



Reposted

🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N

February 18, 2025 at 12:31 PM
🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
Reposted

WaPo Edito: Be thankful for the applications of AI in medicine.
More accurate detection of cancers (breast, prostate, skin, brain), faster diagnosis of strokes, sepsis, heart attacks, faster MRIs, full-body in 40 minutes.
Much more to come over the next years.
www.washingtonpost.com/opinions/202...
More accurate detection of cancers (breast, prostate, skin, brain), faster diagnosis of strokes, sepsis, heart attacks, faster MRIs, full-body in 40 minutes.
Much more to come over the next years.
www.washingtonpost.com/opinions/202...

November 28, 2024 at 7:54 PM
WaPo Edito: Be thankful for the applications of AI in medicine.
More accurate detection of cancers (breast, prostate, skin, brain), faster diagnosis of strokes, sepsis, heart attacks, faster MRIs, full-body in 40 minutes.
Much more to come over the next years.
www.washingtonpost.com/opinions/202...
More accurate detection of cancers (breast, prostate, skin, brain), faster diagnosis of strokes, sepsis, heart attacks, faster MRIs, full-body in 40 minutes.
Much more to come over the next years.
www.washingtonpost.com/opinions/202...
Reposted
Auto-Regressive LLMs (auto-encoders with causal transformer architectures) and BERT-style models (denoising auto-encoders with transformer archis) are smashing demonstrations of the power of self-supervised (pre-)training.
But they only work for sequences of discrete symbols: language, proteins...
But they only work for sequences of discrete symbols: language, proteins...


November 24, 2024 at 9:44 PM
Auto-Regressive LLMs (auto-encoders with causal transformer architectures) and BERT-style models (denoising auto-encoders with transformer archis) are smashing demonstrations of the power of self-supervised (pre-)training.
But they only work for sequences of discrete symbols: language, proteins...
But they only work for sequences of discrete symbols: language, proteins...
Reposted
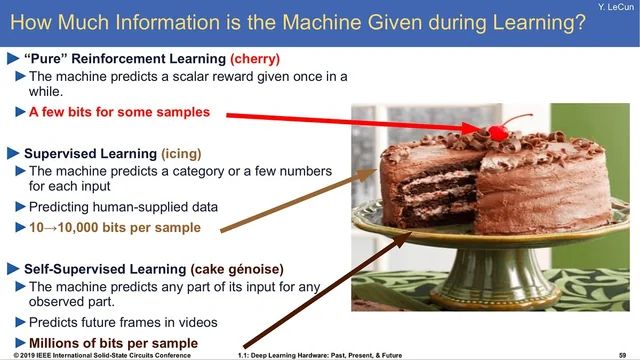
I first showed this "cake" slide in 2016.
Eight years later, Yann LeCun’s cake 🍰 analogy was spot on: self-supervised > supervised > RL
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
November 24, 2024 at 9:35 PM
I first showed this "cake" slide in 2016.