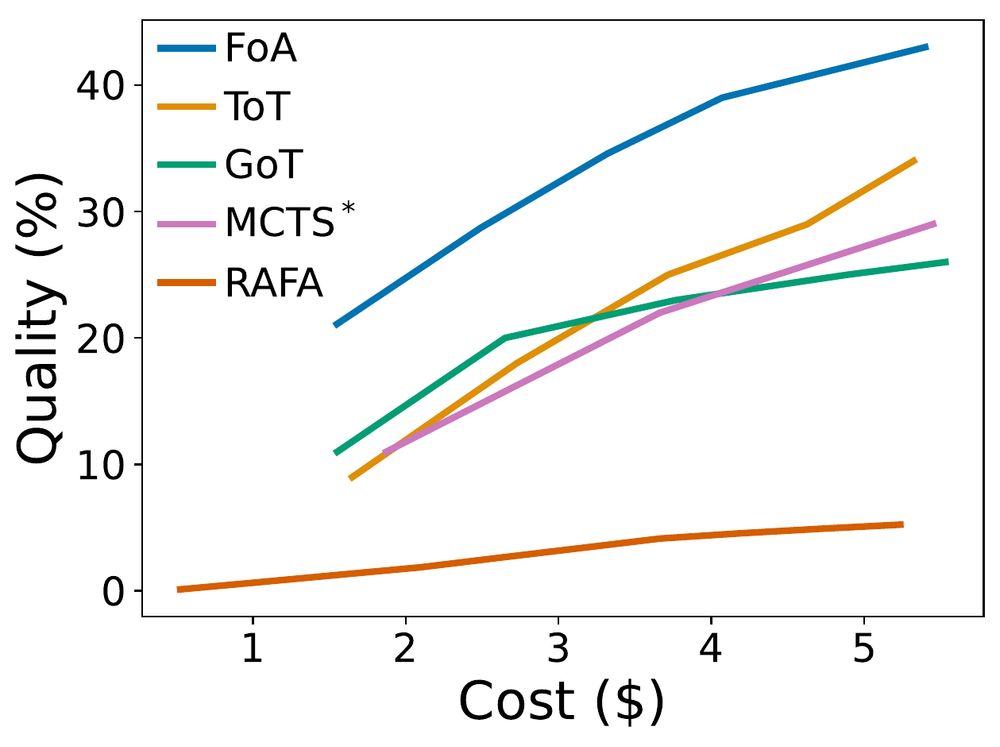
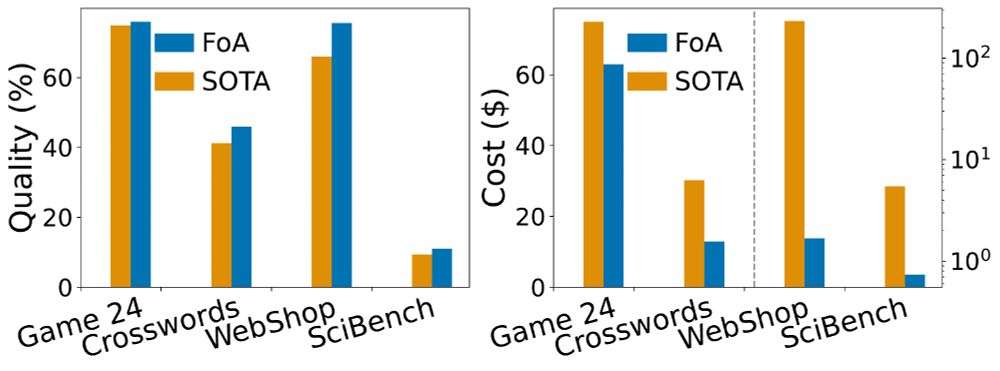
In Fleet of agents, each agent explores the problem space independently by generating thoughts, taking actions, or making moves. After a round of exploration, agents are scored, and the best-performing ones are resampled to continue, while weak or invalid ones are eliminated and replaced.