
Paul Bogdan
@pbogdan.bsky.social
120 followers
110 following
50 posts
Postdoc at Duke in Psychology & Neuroscience.
I have a website: https://pbogdan.com/
Posts
Media
Videos
Starter Packs

Paul Bogdan
@pbogdan.bsky.social
· Aug 27
Paul Bogdan
@pbogdan.bsky.social
· Aug 25
Paul Bogdan
@pbogdan.bsky.social
· Aug 25
Paul Bogdan
@pbogdan.bsky.social
· Jun 24
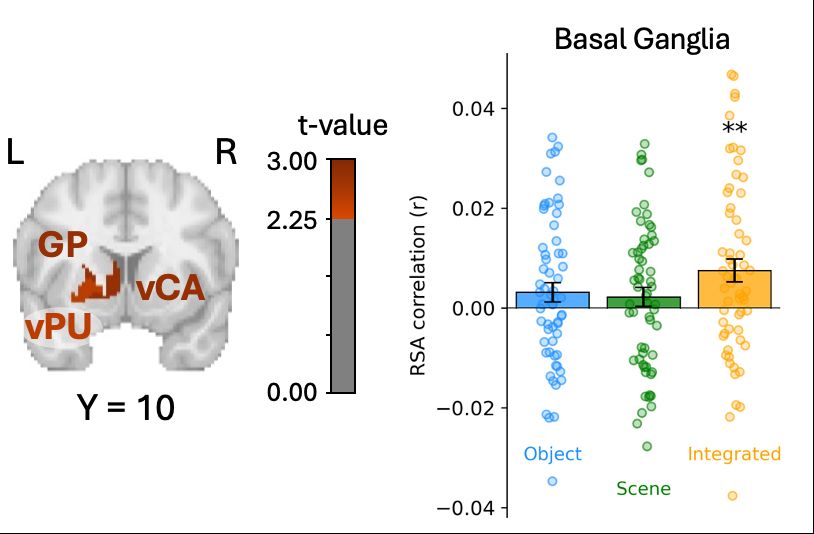
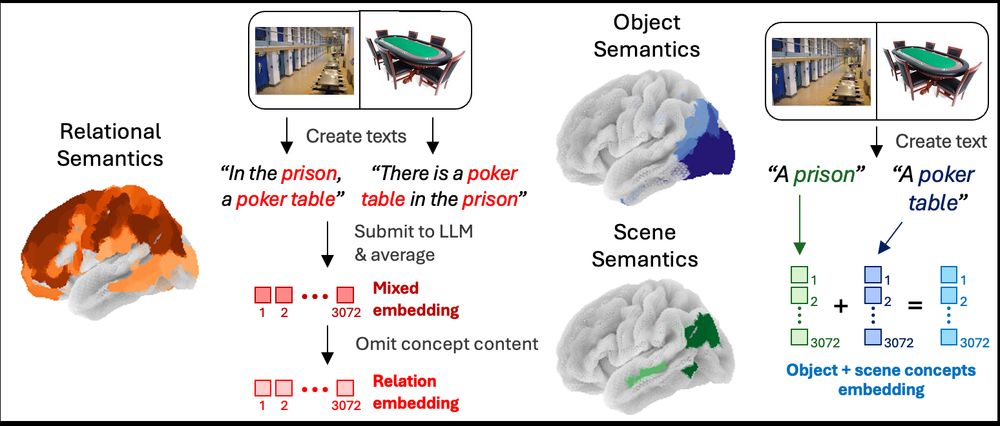
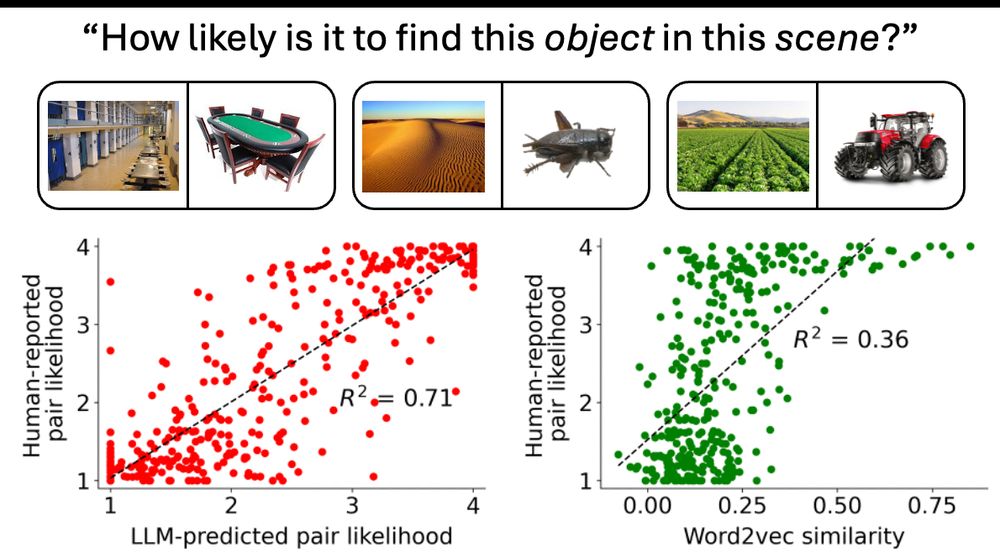
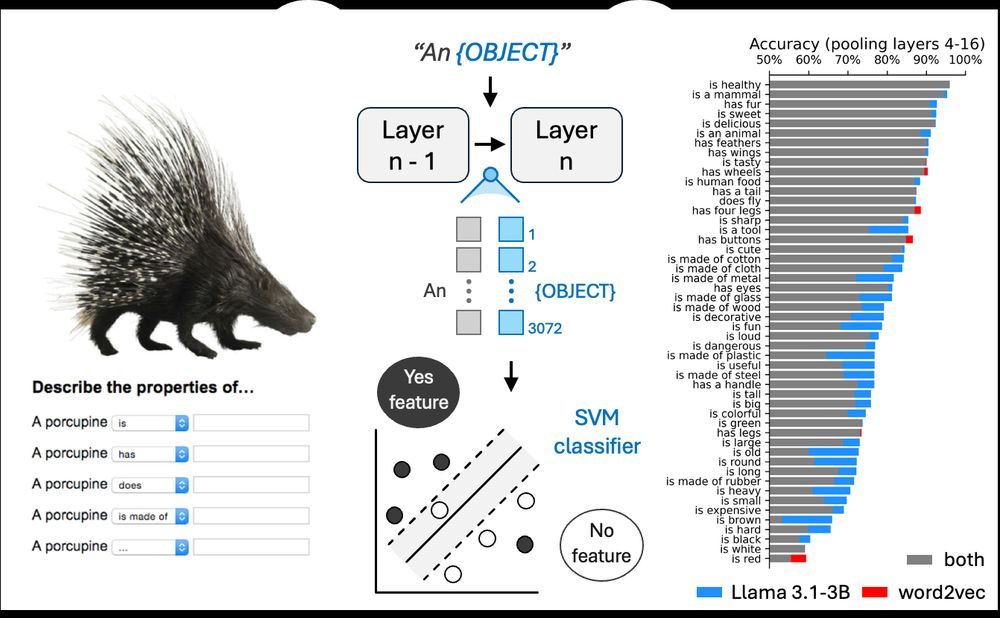
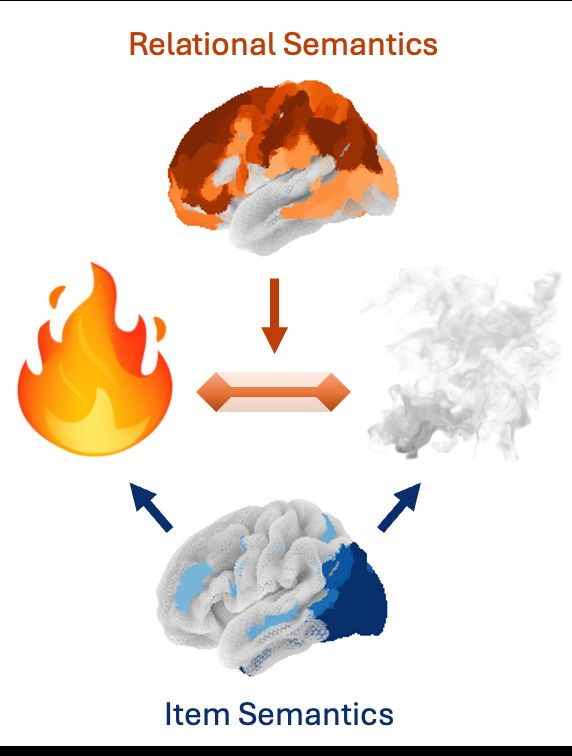
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10


Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
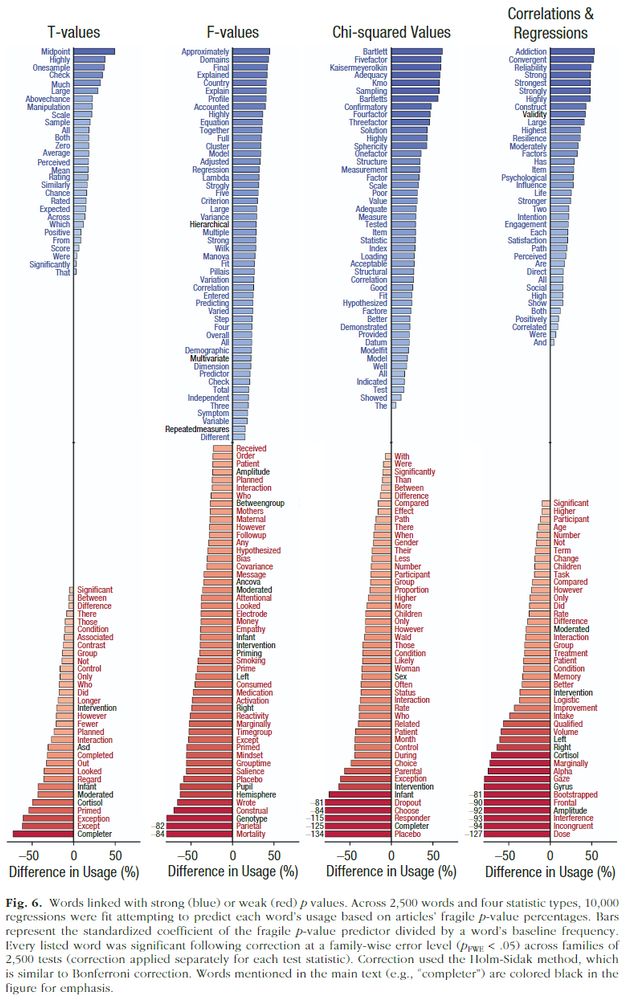
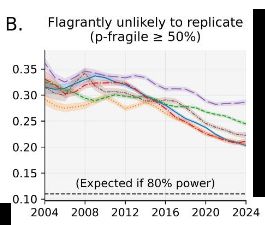
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
Paul Bogdan
@pbogdan.bsky.social
· Jun 10
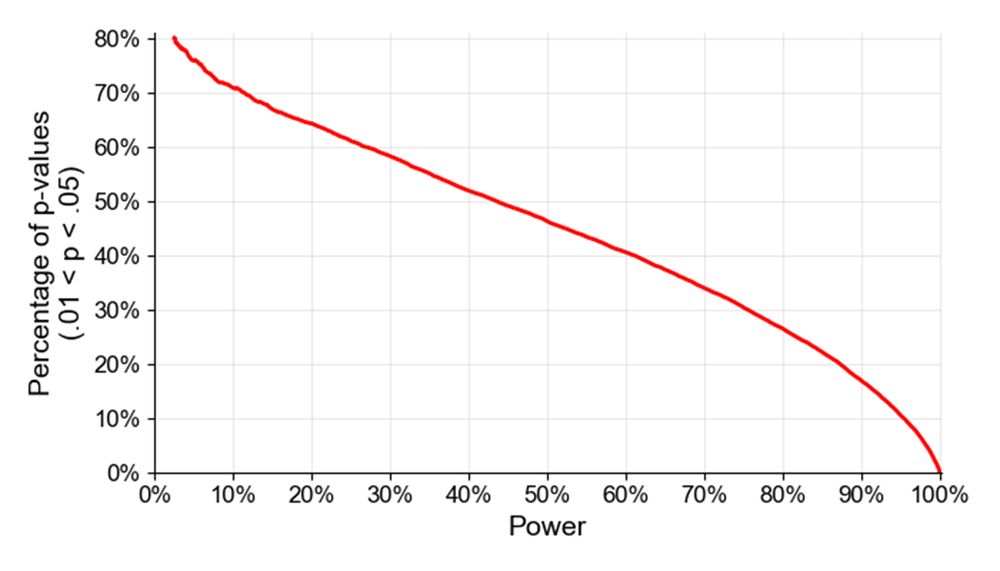
Paul Bogdan
@pbogdan.bsky.social
· Jun 10