Marianne de Heer Kloots
@mdhk.net
1.2K followers
490 following
100 posts
Linguist in AI & CogSci 🧠👩💻🤖 PhD student @ ILLC, University of Amsterdam
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
Posts
Media
Videos
Starter Packs
Pinned

Marianne de Heer Kloots
@mdhk.net
· Jul 8




Reposted by Marianne de Heer Kloots





Marianne de Heer Kloots
@mdhk.net
· Aug 27
Marianne de Heer Kloots
@mdhk.net
· Aug 27

Marianne de Heer Kloots
@mdhk.net
· Aug 27
Marianne de Heer Kloots
@mdhk.net
· Aug 27


Marianne de Heer Kloots
@mdhk.net
· Aug 27

Marianne de Heer Kloots
@mdhk.net
· Aug 20
Marianne de Heer Kloots
@mdhk.net
· Aug 19
Marianne de Heer Kloots
@mdhk.net
· Aug 19
Reposted by Marianne de Heer Kloots

Reposted by Marianne de Heer Kloots



Marianne de Heer Kloots
@mdhk.net
· Aug 12
Marianne de Heer Kloots
@mdhk.net
· Aug 12
Marianne de Heer Kloots
@mdhk.net
· Aug 12


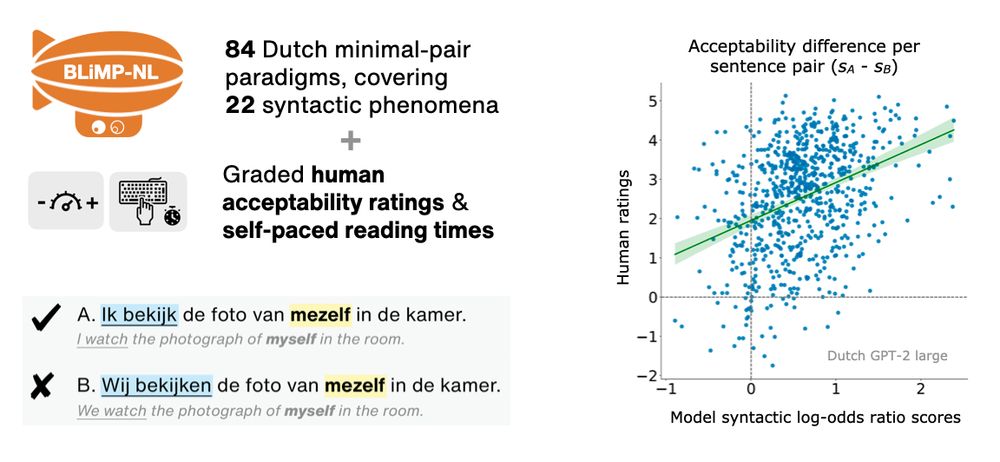
Marianne de Heer Kloots
@mdhk.net
· Jul 29