




Antoine Chaffin
@nohtow.bsky.social
27, French CS Engineer 💻, PhD in ML 🎓🤖 — Guiding generative models for better synthetic data and building multimodal representations @LightOn
PyLate makes downstream usage easy, but also facilitate training!
You can reproduce this SOTA training with <80 LoC and 2 hours of training and it'll run NanoBEIR during training, report it to W&B and create an informative model card!
Link to the gist: gist.github.com/NohTow/3030f...
You can reproduce this SOTA training with <80 LoC and 2 hours of training and it'll run NanoBEIR during training, report it to W&B and create an informative model card!
Link to the gist: gist.github.com/NohTow/3030f...


April 30, 2025 at 2:42 PM
PyLate makes downstream usage easy, but also facilitate training!
You can reproduce this SOTA training with <80 LoC and 2 hours of training and it'll run NanoBEIR during training, report it to W&B and create an informative model card!
Link to the gist: gist.github.com/NohTow/3030f...
You can reproduce this SOTA training with <80 LoC and 2 hours of training and it'll run NanoBEIR during training, report it to W&B and create an informative model card!
Link to the gist: gist.github.com/NohTow/3030f...
It is also the first model to outperform ColBERT-small on BEIR
While it is bigger, it is still a very lightweight model and benefits from the efficiency of ModernBERT!
Also, it has only been trained on MS MARCO (for late interaction) and should thus generalize pretty well!
While it is bigger, it is still a very lightweight model and benefits from the efficiency of ModernBERT!
Also, it has only been trained on MS MARCO (for late interaction) and should thus generalize pretty well!

April 30, 2025 at 2:42 PM
It is also the first model to outperform ColBERT-small on BEIR
While it is bigger, it is still a very lightweight model and benefits from the efficiency of ModernBERT!
Also, it has only been trained on MS MARCO (for late interaction) and should thus generalize pretty well!
While it is bigger, it is still a very lightweight model and benefits from the efficiency of ModernBERT!
Also, it has only been trained on MS MARCO (for late interaction) and should thus generalize pretty well!
Among all those LLM releases, here is an important retrieval release:
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀

April 30, 2025 at 2:42 PM
Among all those LLM releases, here is an important retrieval release:
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀
Obviously, it comes at a slightly higher cost, but it is also trained with Matryoshka capabilities to reduce the footprint of embeddings
Notably, the performance with dimension 256 is only slightly worse than the base version with full dimension 768
Notably, the performance with dimension 256 is only slightly worse than the base version with full dimension 768

January 14, 2025 at 3:32 PM
Obviously, it comes at a slightly higher cost, but it is also trained with Matryoshka capabilities to reduce the footprint of embeddings
Notably, the performance with dimension 256 is only slightly worse than the base version with full dimension 768
Notably, the performance with dimension 256 is only slightly worse than the base version with full dimension 768
Model link: huggingface.co/lightonai/mo...
ModernBERT-embed-large is trained using the same (two-stage training) recipe as its smaller sibling and expectedly increases the performance, reaching +1.22 in MTEB average
ModernBERT-embed-large is trained using the same (two-stage training) recipe as its smaller sibling and expectedly increases the performance, reaching +1.22 in MTEB average

January 14, 2025 at 3:32 PM
Model link: huggingface.co/lightonai/mo...
ModernBERT-embed-large is trained using the same (two-stage training) recipe as its smaller sibling and expectedly increases the performance, reaching +1.22 in MTEB average
ModernBERT-embed-large is trained using the same (two-stage training) recipe as its smaller sibling and expectedly increases the performance, reaching +1.22 in MTEB average
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!

January 14, 2025 at 3:32 PM
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
Besides versatility, this also highlighted the potential of PyLate
The ModernBERT-base checkpoint achieves 51.3 of BEIR average
This means that we beat e5 in a <45 minutes training on MS MARCO only (using only half of the memory of our 8x100)
The ModernBERT-base checkpoint achieves 51.3 of BEIR average
This means that we beat e5 in a <45 minutes training on MS MARCO only (using only half of the memory of our 8x100)
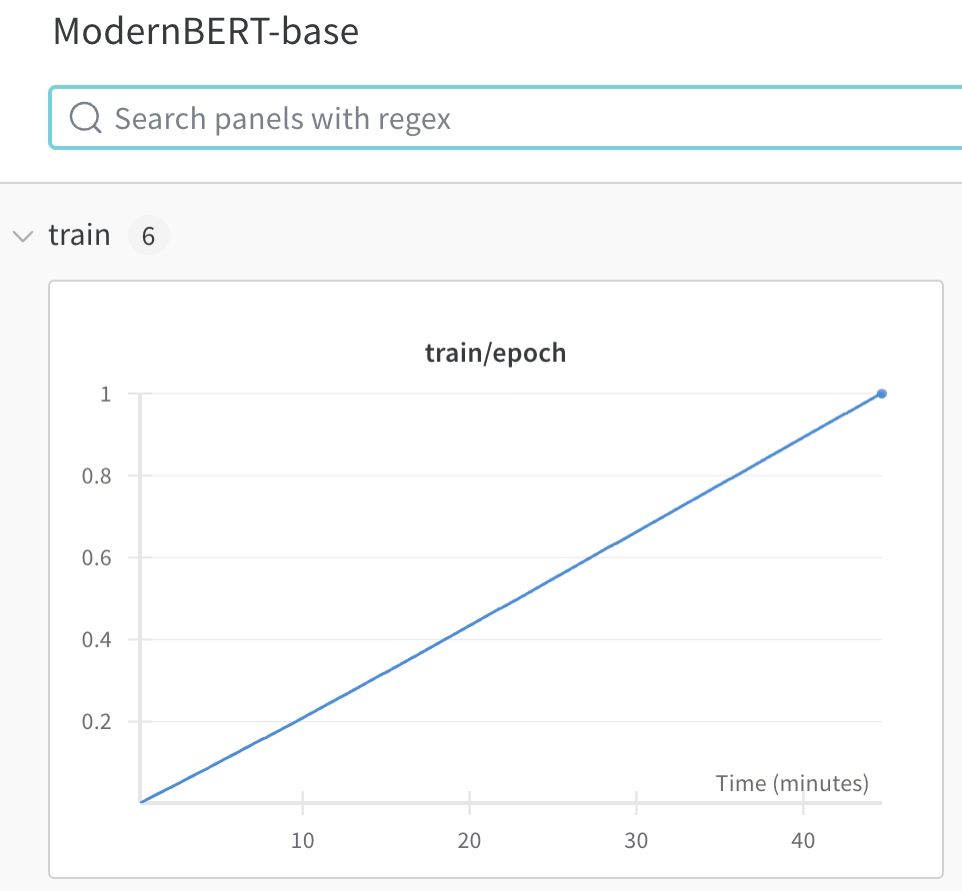

December 19, 2024 at 5:36 PM
Besides versatility, this also highlighted the potential of PyLate
The ModernBERT-base checkpoint achieves 51.3 of BEIR average
This means that we beat e5 in a <45 minutes training on MS MARCO only (using only half of the memory of our 8x100)
The ModernBERT-base checkpoint achieves 51.3 of BEIR average
This means that we beat e5 in a <45 minutes training on MS MARCO only (using only half of the memory of our 8x100)
Starting with my beloved PyLate
We have a lot of experiments on ColBERT models in the paper, with tons of different base models
PyLate handled it all, even models using half-baked remote code
This was a really cool stress test and I am really happy it went so smoothly
We have a lot of experiments on ColBERT models in the paper, with tons of different base models
PyLate handled it all, even models using half-baked remote code
This was a really cool stress test and I am really happy it went so smoothly

December 19, 2024 at 5:36 PM
Starting with my beloved PyLate
We have a lot of experiments on ColBERT models in the paper, with tons of different base models
PyLate handled it all, even models using half-baked remote code
This was a really cool stress test and I am really happy it went so smoothly
We have a lot of experiments on ColBERT models in the paper, with tons of different base models
PyLate handled it all, even models using half-baked remote code
This was a really cool stress test and I am really happy it went so smoothly
We also carefully designed the shapes of the models to optimize inference on common hardware
Coupled to unpadding through the full processing flash attention, this allows ModernBERT to be two to three times faster than most encoders on long-context on a RTX 4090
Coupled to unpadding through the full processing flash attention, this allows ModernBERT to be two to three times faster than most encoders on long-context on a RTX 4090

December 19, 2024 at 5:36 PM
We also carefully designed the shapes of the models to optimize inference on common hardware
Coupled to unpadding through the full processing flash attention, this allows ModernBERT to be two to three times faster than most encoders on long-context on a RTX 4090
Coupled to unpadding through the full processing flash attention, this allows ModernBERT to be two to three times faster than most encoders on long-context on a RTX 4090
There are a lot of details about the architecture in the BP and the paper, but one key architecture design is the use of alternating attention, i.e, attending to the full input only every few layers
This enables fast processing of long sequences while maintaining accuracy
This enables fast processing of long sequences while maintaining accuracy

December 19, 2024 at 5:36 PM
There are a lot of details about the architecture in the BP and the paper, but one key architecture design is the use of alternating attention, i.e, attending to the full input only every few layers
This enables fast processing of long sequences while maintaining accuracy
This enables fast processing of long sequences while maintaining accuracy
These various improvements coupled to a 2T tokens training results in fast and accurate models that handle long context (and code!)
ModernBERT yields state-of-the-art results on various tasks, including IR (short and long context text as well as code) and NLU
ModernBERT yields state-of-the-art results on various tasks, including IR (short and long context text as well as code) and NLU

December 19, 2024 at 5:36 PM
These various improvements coupled to a 2T tokens training results in fast and accurate models that handle long context (and code!)
ModernBERT yields state-of-the-art results on various tasks, including IR (short and long context text as well as code) and NLU
ModernBERT yields state-of-the-art results on various tasks, including IR (short and long context text as well as code) and NLU
I am thrilled to announce the release of ModernBERT, the long-awaited BERT replacement!
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
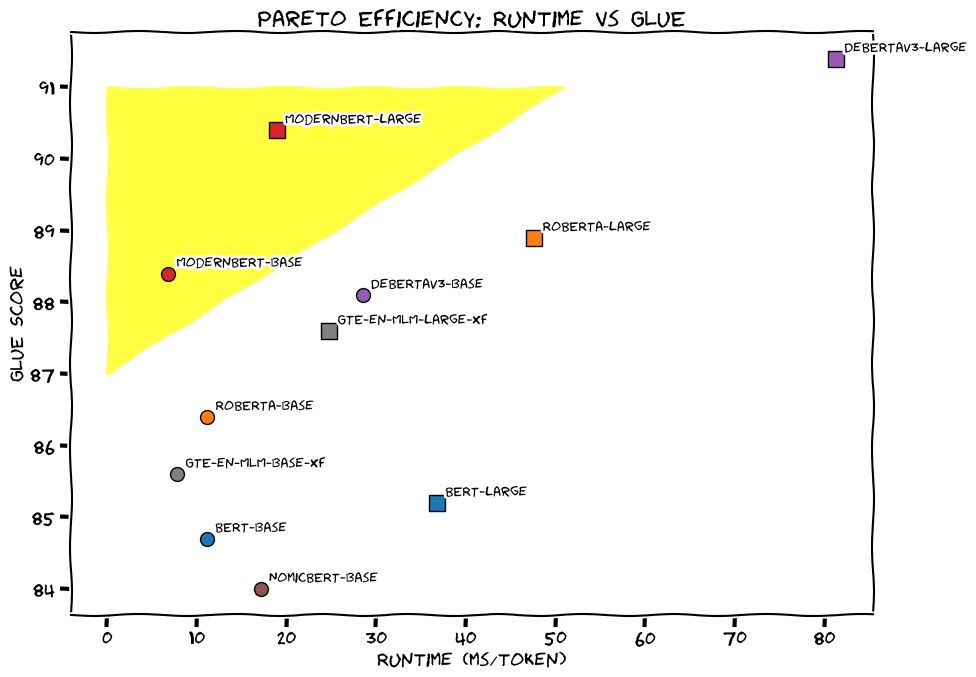
December 19, 2024 at 5:36 PM
I am thrilled to announce the release of ModernBERT, the long-awaited BERT replacement!
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
There might be a few LLM releases per week, but there is only one drop-in replacement that brings Pareto improvements over the 6 years old BERT while going at lightspeed
Wild statement ngl

December 16, 2024 at 6:24 PM
Wild statement ngl