Leqi Liu
@leqiliu.bsky.social
170 followers
7 following
23 posts
AI/ML Researcher | Assistant Professor at UT Austin | Postdoc at Princeton PLI | PhD, Machine Learning Department, CMU. Research goal: Building controllable machine intelligence that serves humanity safely. leqiliu.github.io
Posts
Media
Videos
Starter Packs

Leqi Liu
@leqiliu.bsky.social
· Jul 22

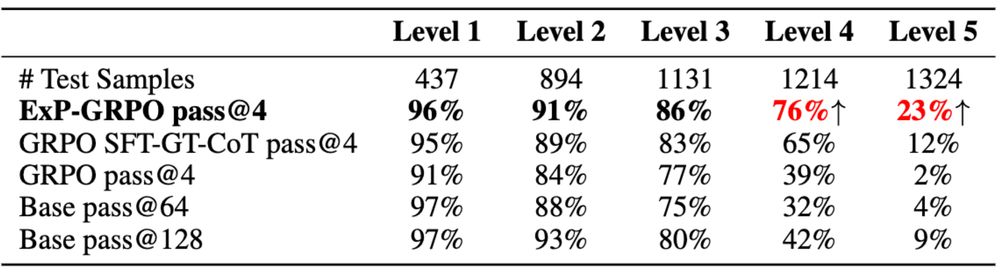
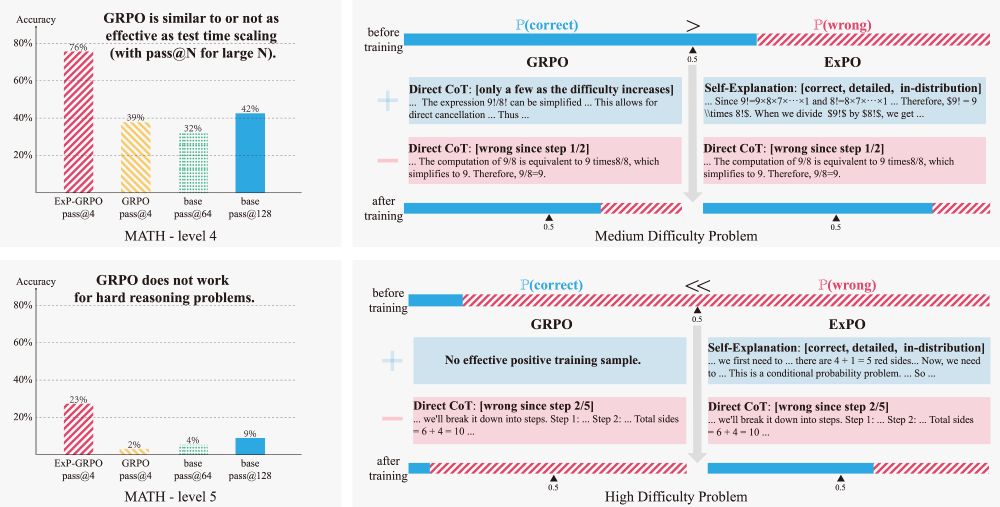
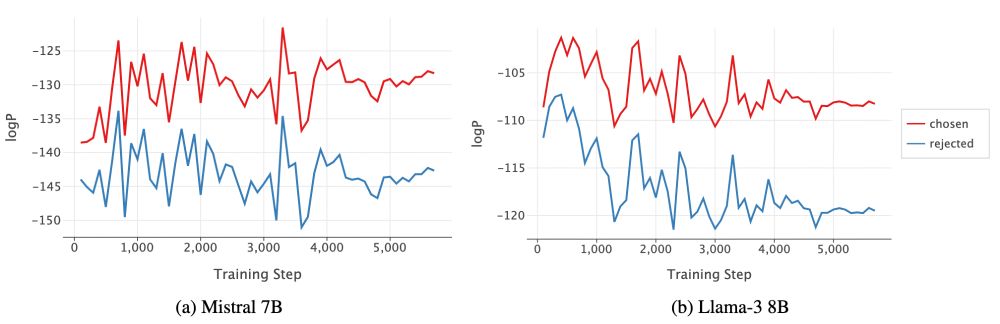
ExPO: Unlocking Hard Reasoning with Self-Explanation-Guided Reinforcement Learning
Recent advances in large language models have been driven by reinforcement learning (RL)-style post-training, which improves reasoning by optimizing model outputs based on reward or preference signals...
arxiv.org
Leqi Liu
@leqiliu.bsky.social
· Jul 22
Leqi Liu
@leqiliu.bsky.social
· Jul 22
Leqi Liu
@leqiliu.bsky.social
· Jul 10
Linear Representation Transferability Hypothesis: Leveraging Small Models to Steer Large Models
It has been hypothesized that neural networks with similar architectures trained on similar data learn shared representations relevant to the learning task. We build on this idea by extending the conc...
arxiv.org
Leqi Liu
@leqiliu.bsky.social
· Jul 10
Leqi Liu
@leqiliu.bsky.social
· Jul 10
Leqi Liu
@leqiliu.bsky.social
· Jul 10
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Leqi Liu
@leqiliu.bsky.social
· Dec 14
Reposted by Leqi Liu
