




Material Scientist
@mtrl-scientist.bsky.social
Founder
Shitposter
Data wrangler
Shitposter
Data wrangler
Pinned

About myself:
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting

August 3, 2025 at 10:18 AM
I'm pretty sure this is not how you're supposed to use CSI mounts, but hey - it successfully circumvents the limitations of not being able to mount subdirs w/o having to create a volume for each one 😁
#Nomad #Hashistack #CSI #Docker
#Nomad #Hashistack #CSI #Docker
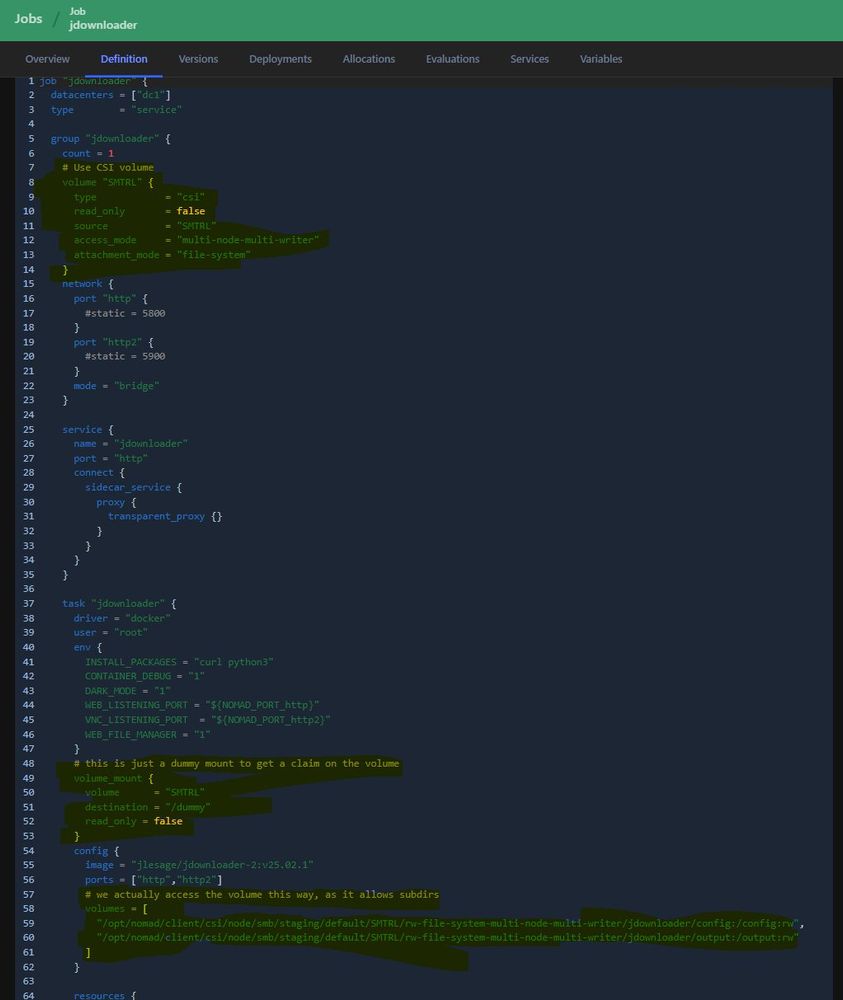
August 3, 2025 at 10:17 AM
I'm pretty sure this is not how you're supposed to use CSI mounts, but hey - it successfully circumvents the limitations of not being able to mount subdirs w/o having to create a volume for each one 😁
#Nomad #Hashistack #CSI #Docker
#Nomad #Hashistack #CSI #Docker
Reposted by Material Scientist

The husband and I went on a moon-date 🥰
Today, we got to see the 'Strawberry Moon' and here is a very short video, so you can witness it too.
@mtrl-scientist.bsky.social
#moongazing #strawberrymoon #fullmoon #seestar #telescope
Today, we got to see the 'Strawberry Moon' and here is a very short video, so you can witness it too.
@mtrl-scientist.bsky.social
#moongazing #strawberrymoon #fullmoon #seestar #telescope
June 11, 2025 at 10:24 PM
The husband and I went on a moon-date 🥰
Today, we got to see the 'Strawberry Moon' and here is a very short video, so you can witness it too.
@mtrl-scientist.bsky.social
#moongazing #strawberrymoon #fullmoon #seestar #telescope
Today, we got to see the 'Strawberry Moon' and here is a very short video, so you can witness it too.
@mtrl-scientist.bsky.social
#moongazing #strawberrymoon #fullmoon #seestar #telescope
Reposted by Material Scientist

“Localhost tracking” explained. It could cost Meta 32 billion.
#Privacy
www.zeropartydata.es/p/localhost-...
#Privacy
www.zeropartydata.es/p/localhost-...

“Localhost tracking” explained. It could cost Meta 32 billion.
You just can't finish off Zuckerberg.
www.zeropartydata.es
June 11, 2025 at 9:07 AM
“Localhost tracking” explained. It could cost Meta 32 billion.
#Privacy
www.zeropartydata.es/p/localhost-...
#Privacy
www.zeropartydata.es/p/localhost-...
Dayum!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!

December 28, 2024 at 2:16 PM
Dayum!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
Docker builds used to take 10min but simply replacing
```sh
python setup.py install
```
with
```sh
uv pip install . --system
```
In my docker file resulted in the build only taking 26s!
@ninasch.bsky.social and I nearly froze our butts off for these last night
Fish head nebula was particularly nice!
Fish head nebula was particularly nice!




December 26, 2024 at 10:38 AM
@ninasch.bsky.social and I nearly froze our butts off for these last night
Fish head nebula was particularly nice!
Fish head nebula was particularly nice!
Every hour of every day!

December 17, 2024 at 7:56 PM
Every hour of every day!
Don't wait around for help to come along. Just do it yourself
December 13, 2024 at 8:34 PM
Don't wait around for help to come along. Just do it yourself

Impulsive decision: midnight Millennium bread 😂
December 11, 2024 at 12:01 AM
Impulsive decision: midnight Millennium bread 😂
When I tickle my wife's feet
December 9, 2024 at 11:25 PM
When I tickle my wife's feet
Oh man...
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
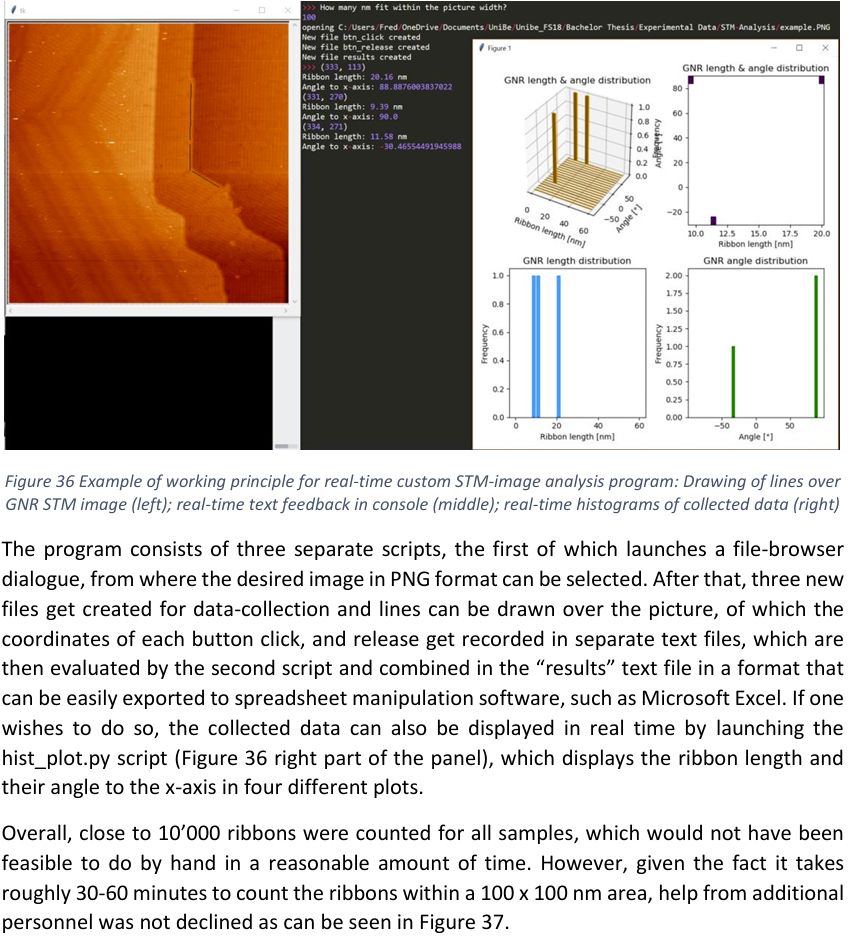
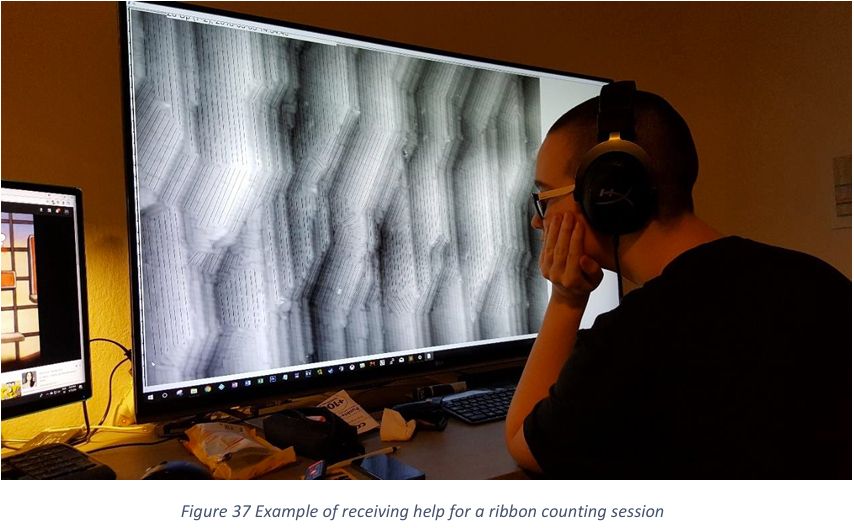
December 7, 2024 at 6:31 PM
Oh man...
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
Was looking up something from old thesis and stumbled across my first time writing a Python GUI, and @ninasch.bsky.social helping to mark nanoribbons 😅
First attempt at astrophotography with Seestar S50
10min integration of pleiades & postprocessing by @ninasch.bsky.social
10min integration of pleiades & postprocessing by @ninasch.bsky.social

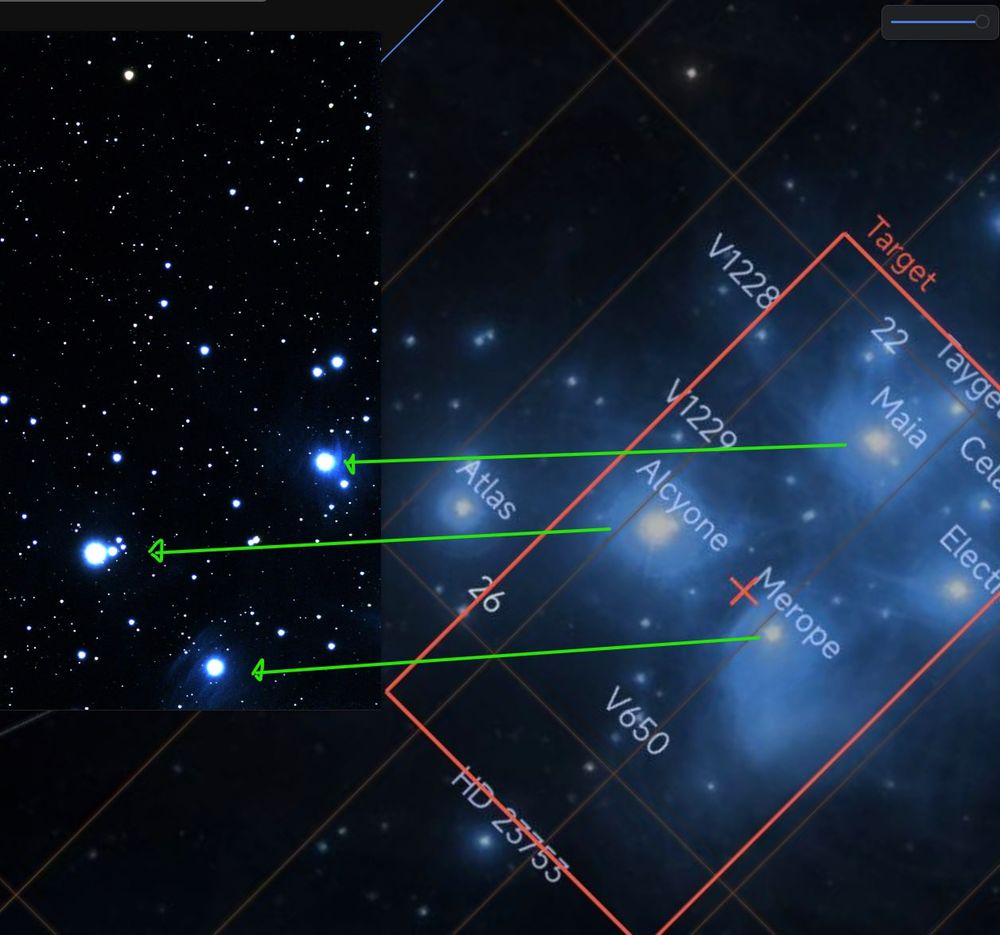
December 5, 2024 at 11:28 PM
First attempt at astrophotography with Seestar S50
10min integration of pleiades & postprocessing by @ninasch.bsky.social
10min integration of pleiades & postprocessing by @ninasch.bsky.social
Reposted by Material Scientist

Seems like a safe bet that object storage as a foundation of data systems architecture is here to stay blog.colinbreck.com/predicting-t...

Predicting the Future of Distributed Systems
There are significant changes happening in distributed systems.
blog.colinbreck.com
November 30, 2024 at 4:31 PM
Seems like a safe bet that object storage as a foundation of data systems architecture is here to stay blog.colinbreck.com/predicting-t...
Reposted by Material Scientist

You can reproduce the napari viz below by running this line in your terminal:
```
uv run pastebin.com/raw/2P6sLi0N
```
Why is this cool?
• super compact for sharing
• uv runs a self-contained script (PEP 723) directly from a URL (please inspect the code first!)
• No virtual environments required
```
uv run pastebin.com/raw/2P6sLi0N
```
Why is this cool?
• super compact for sharing
• uv runs a self-contained script (PEP 723) directly from a URL (please inspect the code first!)
• No virtual environments required

November 25, 2024 at 10:42 PM
You can reproduce the napari viz below by running this line in your terminal:
```
uv run pastebin.com/raw/2P6sLi0N
```
Why is this cool?
• super compact for sharing
• uv runs a self-contained script (PEP 723) directly from a URL (please inspect the code first!)
• No virtual environments required
```
uv run pastebin.com/raw/2P6sLi0N
```
Why is this cool?
• super compact for sharing
• uv runs a self-contained script (PEP 723) directly from a URL (please inspect the code first!)
• No virtual environments required
Every time I want to make a small change and re-build the docker image...

November 25, 2024 at 9:28 PM
Every time I want to make a small change and re-build the docker image...
Here's a Nomad job to:
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance



November 22, 2024 at 10:44 PM
Here's a Nomad job to:
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
- subscribe to Bsky Jetstream
- filter by collections: app.bsky.*
- reset cursor by 30s (in case of restarts)
- filter commit msgs
- use collection as subject name
- create stream
- use CID to deduplicate
- publish to local Jetstream instance
About myself:
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
November 20, 2024 at 11:40 PM
About myself:
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
- Founded Material Indicators in 2019
- Gave up PhD in Materials Science to pursue own business full-time in 2020
- Wearing all hats from data collection, analysis, processing-pipelines, all the way to data serving
- Self-taught & self-hosting
Huh?
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???



November 19, 2024 at 10:21 PM
Huh?
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
Is it possible Kafka just loses segments sometimes?
Pic 1 was live at the time (Kafka local storage).
Pic2 is a replay (Kafka remote storage).
Pic 3 shows that Kafka managed to write meta, but log file is 0 bytes for the missing parts???
"Tiered Storage is prod-ready"
🙌
🙌

🚀 Big month for the Kafka ecosystem!
- Apache Kafka 3.9: Tiered Storage is prod-ready
- Soon: Apache Kafka 4.0: ZooKeeper- & MM1 removed (ETA Feb 2025)
- Jepsen report on Bufstream: a Kafka-compatible engine using S3 & etcd
- AWS launched MSK Express
#ApacheKafka #DataStreaming
- Apache Kafka 3.9: Tiered Storage is prod-ready
- Soon: Apache Kafka 4.0: ZooKeeper- & MM1 removed (ETA Feb 2025)
- Jepsen report on Bufstream: a Kafka-compatible engine using S3 & etcd
- AWS launched MSK Express
#ApacheKafka #DataStreaming
November 18, 2024 at 3:28 PM
"Tiered Storage is prod-ready"
🙌
🙌
This is pretty cool
SeaweedFS allows change-data-capture at the filesystem level.
Using streamz, I can hook into that and basically get a git-like commit-log of which notebooks I worked on at any given point in time.
Since it's an append-only store, I also get versioning.
SeaweedFS allows change-data-capture at the filesystem level.
Using streamz, I can hook into that and basically get a git-like commit-log of which notebooks I worked on at any given point in time.
Since it's an append-only store, I also get versioning.

November 14, 2024 at 1:35 PM
This is pretty cool
SeaweedFS allows change-data-capture at the filesystem level.
Using streamz, I can hook into that and basically get a git-like commit-log of which notebooks I worked on at any given point in time.
Since it's an append-only store, I also get versioning.
SeaweedFS allows change-data-capture at the filesystem level.
Using streamz, I can hook into that and basically get a git-like commit-log of which notebooks I worked on at any given point in time.
Since it's an append-only store, I also get versioning.
Man, so much compute/memory wasted on just deserializing & re-serializing data...
Peaks are 5min apart (1M events for each peak).
Aggregating, since it'll be easier to process downstream.
Peaks are 5min apart (1M events for each peak).
Aggregating, since it'll be easier to process downstream.

November 13, 2024 at 9:35 PM
Man, so much compute/memory wasted on just deserializing & re-serializing data...
Peaks are 5min apart (1M events for each peak).
Aggregating, since it'll be easier to process downstream.
Peaks are 5min apart (1M events for each peak).
Aggregating, since it'll be easier to process downstream.
Anyone else using Nomad?

November 7, 2024 at 9:02 PM
Anyone else using Nomad?
20min interactive analysis they said.
It'll be fun they said.
It'll be fun they said.

November 7, 2024 at 1:23 PM
20min interactive analysis they said.
It'll be fun they said.
It'll be fun they said.