



@mrtn3000.bsky.social
Reposted

[TikTok / LLM Analysis]
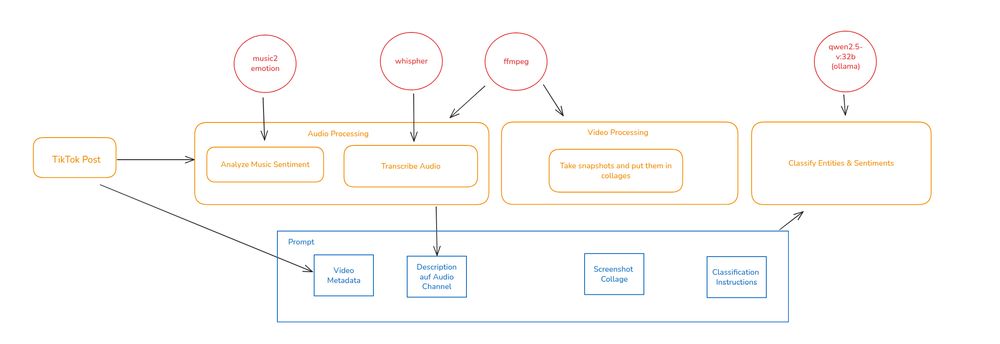
Our resources are limited and I favor local models over intransparent cloud services. So I build a pipeline around Ollama using a Mac with 32GB RAM and an M2 processor to first process the different channels of the posts […]
[Original post on chaos.social]
Our resources are limited and I favor local models over intransparent cloud services. So I build a pipeline around Ollama using a Mac with 32GB RAM and an M2 processor to first process the different channels of the posts […]
[Original post on chaos.social]
October 20, 2025 at 9:29 AM
[TikTok / LLM Analysis]
Our resources are limited and I favor local models over intransparent cloud services. So I build a pipeline around Ollama using a Mac with 32GB RAM and an M2 processor to first process the different channels of the posts […]
[Original post on chaos.social]
Our resources are limited and I favor local models over intransparent cloud services. So I build a pipeline around Ollama using a Mac with 32GB RAM and an M2 processor to first process the different channels of the posts […]
[Original post on chaos.social]
Reposted

⚠️ As TikTok becomes a key space for political engagement, users should know which narratives are amplified—and which might be downplayed.
🔗 Read more: tinyurl.com/rbfjkfmu
🔗 Read more: tinyurl.com/rbfjkfmu

From FYP to WW3
This investigation analyzed the For You Pages of 12 TikTok accounts in the Netherlands during the 2025 NATO Summit, comparing them with search results. FYPs prioritized military content (40%) and war ...
tinyurl.com
October 16, 2025 at 12:11 PM
⚠️ As TikTok becomes a key space for political engagement, users should know which narratives are amplified—and which might be downplayed.
🔗 Read more: tinyurl.com/rbfjkfmu
🔗 Read more: tinyurl.com/rbfjkfmu