Luke Marris
@lukemarris.bsky.social
680 followers
170 following
24 posts
Research Engineer at Google DeepMind.
Interests in game theory, reinforcement learning, and deep learning.
Website: https://www.lukemarris.info/
Google Scholar: https://scholar.google.com/citations?user=dvTeSX4AAAAJ
Posts
Media
Videos
Starter Packs
Reposted by Luke Marris




Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17

Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17
Luke Marris
@lukemarris.bsky.social
· Apr 17
Reposted by Luke Marris
Reposted by Luke Marris

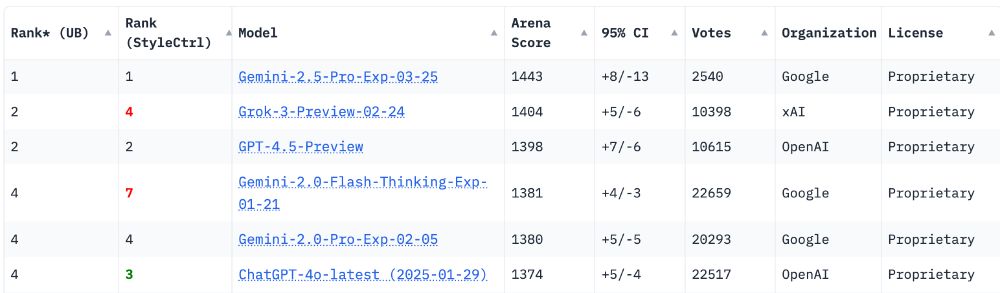

Reposted by Luke Marris

Marc Lanctot
@sharky6000.bsky.social
· Feb 24
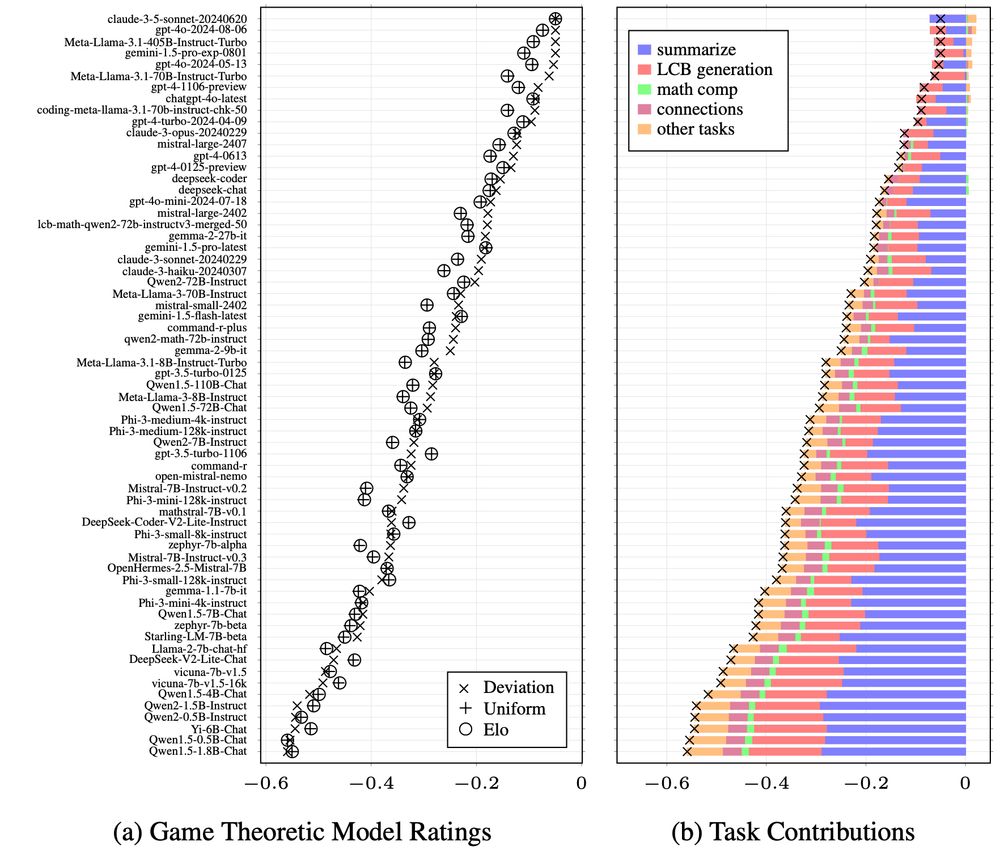
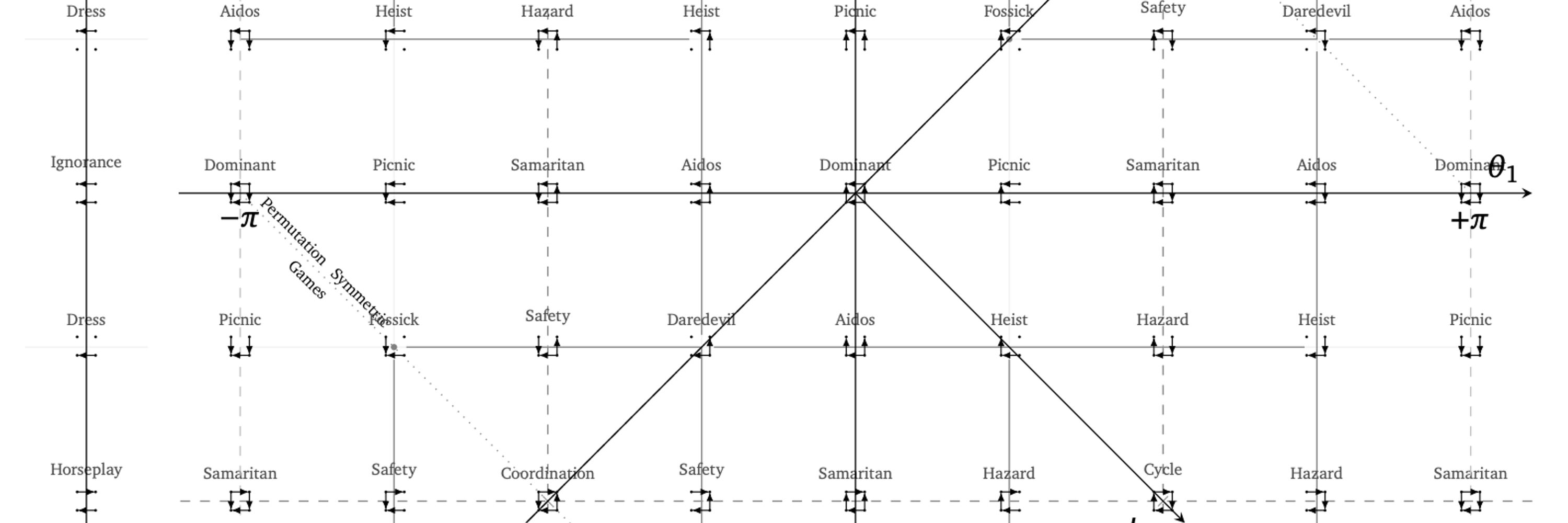
Luke Marris
@lukemarris.bsky.social
· Feb 18
Luke Marris
@lukemarris.bsky.social
· Feb 18
Luke Marris
@lukemarris.bsky.social
· Feb 18
Luke Marris
@lukemarris.bsky.social
· Feb 18
Luke Marris
@lukemarris.bsky.social
· Feb 18
Luke Marris
@lukemarris.bsky.social
· Feb 18

Luke Marris
@lukemarris.bsky.social
· Feb 18