Luke Sanford
@lcsanford.bsky.social
7.1K followers
2.5K following
110 posts
Assistant Prof. at Yale School of the Environment. Political economy of climate and environment, land use change, remote sensing, causal ML. https://sanford-lab.github.io/
Posts
Media
Videos
Starter Packs
Reposted by Luke Sanford



Luke Sanford
@lcsanford.bsky.social
· May 9
Luke Sanford
@lcsanford.bsky.social
· May 4

Luke Sanford
@lcsanford.bsky.social
· Mar 29
Reposted by Luke Sanford


Reposted by Luke Sanford

Vicky Harp
@vickyharp.com
· Mar 15




Luke Sanford
@lcsanford.bsky.social
· Mar 18
Luke Sanford
@lcsanford.bsky.social
· Mar 18

Parameter Recovery Using Remotely Sensed Variables
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
www.nber.org
Luke Sanford
@lcsanford.bsky.social
· Mar 18
Luke Sanford
@lcsanford.bsky.social
· Mar 18
Luke Sanford
@lcsanford.bsky.social
· Mar 17
Luke Sanford
@lcsanford.bsky.social
· Mar 17
Parameter Recovery Using Remotely Sensed Variables
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
www.nber.org
Luke Sanford
@lcsanford.bsky.social
· Mar 17
Luke Sanford
@lcsanford.bsky.social
· Mar 17

Adversarial Debiasing for Unbiased Parameter Recovery
Advances in machine learning and the increasing availability of high-dimensional data have led to the proliferation of social science research that uses the predictions of machine learning models as p...
arxiv.org
Luke Sanford
@lcsanford.bsky.social
· Mar 17
Parameter Recovery Using Remotely Sensed Variables
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
www.nber.org
Luke Sanford
@lcsanford.bsky.social
· Mar 17




Luke Sanford
@lcsanford.bsky.social
· Mar 17
Luke Sanford
@lcsanford.bsky.social
· Mar 17
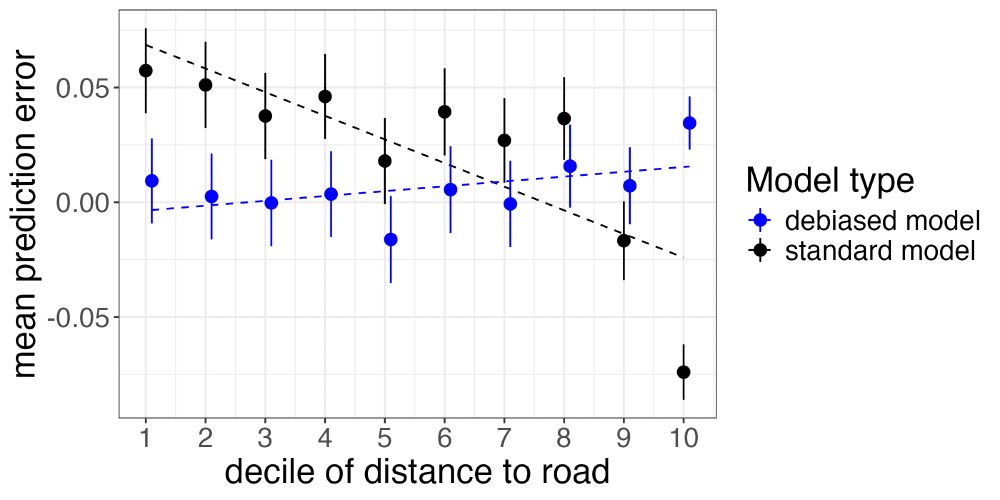
Adversarial Debiasing for Unbiased Parameter Recovery
Advances in machine learning and the increasing availability of high-dimensional data have led to the proliferation of social science research that uses the predictions of machine learning models as p...
arxiv.org