



Ritwik Gupta
@ritwikgupta.bsky.social
Ph.D. Student at Berkeley AI Research | AI for Chaotic Environments and the Dual-Use Governance of AI
This behavior has very interesting quirks. LLMs implicitly demonstrate time-discounting over the ICL examples. That is, recent evidence matters more!
March 10, 2025 at 5:32 PM
This behavior has very interesting quirks. LLMs implicitly demonstrate time-discounting over the ICL examples. That is, recent evidence matters more!
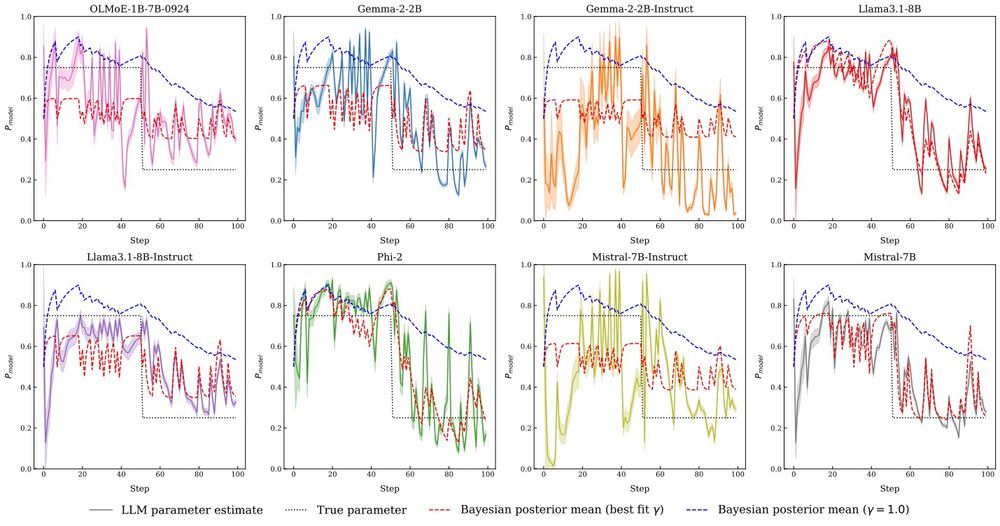
Interestingly, models follow a very similar trajectory to what the true Bayesian posterior should look like with the same amount of evidence! When we prompt for coin flips from a 60% heads-biased coin but give it evidence the follows 70% heads, models converge to the latter.
March 10, 2025 at 5:32 PM
Interestingly, models follow a very similar trajectory to what the true Bayesian posterior should look like with the same amount of evidence! When we prompt for coin flips from a 60% heads-biased coin but give it evidence the follows 70% heads, models converge to the latter.
Can we control this behavior? We tried many things before settling on in-context learning as a working mechanism. If we prompt an LLM to flip a biased coin, and then show increasing rollouts of flips from such a distribution, models converge to the right underlying parameter.
March 10, 2025 at 5:32 PM
Can we control this behavior? We tried many things before settling on in-context learning as a working mechanism. If we prompt an LLM to flip a biased coin, and then show increasing rollouts of flips from such a distribution, models converge to the right underlying parameter.
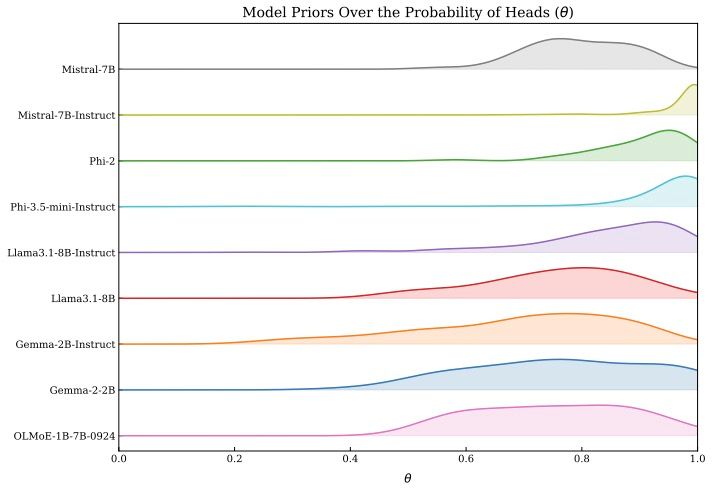
Biased coin flips follow a simple probability distribution that LLMs should be able to simulate explicitly. In fact, when prompted to flip a fair coin, most LLMs predict heads 70-85% of the time! This holds true even if you prompt the model to flip a biased coin 🪙
March 10, 2025 at 5:32 PM
Biased coin flips follow a simple probability distribution that LLMs should be able to simulate explicitly. In fact, when prompted to flip a fair coin, most LLMs predict heads 70-85% of the time! This holds true even if you prompt the model to flip a biased coin 🪙