
Alison Hoens
@physioktbroker.bsky.social
580 followers
350 following
280 posts
Clinical Professor, Knowledge Broker, Physical Therapist, Knowledge mobilization specialist
Posts
Media
Videos
Starter Packs











Alison Hoens
@physioktbroker.bsky.social
· Aug 31
Reposted by Alison Hoens



Alison Hoens
@physioktbroker.bsky.social
· Aug 31
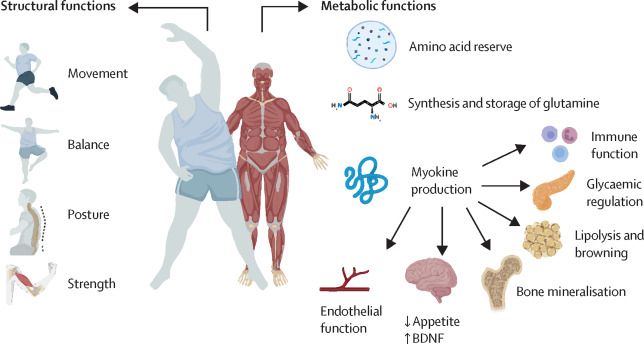
Muscle matters: the effects of medically induced weight loss on skeletal muscle
The importance of skeletal muscle mass is increasingly being recognised in the medical
field.1 The crucial roles of skeletal muscle have come to the forefront of public
attention due to data on the us...
www.thelancet.com
Reposted by Alison Hoens



Alison Hoens
@physioktbroker.bsky.social
· Aug 23

Daily steps and health outcomes in adults: a systematic review and dose-response meta-analysis
Although 10 000 steps per day can still be a viable target for those who are more
active, 7000 steps per day is associated with clinically meaningful improvements in
health outcomes and might be a mor...
www.thelancet.com
Alison Hoens
@physioktbroker.bsky.social
· Aug 23

The benefits for health care staff of involvement in applied health research: a scoping review - Health Research Policy and Systems
Background Initiatives are increasingly encouraging health and social care staff involvement in research, with evidence for patient and organisational level benefits. There is less evidence of the ben...
health-policy-systems.biomedcentral.com
Reposted by Alison Hoens

BF Francis Ouellette
@bffo.bsky.social
· Aug 16

Ten simple rules for leading a many-author non-empirical paper
Many-author non-empirical papers include recommendations or consensus statements, catalogs of ideas, roadmaps for future research, calls to action, or “how to” articles. These papers have great potent...
journals.plos.org
Reposted by Alison Hoens

Prof Sam Illingworth
@samillingworth.com
· Aug 16

Countrywide natural experiment links built environment to physical activity - Nature
By analysing the smartphone data of 2,112,288 participants, in particular observing and comparing the activity of the same individual in two different environments, we find that increases in the walka...
www.nature.com



Alison Hoens
@physioktbroker.bsky.social
· Aug 10

Neural similarity predicts whether strangers become friends - Nature Human Behaviour
Shen et al. show that pre-existing neural similarity in strangers predicts future friendship and changes in social distance over time in an emerging social network of MBA students.
www.nature.com