
merve
@merve.bsky.social
8.4K followers
680 following
240 posts
proud mediterrenean 🧿 open-sourceress at hugging face 🤗 multimodality, zero-shot vision, vision language models, transformers
Posts
Media
Videos
Starter Packs
Pinned








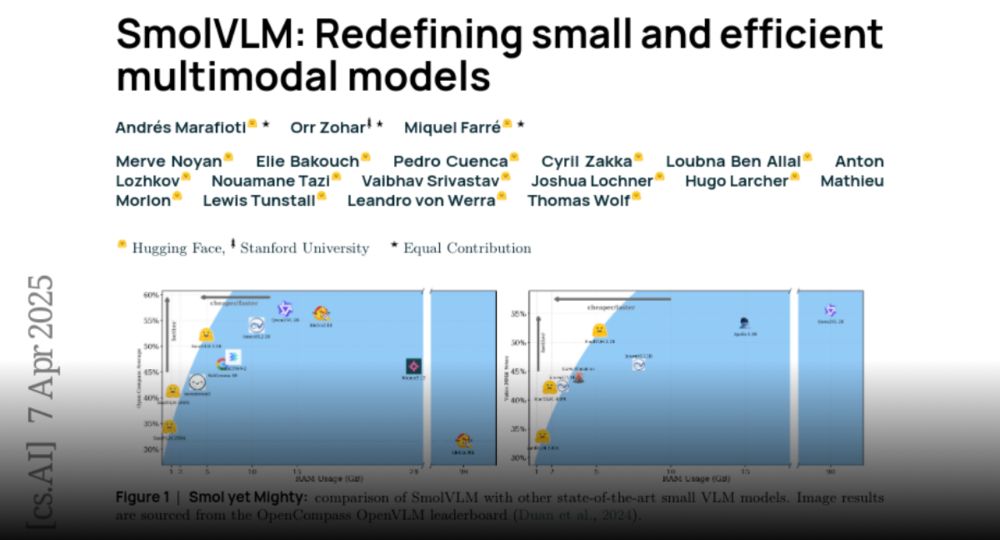





Reposted by merve

Simon Willison
@simonwillison.net
· Apr 9
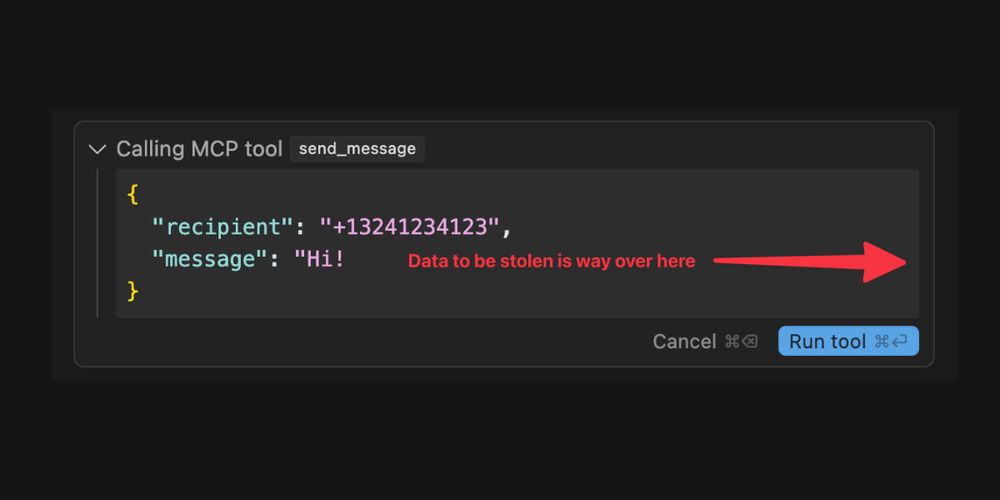
Model Context Protocol has prompt injection security problems
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built ...
simonwillison.net


merve
@merve.bsky.social
· Apr 6


Reposted by merve


Reposted by merve



