



Nicolas Espinosa Dice
@nico-espinosa-dice.bsky.social
cs phd student @cornelluniversity.bsky.social. previously @harveymuddcollege.bsky.social. working on reinforcement learning & generative models. https://nico-espinosadice.github.io/
all together, 𝚂𝙾𝚁𝙻 consistently outperforms 10 offline RL baselines on 40 tasks!

June 12, 2025 at 7:39 PM
all together, 𝚂𝙾𝚁𝙻 consistently outperforms 10 offline RL baselines on 40 tasks!
a common issue w/ CoT in LLMs is extrapolating beyond what was optimized during training. 𝚂𝙾𝚁𝙻’s sequential and best-of-N scaling enables *sequential extrapolation*
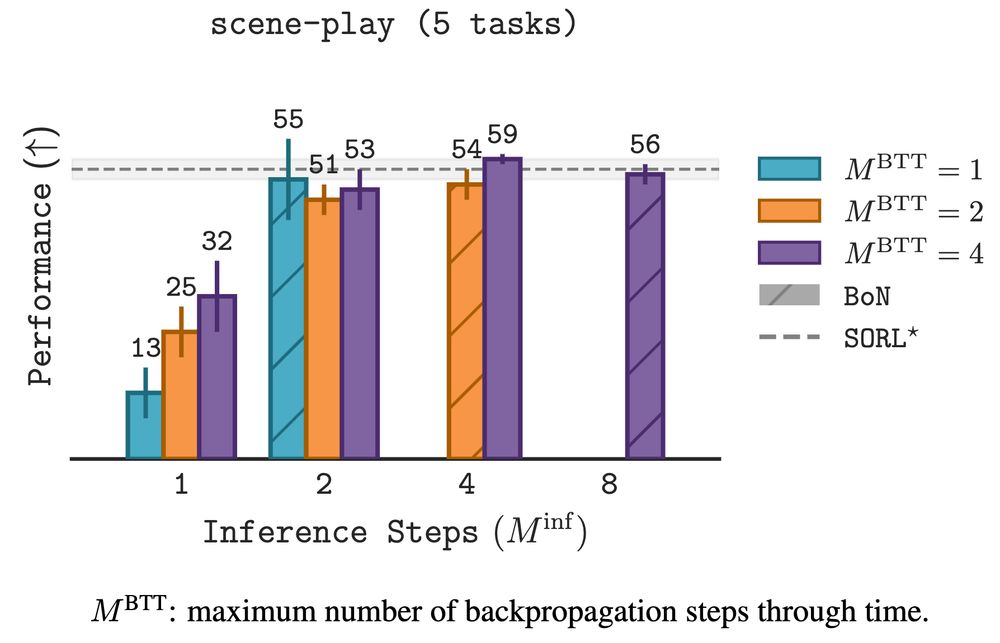
June 12, 2025 at 7:38 PM
a common issue w/ CoT in LLMs is extrapolating beyond what was optimized during training. 𝚂𝙾𝚁𝙻’s sequential and best-of-N scaling enables *sequential extrapolation*
motivated by CoT in LLMs, 𝚂𝙾𝚁𝙻 scales inference *sequentially* by increasing the number of inference steps

June 12, 2025 at 7:38 PM
motivated by CoT in LLMs, 𝚂𝙾𝚁𝙻 scales inference *sequentially* by increasing the number of inference steps
𝚂𝙾𝚁𝙻 leverages @Kevin Frans's shortcut models to incorporate self-consistency into training, allowing the policy to learn “large jumps” that match more-precise “small jumps”
pc: @Kevin Frans
pc: @Kevin Frans

June 12, 2025 at 7:37 PM
𝚂𝙾𝚁𝙻 leverages @Kevin Frans's shortcut models to incorporate self-consistency into training, allowing the policy to learn “large jumps” that match more-precise “small jumps”
pc: @Kevin Frans
pc: @Kevin Frans
by incorporating self-consistency during offline RL training, we unlock three orthogonal directions of scaling:
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)

June 12, 2025 at 7:34 PM
by incorporating self-consistency during offline RL training, we unlock three orthogonal directions of scaling:
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)