Hanbo Xie
@psychboyh.bsky.social
81 followers
130 following
27 posts
Third-year PhD student at NRD Lab at Gatech. Interested in using Large Language Models to understand human decision-making and learning, and the core of human intelligence.
Posts
Media
Videos
Starter Packs
Pinned


Hanbo Xie
@psychboyh.bsky.social
· Jan 31

Large Language Models Think Too Fast To Explore Effectively
Large Language Models have emerged many intellectual capacities. While numerous benchmarks assess their intelligence, limited attention has been given to their ability to explore, an essential capacit...
arxiv.org


Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
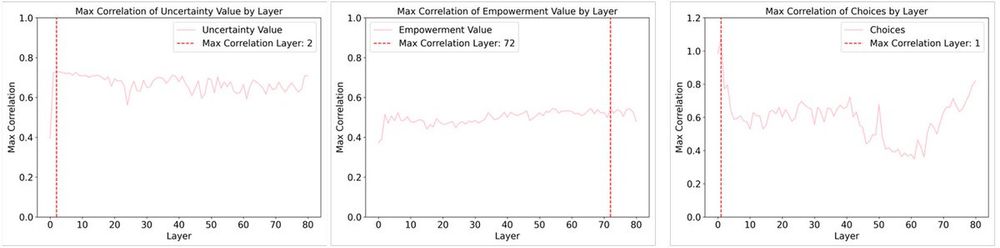
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
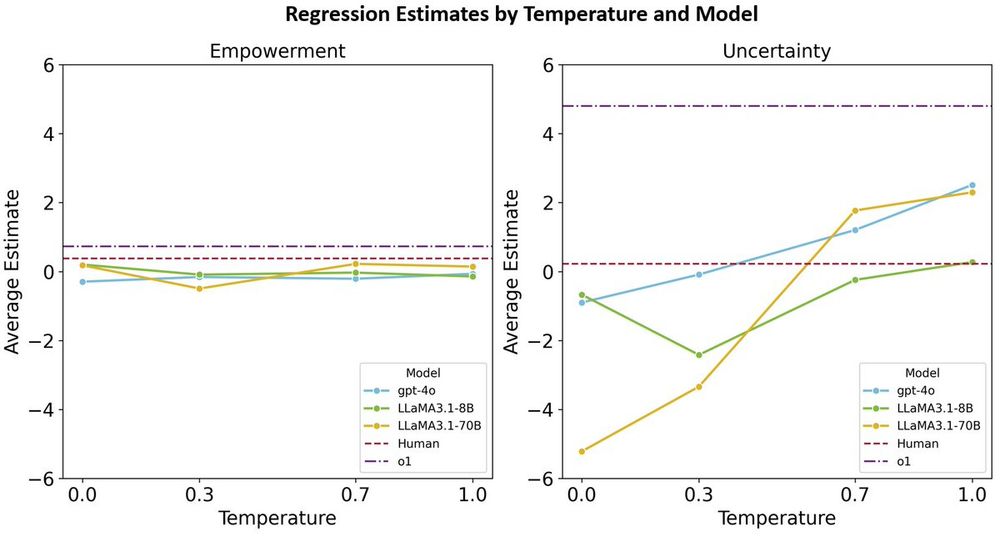
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
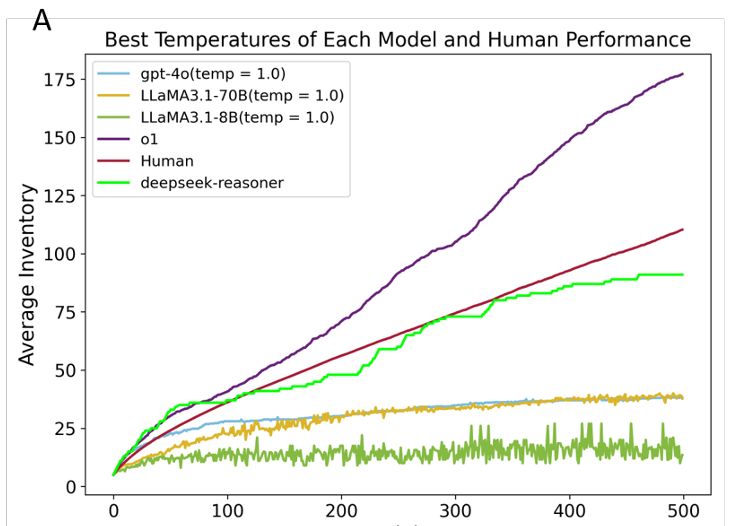

Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Hanbo Xie
@psychboyh.bsky.social
· Jan 31
Large Language Models Think Too Fast To Explore Effectively
Large Language Models have emerged many intellectual capacities. While numerous benchmarks assess their intelligence, limited attention has been given to their ability to explore, an essential capacit...
arxiv.org