
Nick Vincent
@nickmvincent.bsky.social
290 followers
300 following
69 posts
Studying people and computers (https://www.nickmvincent.com/)
Blogging about data and steering AI (https://dataleverage.substack.com/)
Posts
Media
Videos
Starter Packs
Pinned

Nick Vincent
@nickmvincent.bsky.social
· Nov 19
Nick Vincent
@nickmvincent.bsky.social
· Aug 14


Nick Vincent
@nickmvincent.bsky.social
· Jun 24

On AI-driven Job Apocalypses and Collective Bargaining for Information
Reacting to a fresh wave of discussion about AI's impact on the economy and power concentration, and reiterating the potential role of collective bargaining.
dataleverage.substack.com
Nick Vincent
@nickmvincent.bsky.social
· Jun 24
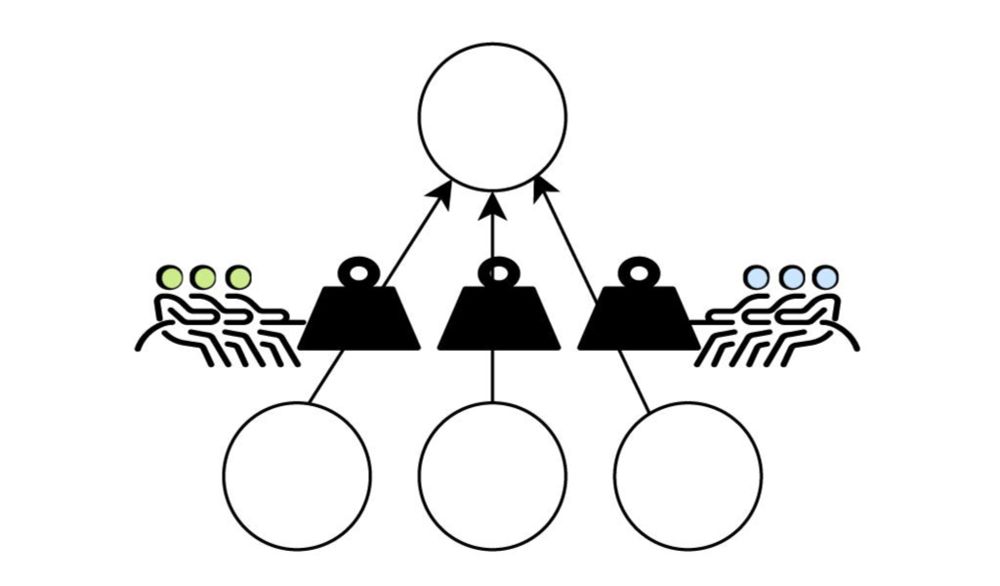
Algorithmic Collective Action With Two Collectives [crosspost]
This post was written by Aditya Karan, with support from Nick Vincent and Karrie Karahalios to accompany a FAccT 2025 paper. It was originally published on Jun 19, 2025 via the Crowd Dynamics Lab blog...
dataleverage.substack.com


Nick Vincent
@nickmvincent.bsky.social
· Jun 24
Nick Vincent
@nickmvincent.bsky.social
· Jun 21
Nick Vincent
@nickmvincent.bsky.social
· May 27
Nick Vincent
@nickmvincent.bsky.social
· May 27

Push and Pull: A Framework for Measuring Attentional Agency on Digital Platforms
We propose a framework for measuring attentional agency, which we define as a user's ability to allocate attention according to their own desires, goals, and intentions on digital platforms that use s...
arxiv.org
Nick Vincent
@nickmvincent.bsky.social
· May 27
Nick Vincent
@nickmvincent.bsky.social
· May 27

Google and TikTok rank bundles of information; ChatGPT ranks grains.
Google and others solve our attentional problem by ranking discrete bundles of information, whereas ChatGPT ranks more granular chunks. This lens can help us reason about AI policy.
dataleverage.substack.com