Mor Geva
@megamor2.bsky.social
840 followers
76 following
29 posts
https://mega002.github.io
Posts
Media
Videos
Starter Packs
Reposted by Mor Geva

Reposted by Mor Geva


Reposted by Mor Geva

Reposted by Mor Geva

Marius Mosbach
@mariusmosbach.bsky.social
· Apr 15
Reposted by Mor Geva



Mor Geva
@megamor2.bsky.social
· Mar 31


Mor Geva
@megamor2.bsky.social
· Jan 28

Enhancing Automated Interpretability with Output-Centric Feature Descriptions
Automated interpretability pipelines generate natural language descriptions for the concepts represented by features in large language models (LLMs), such as plants or the first word in a sentence. Th...
arxiv.org


Mor Geva
@megamor2.bsky.social
· Jan 28

Mor Geva
@megamor2.bsky.social
· Jan 28
Reposted by Mor Geva


Mor Geva
@megamor2.bsky.social
· Dec 18
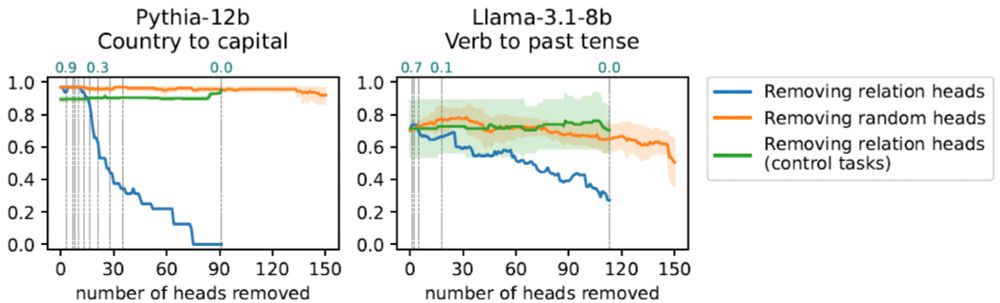
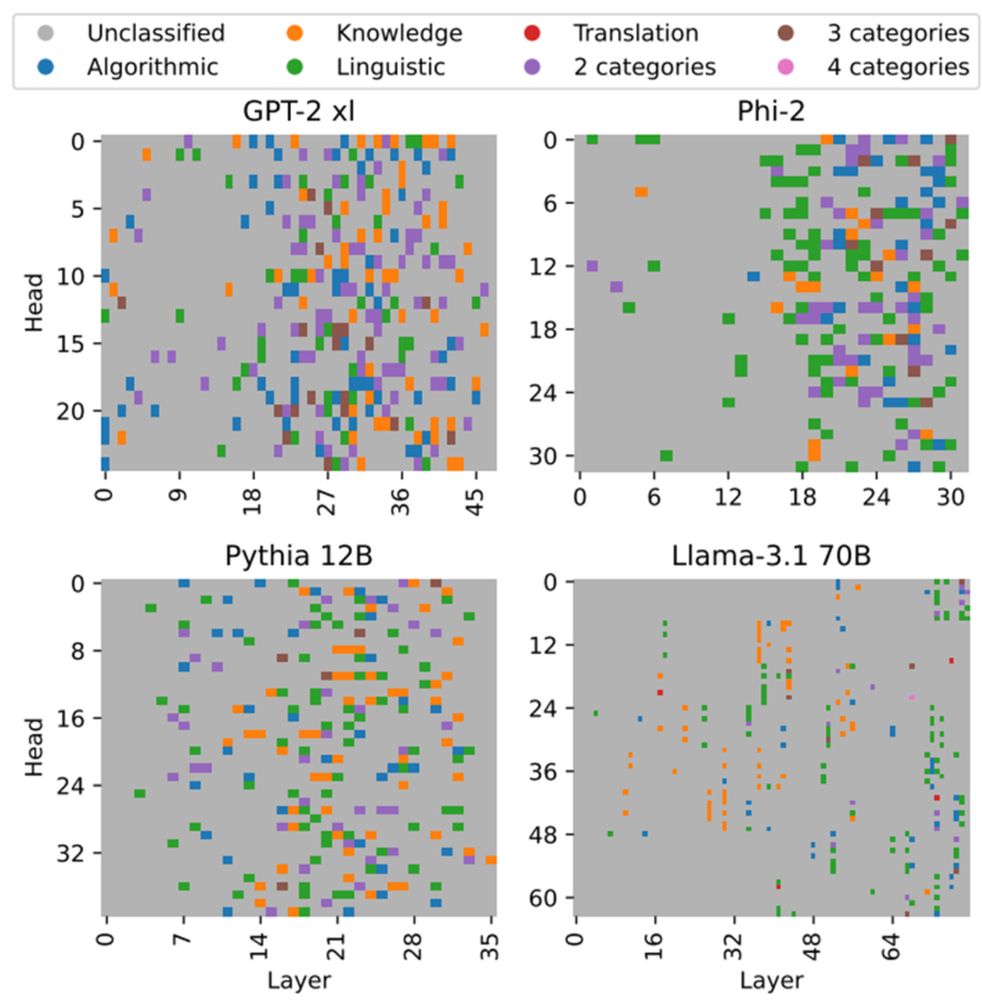
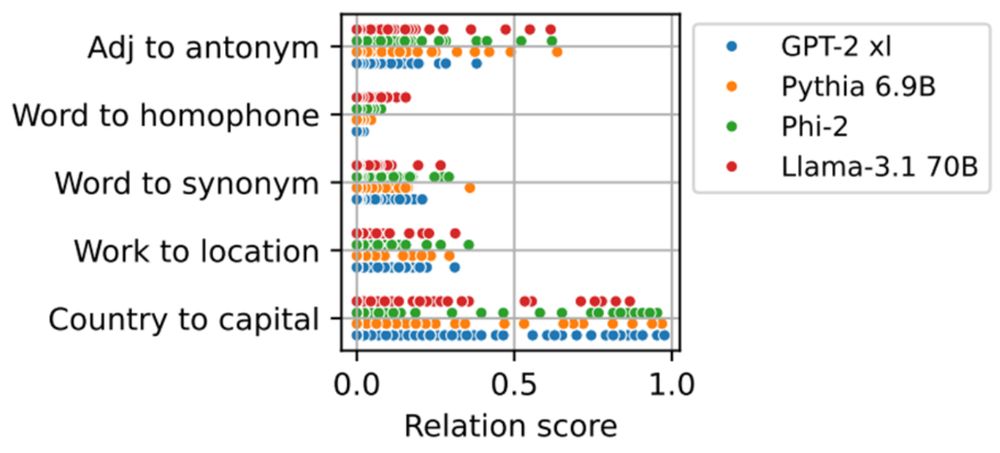
Inferring Functionality of Attention Heads from their Parameters
Attention heads are one of the building blocks of large language models (LLMs). Prior work on investigating their operation mostly focused on analyzing their behavior during inference for specific cir...
arxiv.org

Mor Geva
@megamor2.bsky.social
· Dec 18
Mor Geva
@megamor2.bsky.social
· Dec 18