
Paolo Papotti
@papotti.bsky.social
840 followers
290 following
66 posts
Associate Prof at EURECOM and 3IA Côte d'Azur Chair of Artificial Intelligence. ELLIS member.
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
Posts
Media
Videos
Starter Packs
Reposted by Paolo Papotti


Reposted by Paolo Papotti



Paolo Papotti
@papotti.bsky.social
· Jun 2
Paolo Papotti
@papotti.bsky.social
· Jun 2
Paolo Papotti
@papotti.bsky.social
· Jun 2

Paolo Papotti
@papotti.bsky.social
· Jun 2

RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models
Factuality in Large Language Models (LLMs) is a persistent challenge. Current benchmarks often assess short factual answers, overlooking the critical ability to generate structured, multi-record tabul...
arxiv.org
Paolo Papotti
@papotti.bsky.social
· Jun 1
Paolo Papotti
@papotti.bsky.social
· Jun 1
Paolo Papotti
@papotti.bsky.social
· Jun 1

Reposted by Paolo Papotti


Paolo Papotti
@papotti.bsky.social
· May 5




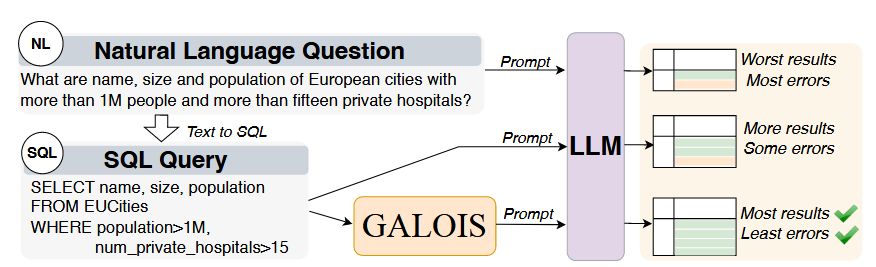
Paolo Papotti
@papotti.bsky.social
· Apr 30

Paolo Papotti
@papotti.bsky.social
· Apr 29
Paolo Papotti
@papotti.bsky.social
· Apr 29
