mcps.sh
@mcps.sh
mcps.sh - the latest news and tech from the Model Context Protocol ecosystem

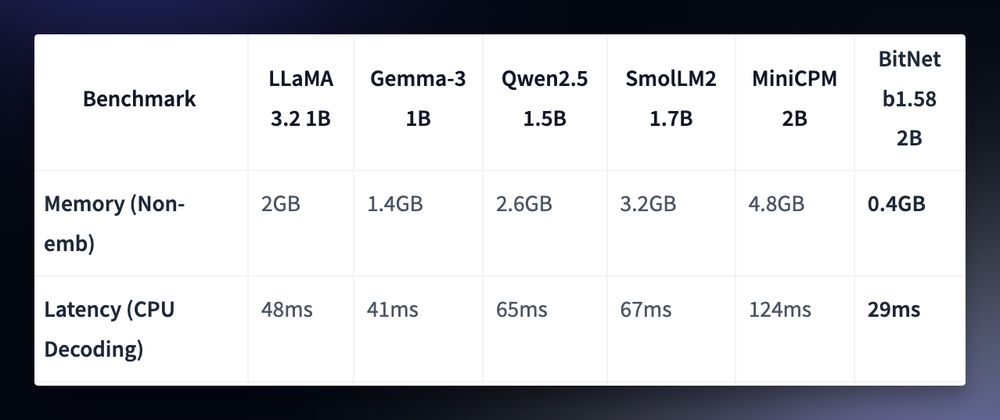
Quantisation? What about a 1-bit LLM:
Microsoft released their 1-bit LLM with comparable performance to traditional models (LLaMA, Qwen, Smol), but 0.4GB memory footprint and faster latency
Microsoft released their 1-bit LLM with comparable performance to traditional models (LLaMA, Qwen, Smol), but 0.4GB memory footprint and faster latency
April 16, 2025 at 12:46 PM
Quantisation? What about a 1-bit LLM:
Microsoft released their 1-bit LLM with comparable performance to traditional models (LLaMA, Qwen, Smol), but 0.4GB memory footprint and faster latency
Microsoft released their 1-bit LLM with comparable performance to traditional models (LLaMA, Qwen, Smol), but 0.4GB memory footprint and faster latency