
landing.signalprocessingsociety.org
December 10, 2024 at 11:51 AM
🤖👂 > SPS SLTC/AASP TECHNICAL COMMITTEE WEBINAR
Audio Signal Enhancement: A Weakly Supervised Deep Learning Approach
15 January 2025
Presented by Dr. Nobutaka Ito & Dr. Yoshiaki Bando
landing.signalprocessingsociety.org/jan-15-2024
Audio Signal Enhancement: A Weakly Supervised Deep Learning Approach
15 January 2025
Presented by Dr. Nobutaka Ito & Dr. Yoshiaki Bando
landing.signalprocessingsociety.org/jan-15-2024
Reposted by yamakatz

A paper explaining how, in order to succeed in training a CLIP-like contrastive-based VL model, the alignment between the image and text encoders should be maintained
arxiv.org/abs/2412.04616
arxiv.org/abs/2412.04616

December 10, 2024 at 6:55 AM
A paper explaining how, in order to succeed in training a CLIP-like contrastive-based VL model, the alignment between the image and text encoders should be maintained
arxiv.org/abs/2412.04616
arxiv.org/abs/2412.04616
👀👂 > OHHR – The Oldenburg Hearing Health Repository [Dataset]
zenodo.org/records/1417...
zenodo.org/records/1417...
OHHR – The Oldenburg Hearing Health Repository [Dataset]
Description of the dataset The Oldenburg Hearing Health Repository (OHHR) provides a publicly accessible dataset that can be used to advance hearing health research. It includes a constellation of dat...
zenodo.org
December 9, 2024 at 5:22 AM
👀👂 > OHHR – The Oldenburg Hearing Health Repository [Dataset]
zenodo.org/records/1417...
zenodo.org/records/1417...
Donated to arXiv for open science🕊️

December 6, 2024 at 8:46 AM
Donated to arXiv for open science🕊️
🦋🎓👀 > Altmetric introduces Bluesky as a new social media tracking source - Altmetric
www.altmetric.com/altmetric-ne...
www.altmetric.com/altmetric-ne...

Altmetric introduces Bluesky as a new social media tracking source
Altmetric has expanded its tracking capabilities by integrating Bluesky, as a new attention source.
www.altmetric.com
December 6, 2024 at 4:17 AM
🦋🎓👀 > Altmetric introduces Bluesky as a new social media tracking source - Altmetric
www.altmetric.com/altmetric-ne...
www.altmetric.com/altmetric-ne...