Yu Lu Liu
@liuyulu.bsky.social
1K followers
890 following
34 posts
PhD student at Johns Hopkins University
Alumni from McGill University & MILA
Working on NLP Evaluation, Responsible AI, Human-AI interaction
she/her 🇨🇦
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Yu Lu Liu


Reposted by Yu Lu Liu


Yu Lu Liu
@liuyulu.bsky.social
· Apr 3
Reposted by Yu Lu Liu





Yu Lu Liu
@liuyulu.bsky.social
· Dec 16
Reposted by Yu Lu Liu

Reposted by Yu Lu Liu
Reposted by Yu Lu Liu
Dr. Arjun
@arjunsubgraph.bsky.social
· Dec 4

It Takes Two to Tango: Navigating Conceptualizations of NLP Tasks and Measurements of Performance
Progress in NLP is increasingly measured through benchmarks; hence, contextualizing progress requires understanding when and why practitioners may disagree about the validity of benchmarks. We develop...
arxiv.org
Reposted by Yu Lu Liu

Eryk Salvaggio
@eryk.bsky.social
· Dec 2
Reposted by Yu Lu Liu
Alexandra Olteanu
@aolteanu.bsky.social
· Nov 30
Yu Lu Liu
@liuyulu.bsky.social
· Nov 28
Reposted by Yu Lu Liu

Dr. Casey Fiesler
@cfiesler.bsky.social
· Nov 27


Yu Lu Liu
@liuyulu.bsky.social
· Nov 27
Reposted by Yu Lu Liu

Reposted by Yu Lu Liu

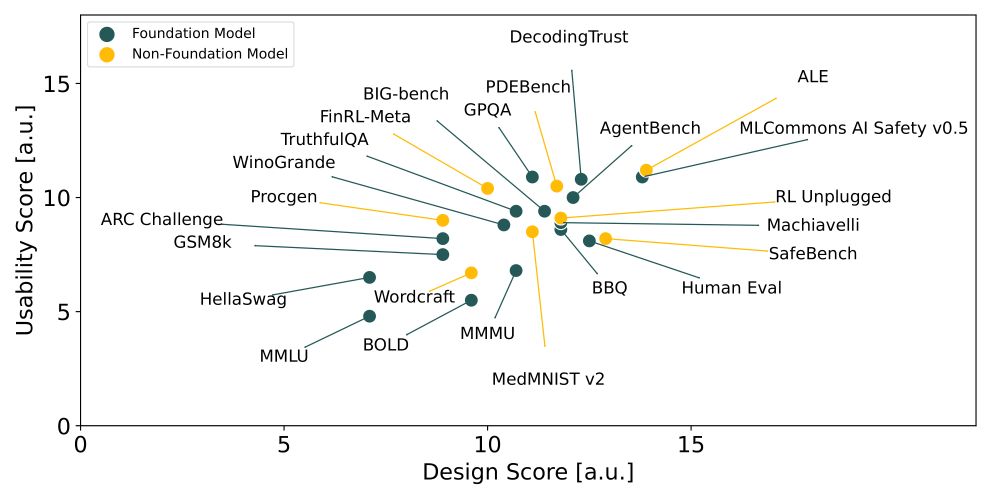
Reposted by Yu Lu Liu

Reposted by Yu Lu Liu
McGill NLP
@mcgill-nlp.bsky.social
· Nov 23
Yu Lu Liu
@liuyulu.bsky.social
· Nov 23
Yu Lu Liu
@liuyulu.bsky.social
· Nov 23
Yu Lu Liu
@liuyulu.bsky.social
· Nov 23