
Rob Cavanaugh
@rbcavanaugh.bsky.social
440 followers
510 following
71 posts
Assistant Professor in quantitative methods @mghinstitute, speech-language pathologist by training. Enthusiastic about quantitative methods in rehabilitation research and health services research for aphasia. 🥾🏔️🦮🍕
Posts
Media
Videos
Starter Packs
Reposted by Rob Cavanaugh

Maëlle Salmon
@masalmon.eu
· 15d

How I, a non-developer, read the tutorial you, a developer, wrote for me, a beginner - annie's blog
“Hello! I am a developer. Here is my relevant experience: I code in Hoobijag and sometimes jabbernocks and of course ABCDE++++ (but never ABCDE+/^+ are you kidding? ha!) and I like working with ...
anniemueller.com
Reposted by Rob Cavanaugh


Rob Cavanaugh
@rbcavanaugh.bsky.social
· Aug 26
Reposted by Rob Cavanaugh




Rob Cavanaugh
@rbcavanaugh.bsky.social
· Aug 23
Rob Cavanaugh
@rbcavanaugh.bsky.social
· Aug 19
Rob Cavanaugh
@rbcavanaugh.bsky.social
· Aug 18

Rob Cavanaugh
@rbcavanaugh.bsky.social
· Aug 18
Rob Cavanaugh
@rbcavanaugh.bsky.social
· Jul 22

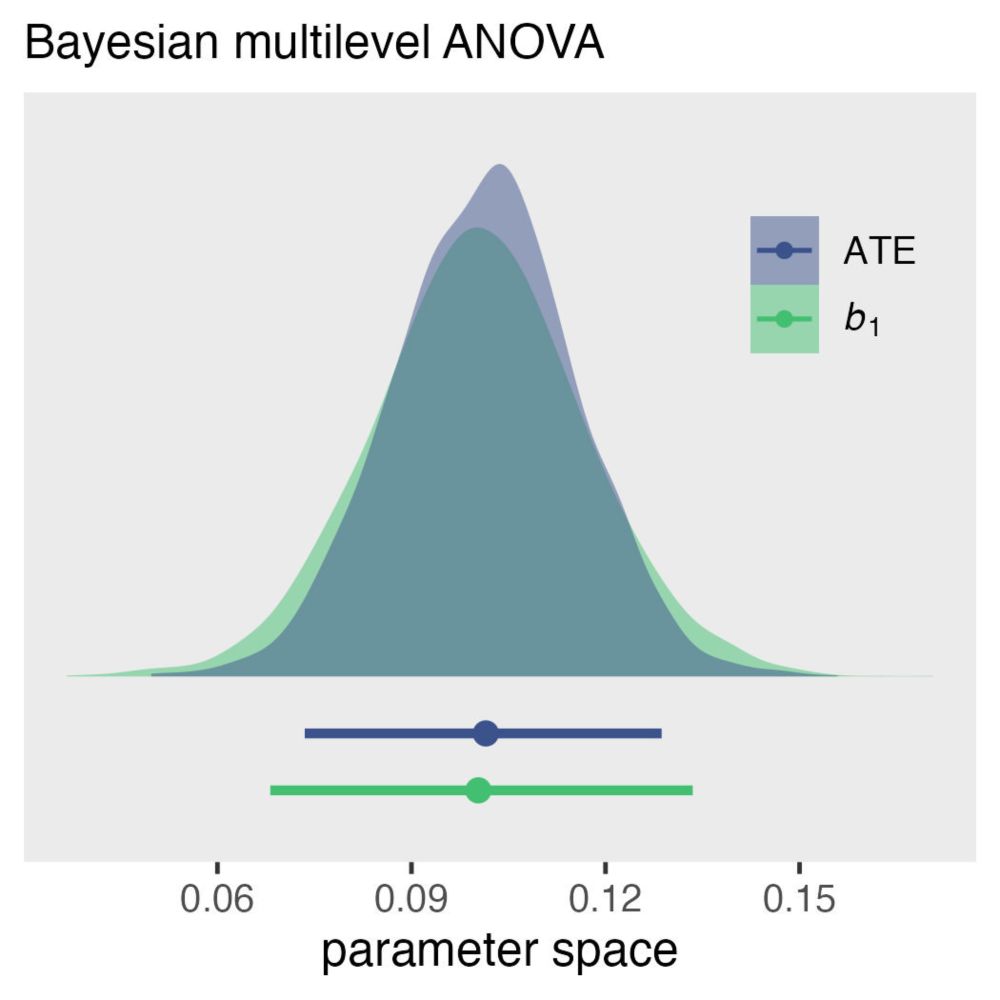


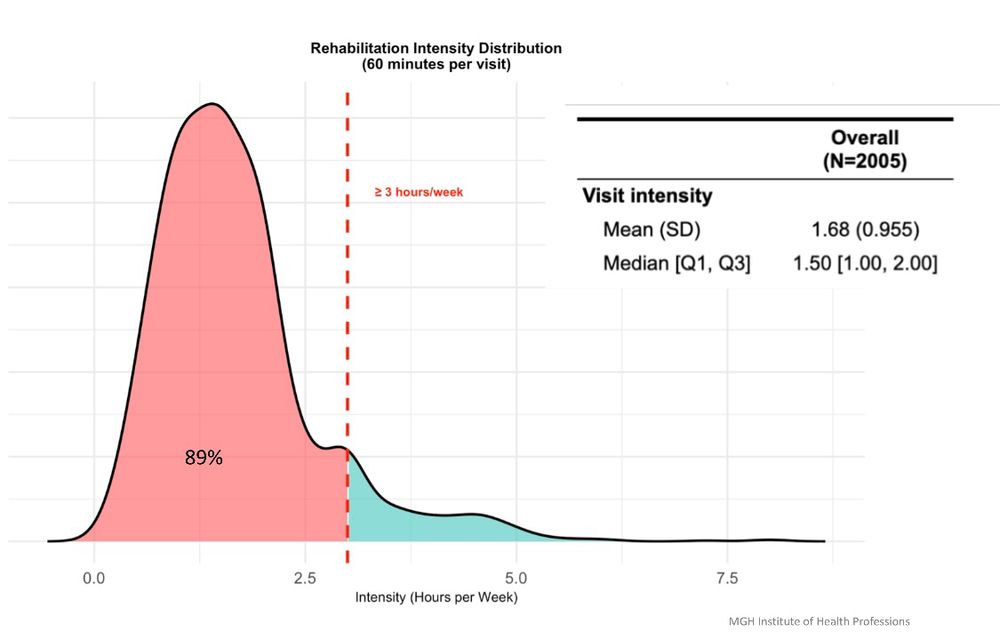
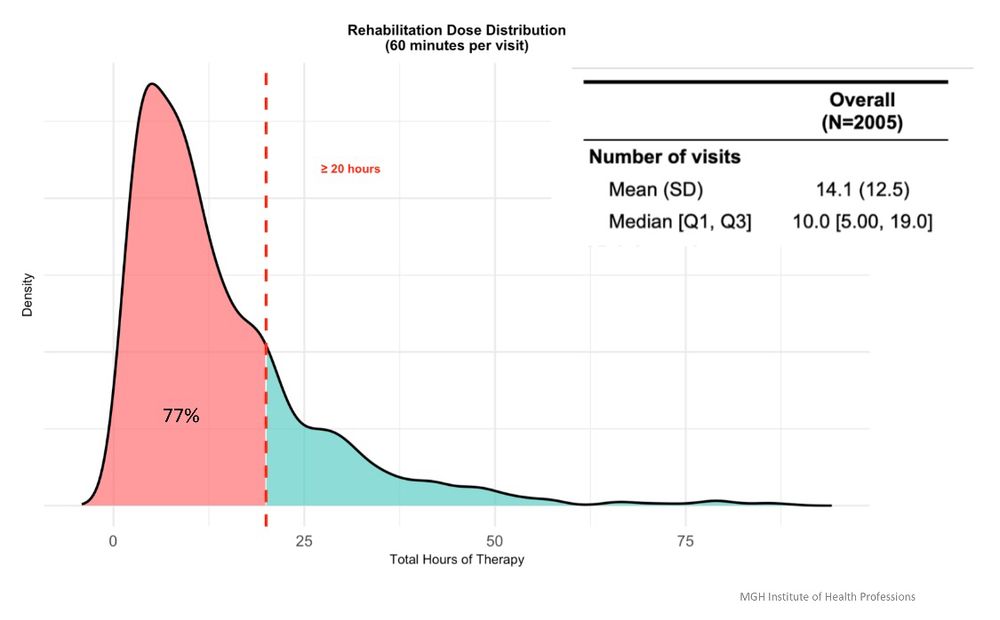
Rob Cavanaugh
@rbcavanaugh.bsky.social
· May 12
Rob Cavanaugh
@rbcavanaugh.bsky.social
· Apr 10
Reposted by Rob Cavanaugh


Reposted by Rob Cavanaugh

