


Paul Keen
@pftg.ruby.social.ap.brid.gy
Fractional CTO, OpenSource Contributor. Help non-tech founders deliver SAAS apps that scale
[bridged from https://ruby.social/@pftg on the fediverse by https://fed.brid.gy/ ]
[bridged from https://ruby.social/@pftg on the fediverse by https://fed.brid.gy/ ]
Interesting to find out about local ci aka `bin/ci` appeared in Rails 8.1, when we have had this convention for the last 20 years
https://jetthoughts.com/blog/tldr-move-cicd-scripts-into-automation-devops-productivity/
#rails #rails_8_1 #ruby
https://jetthoughts.com/blog/tldr-move-cicd-scripts-into-automation-devops-productivity/
#rails #rails_8_1 #ruby

TL;DR: Move CI/CD scripts into .automation - JTWay, JetThoughts’ team blog
Today our /bin folder has become overwhelmed with different development tools and scripts. We put...
jetthoughts.com
September 6, 2025 at 1:27 AM
Interesting to find out about local ci aka `bin/ci` appeared in Rails 8.1, when we have had this convention for the last 20 years
https://jetthoughts.com/blog/tldr-move-cicd-scripts-into-automation-devops-productivity/
#rails #rails_8_1 #ruby
https://jetthoughts.com/blog/tldr-move-cicd-scripts-into-automation-devops-productivity/
#rails #rails_8_1 #ruby
🎉 ViewComponent 4.0.0 is here!
After 2 years since v3 🚀
✨ Key highlights:
Removes ActionView::Base dependency
Requires Rails 7.1+ & Ruby 3.2+
New SystemSpecHelpers for RSpec
around_render lifecycle method
Reached feature maturity
#rails #ViewComponent #ruby #webdev […]
After 2 years since v3 🚀
✨ Key highlights:
Removes ActionView::Base dependency
Requires Rails 7.1+ & Ruby 3.2+
New SystemSpecHelpers for RSpec
around_render lifecycle method
Reached feature maturity
#rails #ViewComponent #ruby #webdev […]
Original post on ruby.social
ruby.social
July 30, 2025 at 10:48 AM
🎉 ViewComponent 4.0.0 is here!
After 2 years since v3 🚀
✨ Key highlights:
Removes ActionView::Base dependency
Requires Rails 7.1+ & Ruby 3.2+
New SystemSpecHelpers for RSpec
around_render lifecycle method
Reached feature maturity
#rails #ViewComponent #ruby #webdev […]
After 2 years since v3 🚀
✨ Key highlights:
Removes ActionView::Base dependency
Requires Rails 7.1+ & Ruby 3.2+
New SystemSpecHelpers for RSpec
around_render lifecycle method
Reached feature maturity
#rails #ViewComponent #ruby #webdev […]
Mira Murati's Thinking Machines just raised $2B at $12B valuation with no product. The AI game has new rules.
#ai #startups #tech https://www.reuters.com/technology/mira-muratis-ai-startup-thinking-machines-raises-2-billion-a16z-led-round-2025-07-15/
#ai #startups #tech https://www.reuters.com/technology/mira-muratis-ai-startup-thinking-machines-raises-2-billion-a16z-led-round-2025-07-15/
July 15, 2025 at 7:53 PM
Mira Murati's Thinking Machines just raised $2B at $12B valuation with no product. The AI game has new rules.
#ai #startups #tech https://www.reuters.com/technology/mira-muratis-ai-startup-thinking-machines-raises-2-billion-a16z-led-round-2025-07-15/
#ai #startups #tech https://www.reuters.com/technology/mira-muratis-ai-startup-thinking-machines-raises-2-billion-a16z-led-round-2025-07-15/
Rails Engines > microservices? This Active Storage Dashboard shows how to build modular Rails apps without the complexity. Simple. Powerful.
#rails #activestorage #rubyonrails https://www.panasiti.me/blog/modular-rails-applications-rails-engines-active-storage-dashboard/
#rails #activestorage #rubyonrails https://www.panasiti.me/blog/modular-rails-applications-rails-engines-active-storage-dashboard/
Building Modular Rails Applications: A Deep Dive into Rails Engines Through Active Storage Dashboard | Giovanni Panasiti - Personal Website and Blog
I’ve been building Rails applications for the last 10 years on a daily base and almost all of them use active storage now. Users are uploading files and then...
www.panasiti.me
July 14, 2025 at 9:20 PM
Rails Engines > microservices? This Active Storage Dashboard shows how to build modular Rails apps without the complexity. Simple. Powerful.
#rails #activestorage #rubyonrails https://www.panasiti.me/blog/modular-rails-applications-rails-engines-active-storage-dashboard/
#rails #activestorage #rubyonrails https://www.panasiti.me/blog/modular-rails-applications-rails-engines-active-storage-dashboard/
Swiss academic powerhouses building a truly open LLM that speaks 1000+ languages. No black boxes. No API fees. Complete transparency.
#opensource #ai #ml https://ethz.ch/en/news-and-events/eth-news/news/2025/07/a-language-model-built-for-the-public-good.html
#opensource #ai #ml https://ethz.ch/en/news-and-events/eth-news/news/2025/07/a-language-model-built-for-the-public-good.html

苏黎世联邦理工学院(ETH Zurich)与洛桑联邦理工学院(EPFL)将联合发布一款基于公共基础设施开发的语言模型(LLM)。
ETH Zurich and EPFL to release a LLM developed on public infrastructure (ethz.ch)
02:45 ↑ 113 HN Points
ethz.ch
July 12, 2025 at 7:14 PM
Swiss academic powerhouses building a truly open LLM that speaks 1000+ languages. No black boxes. No API fees. Complete transparency.
#opensource #ai #ml https://ethz.ch/en/news-and-events/eth-news/news/2025/07/a-language-model-built-for-the-public-good.html
#opensource #ai #ml https://ethz.ch/en/news-and-events/eth-news/news/2025/07/a-language-model-built-for-the-public-good.html
LLM inference in production is hard. Learn real-world tactics for speed, scale, and cost savings.
#ml #LLM #devops https://bentoml.com/llm/
#ml #LLM #devops https://bentoml.com/llm/

Introduction | LLM Inference in Production
A practical handbook for engineers building, optimizing, scaling and operating LLM inference systems in production.
bentoml.com
July 11, 2025 at 11:39 PM
LLM inference in production is hard. Learn real-world tactics for speed, scale, and cost savings.
#ml #LLM #devops https://bentoml.com/llm/
#ml #LLM #devops https://bentoml.com/llm/
Brut: a fresh Ruby framework that ditches MVC for simple classes. Build web apps faster with less code. Docker ready.
#ruby #webdev #devproductivity https://naildrivin5.com/blog/2025/07/08/brut-a-new-web-framework-for-ruby.html
#ruby #webdev #devproductivity https://naildrivin5.com/blog/2025/07/08/brut-a-new-web-framework-for-ruby.html
Brut:一款全新的 Ruby 网页框架
Brut: A New Web Framework for Ruby (naildrivin5.com)
02:03 ↑ 107 HN Points
naildrivin5.com
July 9, 2025 at 7:26 AM
Brut: a fresh Ruby framework that ditches MVC for simple classes. Build web apps faster with less code. Docker ready.
#ruby #webdev #devproductivity https://naildrivin5.com/blog/2025/07/08/brut-a-new-web-framework-for-ruby.html
#ruby #webdev #devproductivity https://naildrivin5.com/blog/2025/07/08/brut-a-new-web-framework-for-ruby.html
Terminal-based AI coding that works with any model? opencode is the open-source agent you need in your toolkit. #devtools #opensource #ai https://github.com/sst/opencode

opencode:专为终端打造的人工智能编码代理
Opencode: AI coding agent, built for the terminal (github.com)
01:26 ↑ 103 HN Points
github.com
July 7, 2025 at 12:38 PM
Terminal-based AI coding that works with any model? opencode is the open-source agent you need in your toolkit. #devtools #opensource #ai https://github.com/sst/opencode
AI success depends on context, not just prompts. Context Engineering is the new skill to master. Good context = better AI.
#ai #devskills #LLM https://www.philschmid.de/context-engineering
#ai #devskills #LLM https://www.philschmid.de/context-engineering
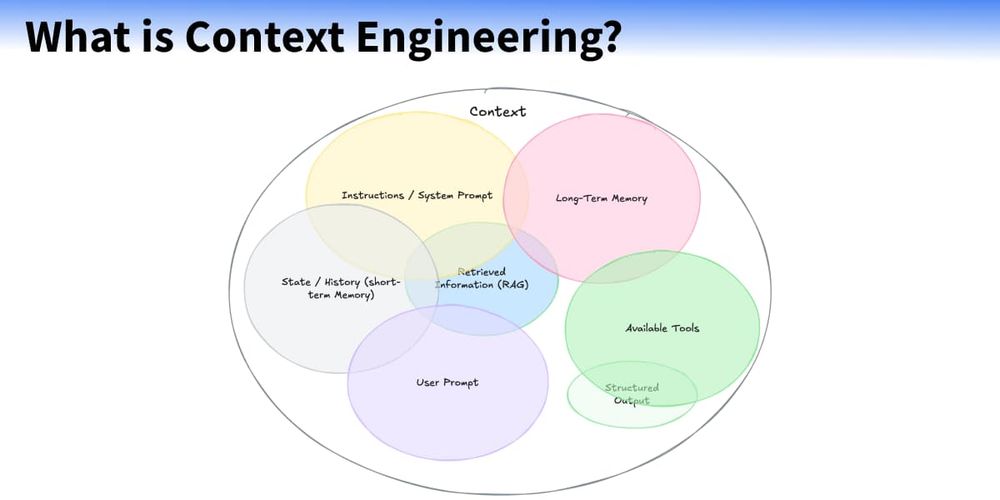
人工智能的新技能不是提示,而是情境工程
The New Skill in AI Is Not Prompting, It''s Context Engineering (www.philschmid.de)
04:53 ↑ 152 HN Points
www.philschmid.de
July 1, 2025 at 7:13 PM
AI success depends on context, not just prompts. Context Engineering is the new skill to master. Good context = better AI.
#ai #devskills #LLM https://www.philschmid.de/context-engineering
#ai #devskills #LLM https://www.philschmid.de/context-engineering
Build secure containers from untrusted code. Depot API isolates projects and speeds up builds with smart caching. Security without headaches.
#devops #security #containers https://depot.dev/blog/container-security-at-scale-building-untrusted-images-safely
#devops #security #containers https://depot.dev/blog/container-security-at-scale-building-untrusted-images-safely

Container security at scale: Building untrusted images safely
Many SaaS platforms need to run customer code securely and fast. Rather than building container infrastructure from scratch, you can use Depot's API to handle the heavy lifting. Here's how to build Go tooling that creates isolated projects, manages builds, and tracks metrics for your customer workloads.
depot.dev
June 30, 2025 at 12:47 PM
Build secure containers from untrusted code. Depot API isolates projects and speeds up builds with smart caching. Security without headaches.
#devops #security #containers https://depot.dev/blog/container-security-at-scale-building-untrusted-images-safely
#devops #security #containers https://depot.dev/blog/container-security-at-scale-building-untrusted-images-safely
vLLM makes your LLMs fly with smart memory tricks and dynamic batching. Your production AI just got a speed boost.
#LLM #performance #devops https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
#LLM #performance #devops https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
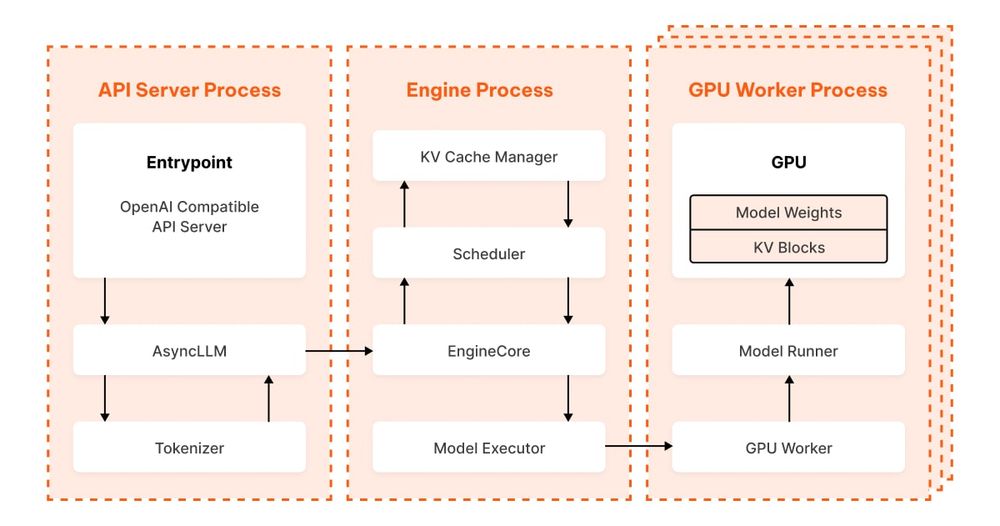
Life of an inference request (vLLM V1): How LLMs are served efficiently at scale
Comments
www.ubicloud.com
June 29, 2025 at 4:12 PM
vLLM makes your LLMs fly with smart memory tricks and dynamic batching. Your production AI just got a speed boost.
#LLM #performance #devops https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
#LLM #performance #devops https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
Apple's AI uses forgotten Normalizing Flows to build image models that run on your device, not the cloud.
#ai #mobilecomputing #machinelearning https://9to5mac.com/2025/06/23/apple-ai-image-model-research-tarflow-starflow/
#ai #mobilecomputing #machinelearning https://9to5mac.com/2025/06/23/apple-ai-image-model-research-tarflow-starflow/
Apple Research is generating images with a forgotten AI technique - 9to5Mac
Apple’s latest research hints that a long-forgotten AI technique could have new potential for generating images. Here’s the breakdown.
9to5mac.com
June 27, 2025 at 7:22 AM
Apple's AI uses forgotten Normalizing Flows to build image models that run on your device, not the cloud.
#ai #mobilecomputing #machinelearning https://9to5mac.com/2025/06/23/apple-ai-image-model-research-tarflow-starflow/
#ai #mobilecomputing #machinelearning https://9to5mac.com/2025/06/23/apple-ai-image-model-research-tarflow-starflow/
Build AI apps in Claude with zero deployment. Users pay for API costs. Just describe your app and share the link. #ai #nocode #devtools https://www.anthropic.com/news/claude-powered-artifacts

使用 Claude 构建和托管人工智能驱动的应用程序--无需部署
Build and Host AI-Powered Apps with Claude – No Deployment Needed (www.anthropic.com)
01:14 ↑ 108 HN Points
www.anthropic.com
June 26, 2025 at 2:29 PM
Build AI apps in Claude with zero deployment. Users pay for API costs. Just describe your app and share the link. #ai #nocode #devtools https://www.anthropic.com/news/claude-powered-artifacts
AI won't replace developers. It will amplify us. Now is the perfect time to learn coding and help solve real problems.
#softwaredev #ai #tech https://substack.com/home/post/p-165655726
#softwaredev #ai #tech https://substack.com/home/post/p-165655726

现在可能是学习软件开发的最佳时机
Now might be the best time to learn software development (substack.com)
06-17 ↑ 104 HN Points
substack.com
June 18, 2025 at 4:23 PM
AI won't replace developers. It will amplify us. Now is the perfect time to learn coding and help solve real problems.
#softwaredev #ai #tech https://substack.com/home/post/p-165655726
#softwaredev #ai #tech https://substack.com/home/post/p-165655726
This OCR model turns document images into clean markdown with tables, LaTeX and more. Your LLMs will thank you. #ocr #ml #devtools https://huggingface.co/nanonets/Nanonets-OCR-s

nanonets/Nanonets-OCR-s · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
June 16, 2025 at 1:37 PM
This OCR model turns document images into clean markdown with tables, LaTeX and more. Your LLMs will thank you. #ocr #ml #devtools https://huggingface.co/nanonets/Nanonets-OCR-s
AlphaWrite uses evolution to make LLMs more creative. Survival of the fittest text - pure genius for scaling generation quality.
#ai #LLM #evolution https://tobysimonds.com/research/2025/06/06/AlphaWrite.html
#ai #LLM #evolution https://tobysimonds.com/research/2025/06/06/AlphaWrite.html
AlphaWrite: Inference time compute Scaling for Writing
You can try AlphaWrite out here **Code Repository** : AlphaWrite on GitHub
Large Language Models have demonstrated remarkable performance improvements through increased inference-time compute, particularly in mathematics and coding. However, the creative domain—where outputs are inherently highly subjective and difficult to evaluate—has seen limited exploration of systematic approaches to scale inference-time compute effectively.
In this work, we introduce Alpha Writing, a novel framework for scaling inference-time compute in creative text generation. Inspired by AlphaEvolve and other evolutionary algorithms, our approach combines iterative story generation with Elo-based evaluation to systematically improve narrative quality. Rather than relying on single-shot generation or simple resampling, Alpha Writing creates a dynamic ecosystem where stories compete, evolve, and improve through multiple generations.
Our method addresses a critical gap in the field: while we can easily scale compute for tasks with clear correctness criteria, creative domains have lacked principled approaches for leveraging additional inference resources. By treating story generation as an evolutionary process guided by pairwise preferences, we demonstrate that creative output quality can be systematically improved through increased compute allocation.
We further demonstrate the scalability of these methods by distilling the enhanced stories back into the base model, creating a stronger foundation for subsequent rounds of Alpha Writing. This recursive cycle—where improved outputs become training data for an enhanced model that can generate even better stories—offers promising potential for self improving writing models.
# Methodology
## Overview
Alpha Writing employs an evolutionary approach to improve story quality through iterative generation and selection. The process consists of four main stages: (1) diverse initial story generation, (2) pairwise comparison using Elo rankings, and (3) evolutionary refinement of top-performing stories. (2) and (3) are repeated for multiple generations to progressively enhance narrative quality.
## Initial Story Generation
To establish a diverse starting population, we generate a large corpus of initial stories with systematic variation. Each story is generated with two randomized parameters:
* **Author style** : The model is prompted to write in the style of different authors
* **Theme** : Each generation focuses on a different narrative theme
This approach ensures broad exploration of the creative space and prevents early convergence on a single narrative style or structure.
## Judging and Elo Ranking
Stories are evaluated through pairwise comparisons using an LLM judge. The judge is provided with:
* A detailed evaluation rubric focusing on narrative quality metrics
* Two stories to compare
* Instructions to select the superior story
The rubric improves consistency in judgments by providing clear evaluation criteria. Based on these pairwise comparisons, we update Elo ratings for each story, creating a dynamic ranking system that captures relative quality differences. We use base Elo of 1200 and K-factor of 32. For our experiments we use the same model as the judge and generator
## Story Evolution
After establishing rankings through pairwise comparisons, we implement an evolutionary process to iteratively improve story quality:
**1. Selection** : Select top-performing stories as foundation for next generation
**2. Variation Generation** : Generate variants using randomly sampled improvement objectives (narrative structure, character development, emotional resonance, dialogue, thematic depth, descriptive detail, plot tension, prose style). Random sampling maintains creative diversity.
**3. Population Update** : Retain high-performers, replace lower-ranked stories with variants
**4. Re-ranking** : Fresh pairwise comparisons on updated population
**5. Iteration** : Repeat across generations, allowing successful elements to propagate
## Evaluation Protocol
Evaluating creative output presents significant challenges due to subjective preferences and high variance in story content. Our evaluation approach includes:
* **Model selection** : Focus on smaller models where improvements are more pronounced
* **Story length** : Restrict to stories under 500 words to enable easier comparison
* **Prompt design** : Use open-ended prompts to allow models to demonstrate narrative crafting abilities
* **Data collection** : 120 preference comparisons per experiment to establish statistical significance
* **Evaluation Protocol:** Evaluators same rubric we use for LLM judge to score which of the two responses they prefer
Initial generations often exhibited fundamental narrative issues including poor story arcs and structural problems, making improvements through evolution particularly noticeable. We compare performance against initial model-generated stories and stories improved through repeated prompting.
We acknowledge that our evaluation methodology, while establishing statistically significant improvements, would benefit from more comprehensive data collection. We simply seek to demonstrate a statistically significant signal that this method works - quantifiying the actual improvement is difficult and would require significantly more diverse data colleciton
We found quality differences were subtle in opening lines but became pronounced in longer stories, where structural coherence and narrative flow showed clear improvement. However, evaluating these stories remains genuinely difficult—they diverge so dramatically in theme, style, and approach that determining which is “better” becomes largely subjective and dependent on reader preference.
### Results
For evaluation we used Llama 3.1 8B and generated 60 initial stories, selected the top 5 performers, and created 5 variants of each. This evolution process was repeated for 5 generations
Alpha Writing demonstrates substantial improvements in story quality when evaluated through pairwise human preferences. Testing with Llama 3.1 8B revealed:
* **72% preference rate** over initial story generations (95 % CI 63 % – 79 %)
* **62% preference rate** over sequential-prompting baseline (95 % CI 53 % – 70 %)
These results indicate that the evolutionary approach significantly outperforms both single-shot generation and traditional inference-time scaling methods for creative writing tasks.
# Recursive Self-Improvement Through AlphaWrite Distillation
An intriguing possibility emerges when considering inference scaling techniques like AlphaEvolve or AlphaWrite: could we create a self improving loop through using inference scaling to improve results then distill back down and repeat?
## The Core Concept
The process would work as follows:
1. Apply AlphaWrite techniques to generate improved outputs from the current model
2. Distill these enhanced outputs back into training data for the base model
3. Reapply AlphaWrite techniques to this improved base, continuing the cycle
## Experiments
We explored this concept through preliminary testing:
* **Generation Phase** : Ran AlphaWrite with 60 initial questions, top 5 questions per batch, 5 variations of each for 5 generations. Ran process 10 times generating 50 stories in total
* **Selection** : Identified the top 10 highest-quality stories of the final batch
* **Fine-tuning** : Used these curated stories to fine-tune Llama 3.1 8B
* **Iteration** : Repeated the process with the enhanced model
This recursive approach theoretically enables continuous self-improvement, where each iteration builds upon the strengths of the previous generation, potentially leading to increasingly sophisticated capabilities without additional human-generated training data.
## Results
We observed a 56% (95 % CI 47 % – 65 %) preference rate over the base model. While this improvement falls within the statistical significance range for this experiment, collecting sufficient preference data to achieve statistical significance would be prohibitively expensive.
## Limitations
**Prompt Sensitivity** : The quality and diversity of generated stories are highly dependent on the specific prompts used. Our choice of author styles and themes introduces inherent bias that may favor certain narrative approaches over others. Different prompt sets could yield substantially different results.
**Evaluation Challenges** : The subjective nature of creative quality makes definitive assessment difficult. Our 120 preference comparisons represent a small sample of possible reader preferences.
**Convergence Risks** : Extended evolution could lead to homogenization, where stories converge on particular “winning” formulas rather than maintaining true creative diversity. We observed early signs of this in later generations.
### Beyond Creative Writing
The Alpha Writing framework extends far beyond narrative fiction. We’ve already employed it in drafting sections of this paper, demonstrating its versatility across writing domains. The approach can be adapted for:
**Targeted Generation** : By incorporating specific rubrics, Alpha Writing can optimize individual components of larger works—generating compelling introductions, crafting precise technical explanations, or developing persuasive conclusions. This granular control enables writers to iteratively improve specific weaknesses in their work.
**Domain-Specific Applications** : The framework naturally adapts to technical documentation, academic writing, marketing copy, and other specialized formats. Each domain simply requires appropriate evaluation criteria and judge training.
**Model Enhancement** : Perhaps most significantly, Alpha Writing offers a systematic approach to improving language models’ general writing capabilities. By generating diverse, high-quality training data through evolutionary refinement, we can potentially bootstrap better foundation models—creating a virtuous cycle where improved models generate even better training data for future iterations.
This positions Alpha Writing not just as a tool for end-users, but as potentially a fundamental technique for advancing the writing capabilities of AI systems themselves.
### Conclusion
Alpha Writing demonstrates that creative tasks can benefit from systematic inference-time compute scaling through evolutionary approaches. Our results show consistent improvements over both baseline generation and sequential prompting methods, suggesting that the apparent intractability of scaling compute for creative domains may be addressable through appropriate algorithmic frameworks.
**Code Repository** : AlphaWrite on GitHub
### Citation
@article{simonds2025alphawrite,
title={AlphaWrite: Inference Time Compute Scaling for Writing},
author={Simonds, Toby},
journal={Tufa Labs Research},
year={2025},
month={June},
url={https://github.com/tamassimonds/AlphaEvolveWritting}
}
tobysimonds.com
June 11, 2025 at 1:28 PM
AlphaWrite uses evolution to make LLMs more creative. Survival of the fittest text - pure genius for scaling generation quality.
#ai #LLM #evolution https://tobysimonds.com/research/2025/06/06/AlphaWrite.html
#ai #LLM #evolution https://tobysimonds.com/research/2025/06/06/AlphaWrite.html
LLMs won't kill Elixir. They'll make it stronger. The path forward is clear: better docs, LLM-friendly libraries, and Elixir-specific training data.
#elixir #LLM #futureOfCoding https://www.zachdaniel.dev/p/llms-and-elixir-windfall-or-deathblow
#elixir #LLM #futureOfCoding https://www.zachdaniel.dev/p/llms-and-elixir-windfall-or-deathblow

LLMs & Elixir: Windfall or Deathblow?
How the Elixir community can survive — and thrive — in an age of LLMs.
www.zachdaniel.dev
June 5, 2025 at 9:49 PM
LLMs won't kill Elixir. They'll make it stronger. The path forward is clear: better docs, LLM-friendly libraries, and Elixir-specific training data.
#elixir #LLM #futureOfCoding https://www.zachdaniel.dev/p/llms-and-elixir-windfall-or-deathblow
#elixir #LLM #futureOfCoding https://www.zachdaniel.dev/p/llms-and-elixir-windfall-or-deathblow
Want to learn TPUs? Check this open-source Python simulator - perfect for getting hands-on with ML hardware! #mlops #python #opensource https://github.com/UCSBarchlab/OpenTPU
OpenTPU: Open-Source Reimplementation of Google Tensor Processing Unit (TPU)
Comments
github.com
May 28, 2025 at 6:46 AM
Want to learn TPUs? Check this open-source Python simulator - perfect for getting hands-on with ML hardware! #mlops #python #opensource https://github.com/UCSBarchlab/OpenTPU
Why does your code feel off? Hynek reveals the hidden forces that shape our architecture decisions. A must-read for better design choices.
#pythondev #softwaredesign #architecturepatterns https://hynek.me/talks/design-pressure/
#pythondev #softwaredesign #architecturepatterns https://hynek.me/talks/design-pressure/

Design Pressure
Ever had this weird gut feeling that something is off in your code, but couldn’t put the finger on why? Are you starting your projects with the best intentions, following all best practices, and still feel like your architecture turns weird eventually?
hynek.me
May 25, 2025 at 5:55 PM
Why does your code feel off? Hynek reveals the hidden forces that shape our architecture decisions. A must-read for better design choices.
#pythondev #softwaredesign #architecturepatterns https://hynek.me/talks/design-pressure/
#pythondev #softwaredesign #architecturepatterns https://hynek.me/talks/design-pressure/
Senior devs share real LLM coding tricks - no hype, just results. Level up your AI pair programming skills today.
#LLM #codewithai #devtools https://pmbanugo.me/blog/peer-programming-with-llms
#LLM #codewithai #devtools https://pmbanugo.me/blog/peer-programming-with-llms

Peer Programming with LLMs, For Senior+ Engineers
This article contains a collection of resources for senior (or staff+) engineers exploring the use of LLM for collaborative programming.
pmbanugo.me
May 24, 2025 at 7:00 PM
Senior devs share real LLM coding tricks - no hype, just results. Level up your AI pair programming skills today.
#LLM #codewithai #devtools https://pmbanugo.me/blog/peer-programming-with-llms
#LLM #codewithai #devtools https://pmbanugo.me/blog/peer-programming-with-llms
Heads up! GitHub's rate limiting is in full force today. Take a coffee break and let those API quotas reset.
#github #devops #api https://github.com/notactuallytreyanastasio/genstage_tutorial_2025/blob/main/README.md
#github #devops #api https://github.com/notactuallytreyanastasio/genstage_tutorial_2025/blob/main/README.md
May 23, 2025 at 5:24 PM
Heads up! GitHub's rate limiting is in full force today. Take a coffee break and let those API quotas reset.
#github #devops #api https://github.com/notactuallytreyanastasio/genstage_tutorial_2025/blob/main/README.md
#github #devops #api https://github.com/notactuallytreyanastasio/genstage_tutorial_2025/blob/main/README.md
Why We Say **Yes** When We Should Say **No** 🎯
Have you noticed: when teams feel pressure, they start taking on more work instead of less. It's like trying to fix a traffic jam by adding more cars to the road.
Have you noticed: when teams feel pressure, they start taking on more work instead of less. It's like trying to fix a traffic jam by adding more cars to the road.

May 23, 2025 at 12:13 PM
Why We Say **Yes** When We Should Say **No** 🎯
Have you noticed: when teams feel pressure, they start taking on more work instead of less. It's like trying to fix a traffic jam by adding more cars to the road.
Have you noticed: when teams feel pressure, they start taking on more work instead of less. It's like trying to fix a traffic jam by adding more cars to the road.
Bezel's Horizon shows how LLMs can judge AI images but not fix pixel-level details. A big step for practical AI image tools.
#ai #machinelearning #devtools https://simulate.trybezel.com/research/image_agent
#ai #machinelearning #devtools https://simulate.trybezel.com/research/image_agent
Building an agentic image generator that improves itself
Comments
simulate.trybezel.com
May 21, 2025 at 3:22 PM
Bezel's Horizon shows how LLMs can judge AI images but not fix pixel-level details. A big step for practical AI image tools.
#ai #machinelearning #devtools https://simulate.trybezel.com/research/image_agent
#ai #machinelearning #devtools https://simulate.trybezel.com/research/image_agent
Why do 68% of async implementations fail while others save $3.2M annually?
What can you do to onboard successfully?
Our guide reveals the exact playbook from GitLab, Doist & Shopify.
https://jetthoughts.com/blog/from-pitfalls-profit-how-successfully-implement/
#AsyncWork #remoteleadership
What can you do to onboard successfully?
Our guide reveals the exact playbook from GitLab, Doist & Shopify.
https://jetthoughts.com/blog/from-pitfalls-profit-how-successfully-implement/
#AsyncWork #remoteleadership
From Pitfalls to Profit: How to Successfully Implement Async - JTWay, JetThoughts’ team blog
TL;DR Despite promising $3.2M in annual savings for a 60-person team, 68% of async...
jetthoughts.com
May 21, 2025 at 3:16 PM
Why do 68% of async implementations fail while others save $3.2M annually?
What can you do to onboard successfully?
Our guide reveals the exact playbook from GitLab, Doist & Shopify.
https://jetthoughts.com/blog/from-pitfalls-profit-how-successfully-implement/
#AsyncWork #remoteleadership
What can you do to onboard successfully?
Our guide reveals the exact playbook from GitLab, Doist & Shopify.
https://jetthoughts.com/blog/from-pitfalls-profit-how-successfully-implement/
#AsyncWork #remoteleadership
📊 ANALYSIS: Research shows async communication saves $3.2M annually per 60 employees.
83% cost reduction + 40% lower turnover based on real company data.
See the impact: https://jetthoughts.com/blog/async-advantage-how-switching-communication-styles/
#leadership #devops #communication
83% cost reduction + 40% lower turnover based on real company data.
See the impact: https://jetthoughts.com/blog/async-advantage-how-switching-communication-styles/
#leadership #devops #communication
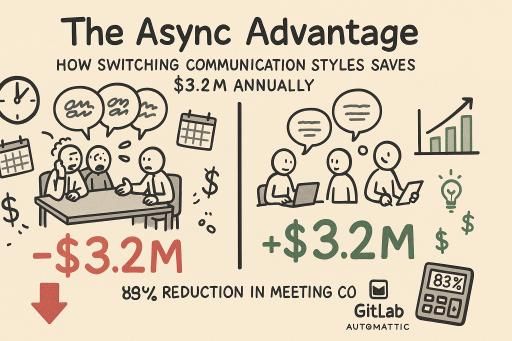
The Async Advantage: How Switching Communication Styles Saves $3.2M Annually - JTWay, JetThoughts’ team blog
TL;DR Companies waste millions on unnecessary meetings - for a 60-person team, the total...
jetthoughts.com
May 19, 2025 at 11:13 PM
📊 ANALYSIS: Research shows async communication saves $3.2M annually per 60 employees.
83% cost reduction + 40% lower turnover based on real company data.
See the impact: https://jetthoughts.com/blog/async-advantage-how-switching-communication-styles/
#leadership #devops #communication
83% cost reduction + 40% lower turnover based on real company data.
See the impact: https://jetthoughts.com/blog/async-advantage-how-switching-communication-styles/
#leadership #devops #communication