
Mark Dredze
@mdredze.bsky.social
2.7K followers
380 following
66 posts
John C Malone Professor at Johns Hopkins Computer Science, Center for Language and Speech Processing, Malone Center for Engineering in Healthcare.
Parttime: Bloomberg LP #nlproc
Posts
Media
Videos
Starter Packs
Reposted by Mark Dredze


Reposted by Mark Dredze


Mark Dredze
@mdredze.bsky.social
· Feb 19

David Broniatowski on LinkedIn: NIH has just announced that it will save $4 billion by capping university… | 61 comments
NIH has just announced that it will save $4 billion by capping university indirect costs on federal grants. Will this actually save money?
Bottom line: No. It… | 61 comments on LinkedIn
www.linkedin.com

Mark Dredze
@mdredze.bsky.social
· Jan 30
Mark Dredze
@mdredze.bsky.social
· Jan 27
Mark Dredze
@mdredze.bsky.social
· Jan 24
Mark Dredze
@mdredze.bsky.social
· Jan 21
Mark Dredze
@mdredze.bsky.social
· Jan 20
Mark Dredze
@mdredze.bsky.social
· Jan 20







Mark Dredze
@mdredze.bsky.social
· Dec 22
Mark Dredze
@mdredze.bsky.social
· Dec 22
Mark Dredze
@mdredze.bsky.social
· Dec 22
Mark Dredze
@mdredze.bsky.social
· Dec 22

Mark Dredze
@mdredze.bsky.social
· Dec 22

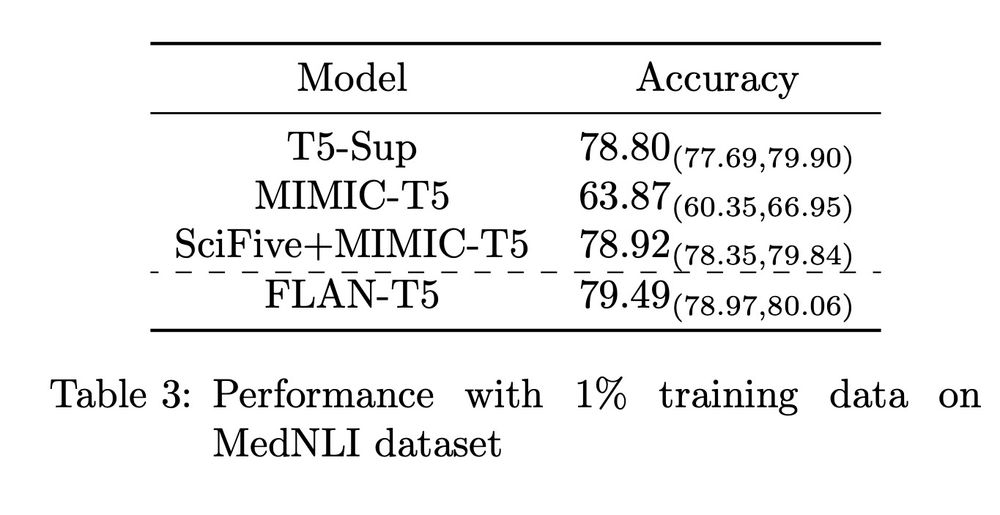
Are Clinical T5 Models Better for Clinical Text?
Large language models with a transformer-based encoder/decoder architecture, such as T5, have become standard platforms for supervised tasks. To bring these technologies to the clinical domain, recent...
arxiv.org
Mark Dredze
@mdredze.bsky.social
· Dec 22