Max Zhdanov
@maxxxzdn.bsky.social
530 followers
230 following
86 posts
PhD candidate at AMLab with Max Welling and Jan-Willem van de Meent.
Research in physics-inspired and geometric deep learning.
Posts
Media
Videos
Starter Packs

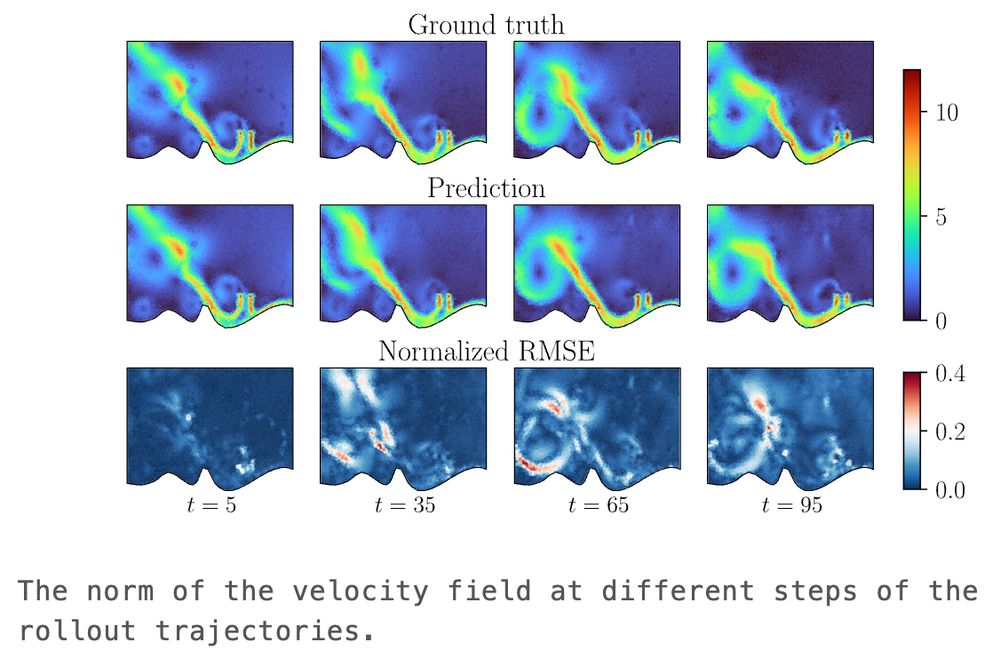
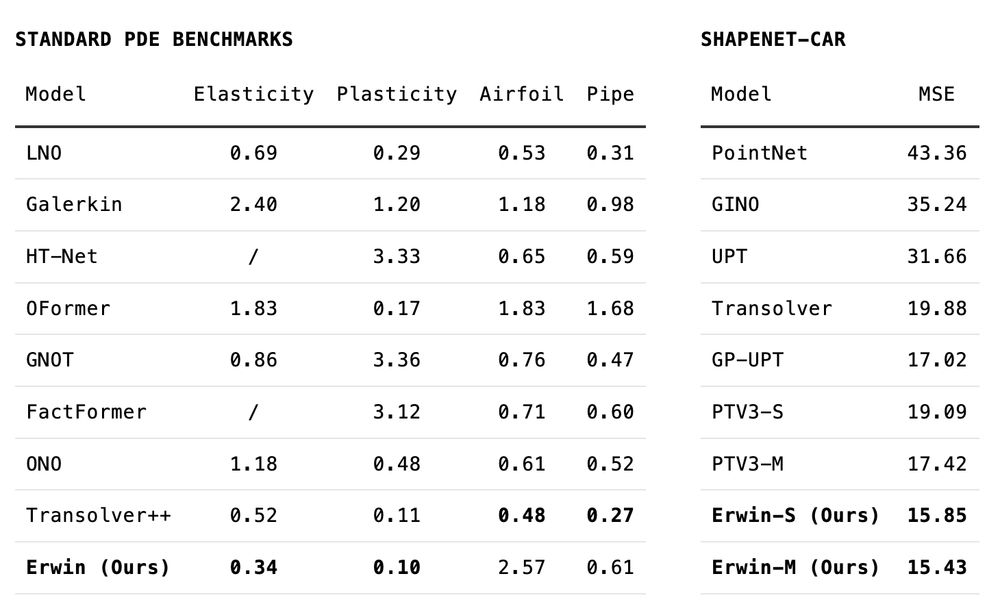
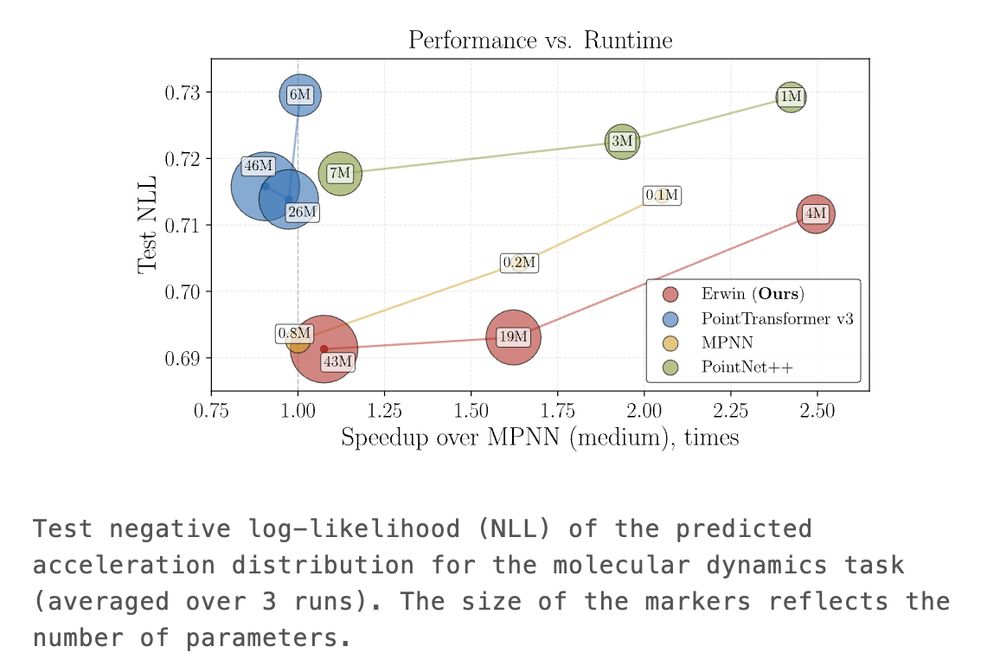
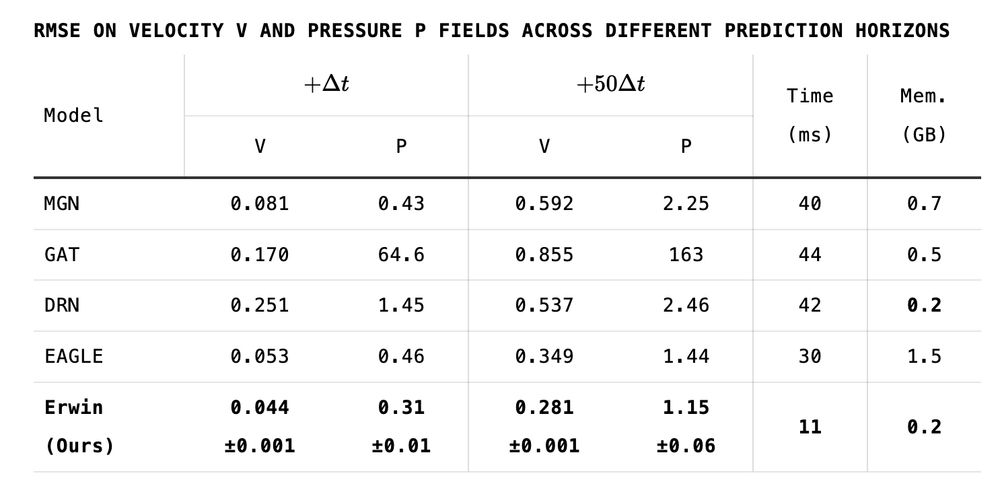
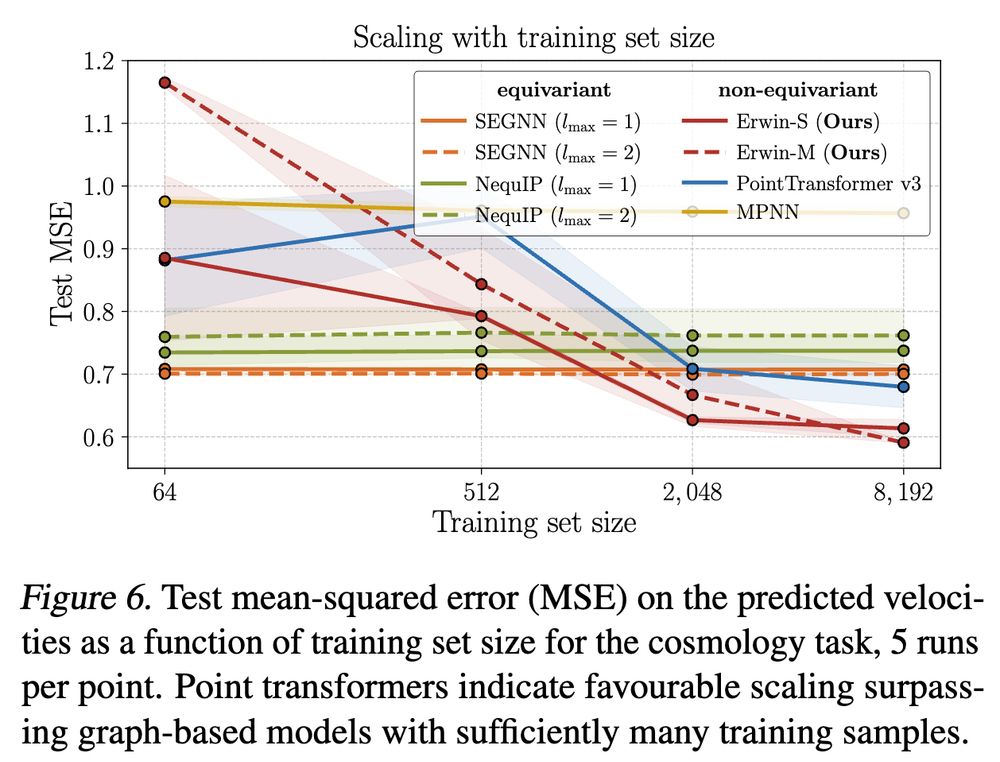

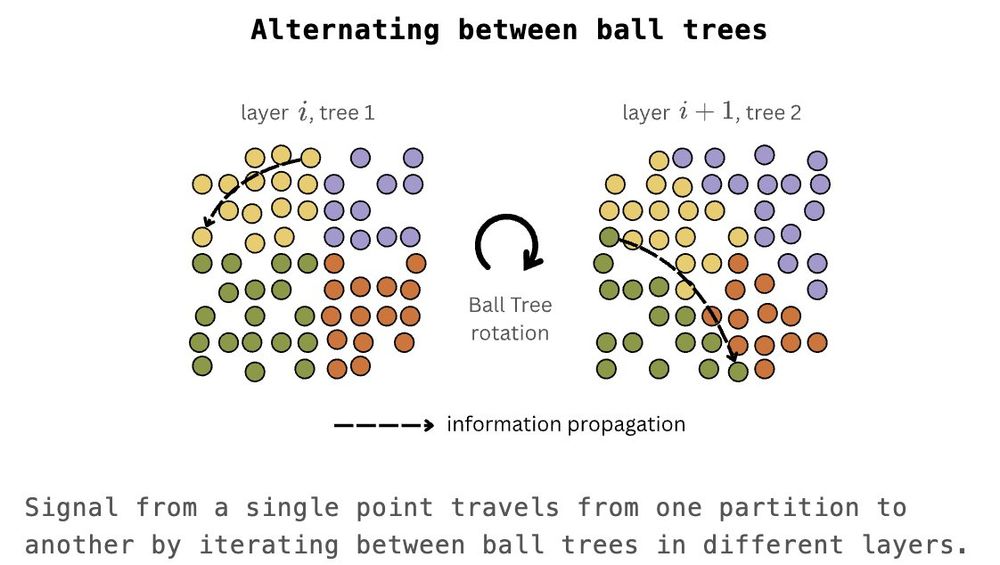

Max Zhdanov
@maxxxzdn.bsky.social
· Jun 21
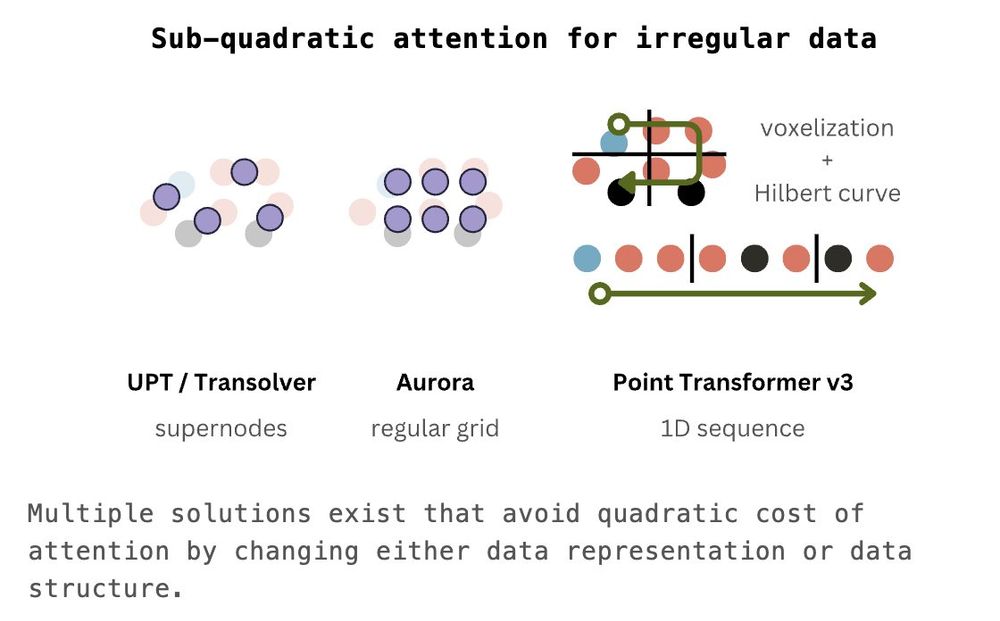
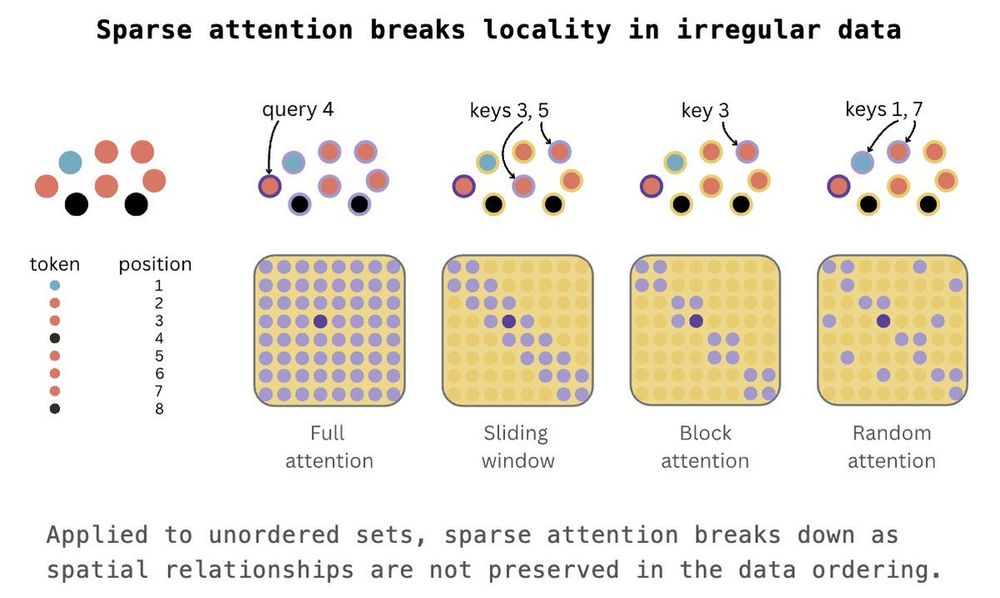
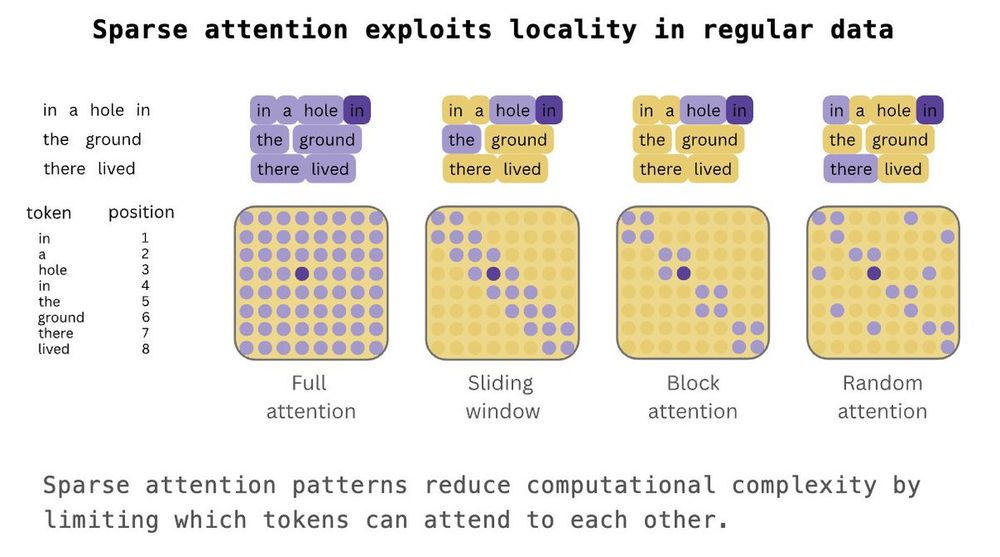

Max Zhdanov
@maxxxzdn.bsky.social
· Mar 25
Max Zhdanov
@maxxxzdn.bsky.social
· Mar 5
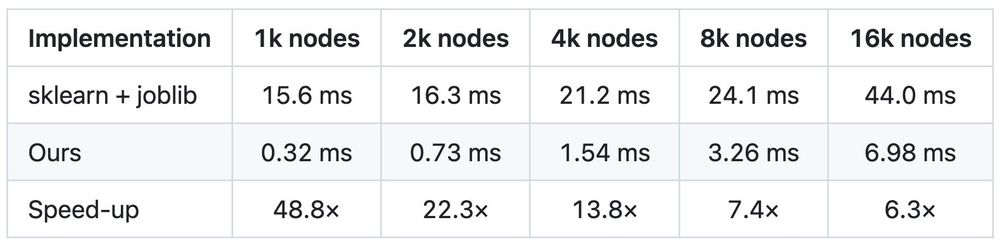
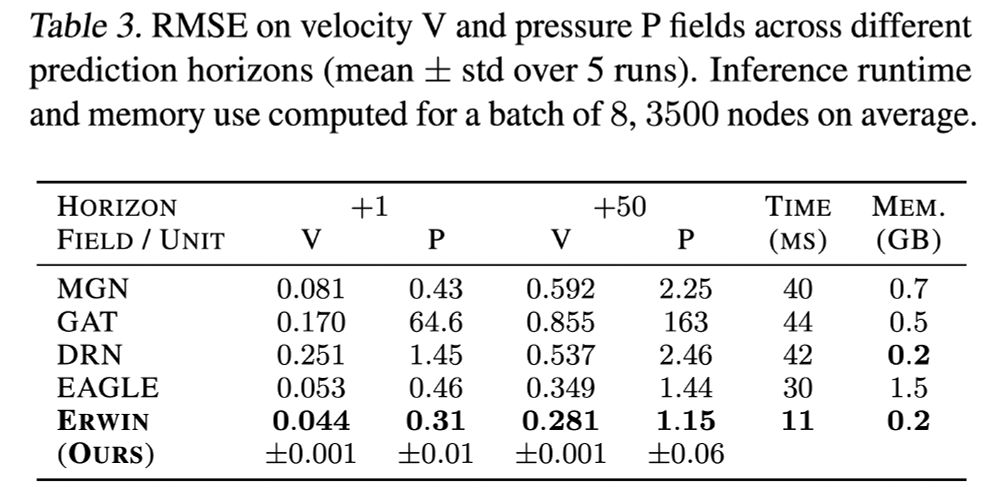
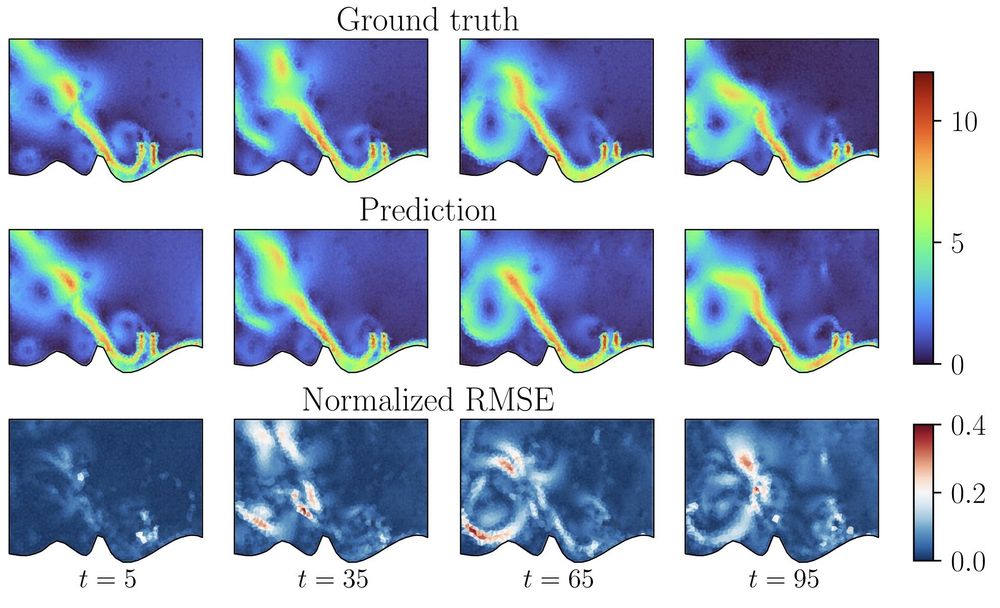
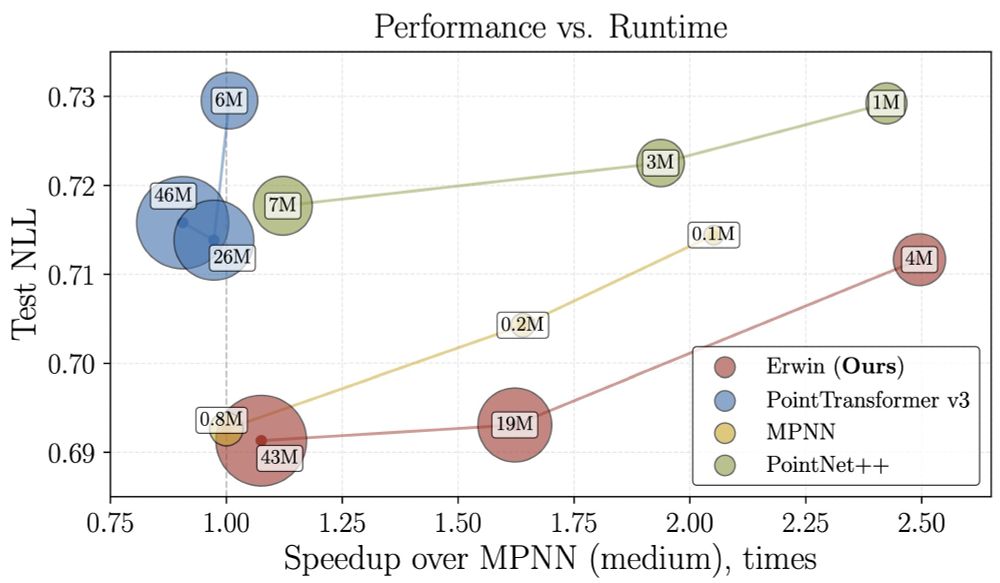
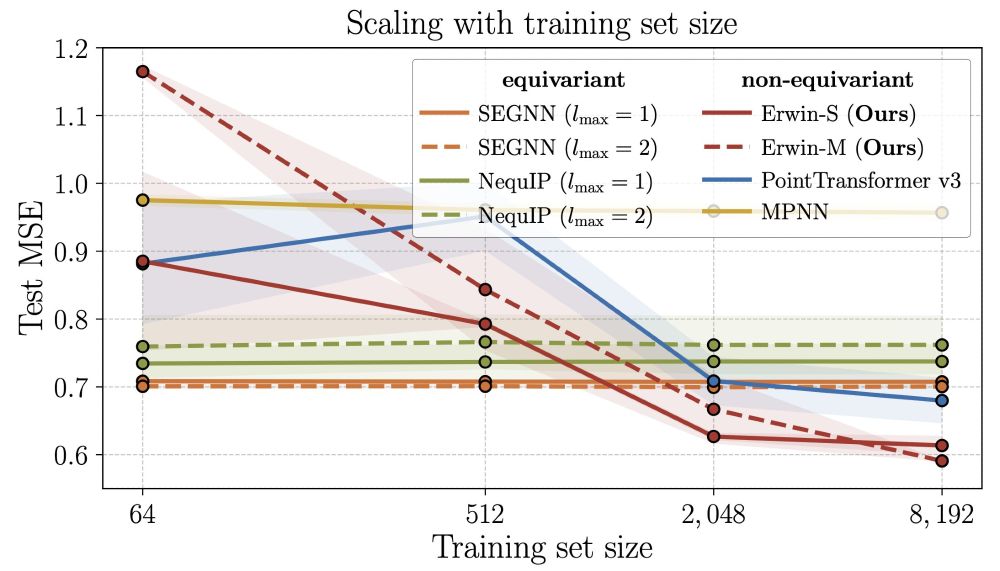
Max Zhdanov
@maxxxzdn.bsky.social
· Mar 5