Mourad Heddaya
@mheddaya.bsky.social
130 followers
150 following
20 posts
nlp phd student at uchicago cs
Posts
Media
Videos
Starter Packs
Reposted by Mourad Heddaya

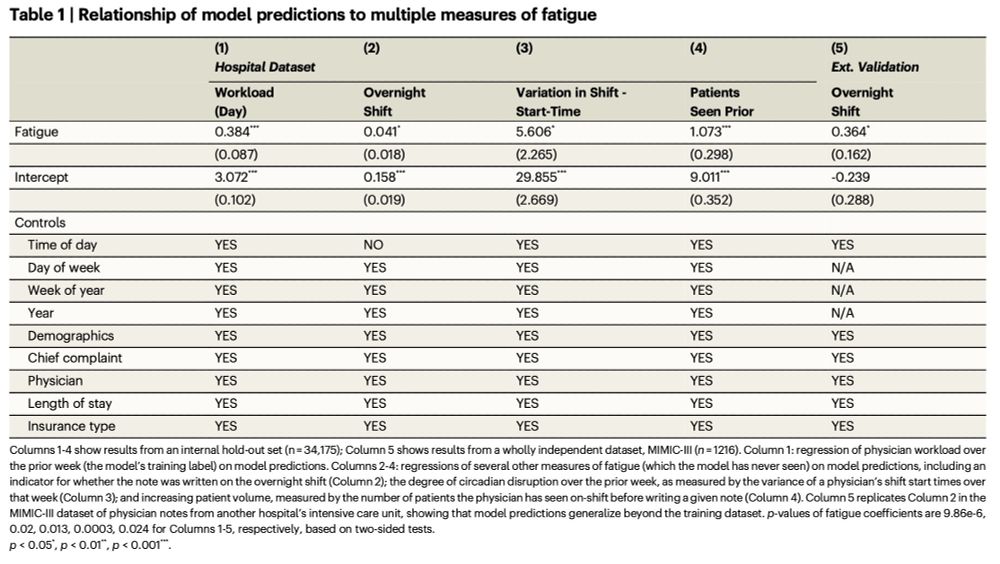
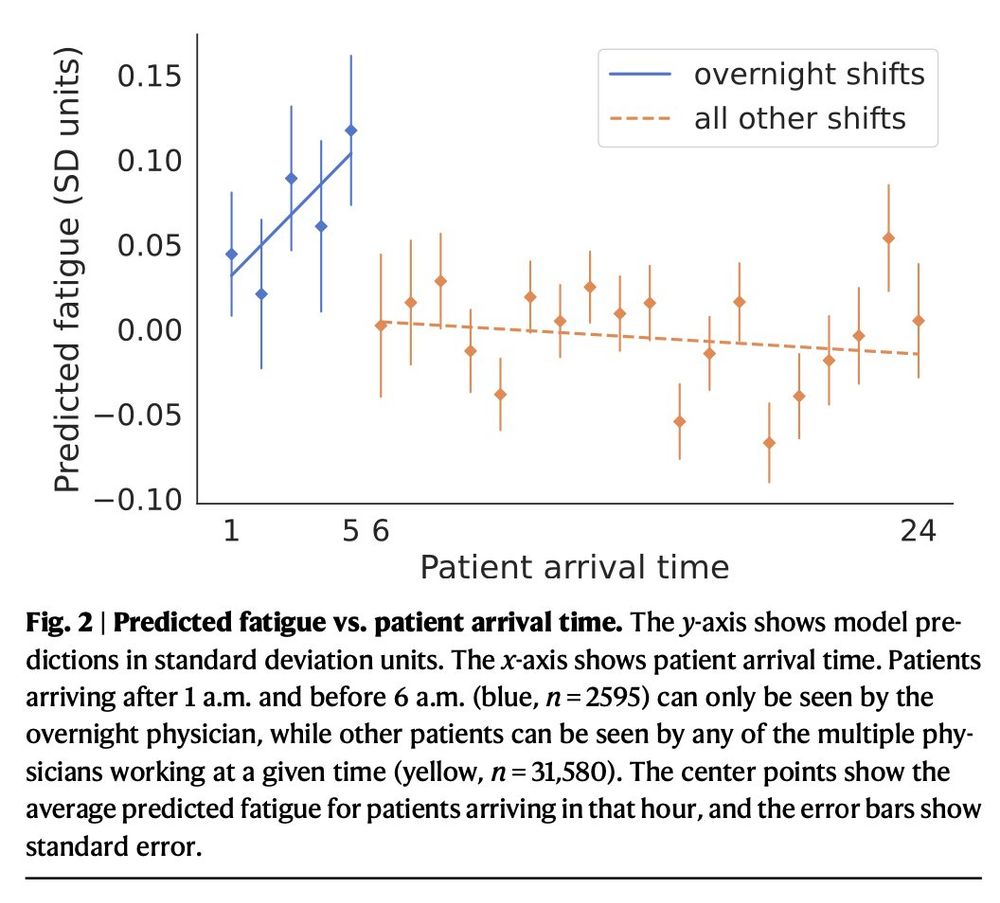

Mourad Heddaya
@mheddaya.bsky.social
· May 1




Mourad Heddaya
@mheddaya.bsky.social
· May 1

Reposted by Mourad Heddaya
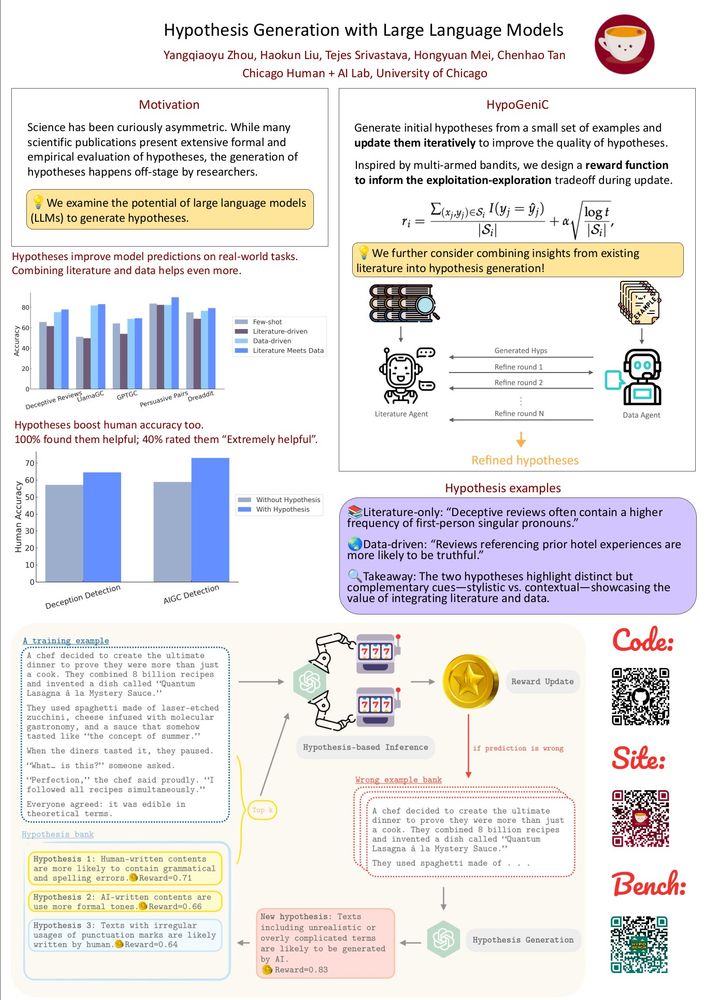
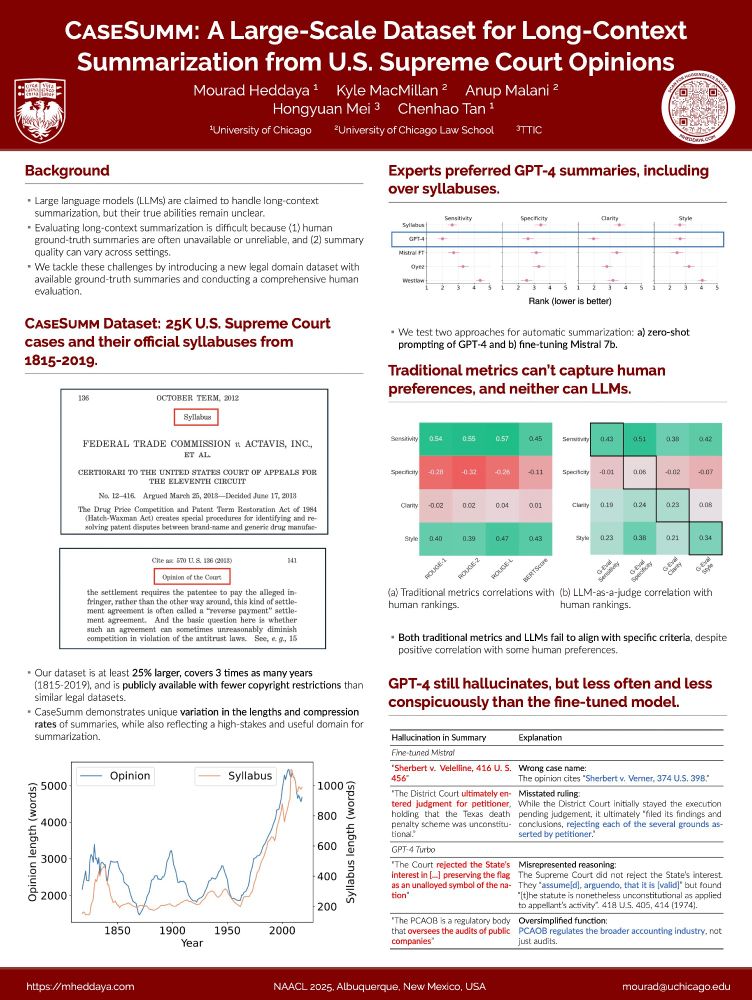

Reposted by Mourad Heddaya

Dang Nguyen
@divingwithorcas.bsky.social
· Apr 14
Reposted by Mourad Heddaya


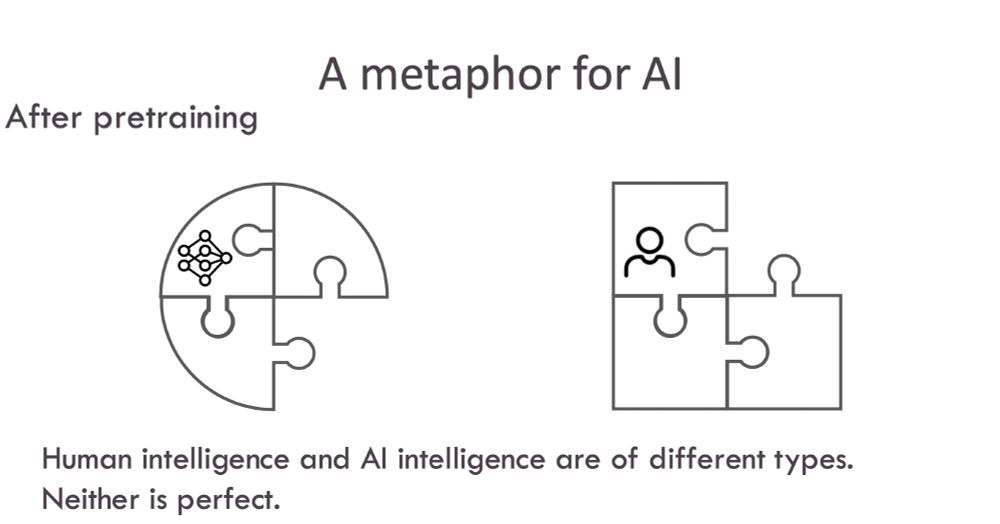

Mourad Heddaya
@mheddaya.bsky.social
· Nov 15

Mourad Heddaya
@mheddaya.bsky.social
· Nov 15
Mourad Heddaya
@mheddaya.bsky.social
· Nov 15
Mourad Heddaya
@mheddaya.bsky.social
· Nov 15




Mourad Heddaya
@mheddaya.bsky.social
· Nov 15
