



Robert Rosenbaum
@robertrosenbaum.bsky.social
Associate Professor of Applied and Computational Mathematics and Statistics and Biological Sciences at U Notre Dame. Theoretically a Neuroscientist.
Couldn't the same argument be made for conference presentations (which 90% of the time only describe published work)?
May 20, 2025 at 7:05 PM
Couldn't the same argument be made for conference presentations (which 90% of the time only describe published work)?
When _you_ publish a new paper, lots of people notice, lots of people read it. No explainer thread needed. Deservedly so, because you have a reputation for writing great papers.
When Dr. Average Scientist publishes a paper, nobody notices, nobody reads it without some leg work to get it out there
When Dr. Average Scientist publishes a paper, nobody notices, nobody reads it without some leg work to get it out there
May 20, 2025 at 7:04 PM
When _you_ publish a new paper, lots of people notice, lots of people read it. No explainer thread needed. Deservedly so, because you have a reputation for writing great papers.
When Dr. Average Scientist publishes a paper, nobody notices, nobody reads it without some leg work to get it out there
When Dr. Average Scientist publishes a paper, nobody notices, nobody reads it without some leg work to get it out there
Thanks! Let us know if you have comments or questions
May 19, 2025 at 4:13 PM
Thanks! Let us know if you have comments or questions
In other words:
Plasticity rules like Oja's let us go beyond studying how synaptic plasticity in the brain can _match_ the performance of backprop.
Now, we can study how synaptic plasticity can _beat_ backprop in challenging, but realistic learning scenarios.
Plasticity rules like Oja's let us go beyond studying how synaptic plasticity in the brain can _match_ the performance of backprop.
Now, we can study how synaptic plasticity can _beat_ backprop in challenging, but realistic learning scenarios.
May 19, 2025 at 3:33 PM
In other words:
Plasticity rules like Oja's let us go beyond studying how synaptic plasticity in the brain can _match_ the performance of backprop.
Now, we can study how synaptic plasticity can _beat_ backprop in challenging, but realistic learning scenarios.
Plasticity rules like Oja's let us go beyond studying how synaptic plasticity in the brain can _match_ the performance of backprop.
Now, we can study how synaptic plasticity can _beat_ backprop in challenging, but realistic learning scenarios.
Finally, we meta-learned pure plasticity rules with no weight transport, extending our previous work. When Oja's rule was included, the meta-learned rule _outperformed_ pure backprop.

May 19, 2025 at 3:33 PM
Finally, we meta-learned pure plasticity rules with no weight transport, extending our previous work. When Oja's rule was included, the meta-learned rule _outperformed_ pure backprop.
We find that Oja's rule works, in part, by preserving information about inputs in hidden layers. This is related to its known properties in forming orthogonal representations. Check the paper for more details.

May 19, 2025 at 3:33 PM
We find that Oja's rule works, in part, by preserving information about inputs in hidden layers. This is related to its known properties in forming orthogonal representations. Check the paper for more details.
Vanilla RNNs trained with pure BPTT fail on simple memory tasks. Adding Oja's rule to BPTT drastically improves performance.

May 19, 2025 at 3:33 PM
Vanilla RNNs trained with pure BPTT fail on simple memory tasks. Adding Oja's rule to BPTT drastically improves performance.
We often forget how important careful weight initialization is for training neural nets because our software initializes them for us. Adding Oja's rule to backprop also eliminates the need for careful weight initialization.

May 19, 2025 at 3:33 PM
We often forget how important careful weight initialization is for training neural nets because our software initializes them for us. Adding Oja's rule to backprop also eliminates the need for careful weight initialization.
We propose that plasticity rules like Oja's rule might be part of the answer. Adding Oja's rule to backprop improves learning in deep networks in an online setting (batch size 1).

May 19, 2025 at 3:33 PM
We propose that plasticity rules like Oja's rule might be part of the answer. Adding Oja's rule to backprop improves learning in deep networks in an online setting (batch size 1).
For example, a 10-layer ffwd network trained on MNIST using online learning (batch size 1) performs poorly when trained with pure backprop. How does the brain learn effectively without all of these engineering hacks?

May 19, 2025 at 3:33 PM
For example, a 10-layer ffwd network trained on MNIST using online learning (batch size 1) performs poorly when trained with pure backprop. How does the brain learn effectively without all of these engineering hacks?
In our new preprint, we dug deeper into this observation. Our motivation is that modern machine learning depends on lots of engineering hacks beyond pure backprop: gradients averaged over batches, batchnorm, momentum, etc. These hacks don't have clear, direct biological analogues.
May 19, 2025 at 3:33 PM
In our new preprint, we dug deeper into this observation. Our motivation is that modern machine learning depends on lots of engineering hacks beyond pure backprop: gradients averaged over batches, batchnorm, momentum, etc. These hacks don't have clear, direct biological analogues.
In previous work on this question, we meta-learned linear combos of plasticity rules. In doing so, we noticed something intersting:
One plasticity rule improved learning, but its weight updates weren't aligned with backprop's. It was doing something different. That rule is Oja's plasticity rule.
One plasticity rule improved learning, but its weight updates weren't aligned with backprop's. It was doing something different. That rule is Oja's plasticity rule.

May 19, 2025 at 3:33 PM
In previous work on this question, we meta-learned linear combos of plasticity rules. In doing so, we noticed something intersting:
One plasticity rule improved learning, but its weight updates weren't aligned with backprop's. It was doing something different. That rule is Oja's plasticity rule.
One plasticity rule improved learning, but its weight updates weren't aligned with backprop's. It was doing something different. That rule is Oja's plasticity rule.
A lot of work in "NeuroAI," including our own, seeks to understand how synaptic plasticity rules can match the performance of backprop in training neural nets.

May 19, 2025 at 3:33 PM
A lot of work in "NeuroAI," including our own, seeks to understand how synaptic plasticity rules can match the performance of backprop in training neural nets.
Interesting comment, but you need to define what you mean by "neuroanatomy." Does such a thing actually exist? As a thing in itself or as a phenomenon? What would Kant have to say? ;)
May 15, 2025 at 2:44 PM
Interesting comment, but you need to define what you mean by "neuroanatomy." Does such a thing actually exist? As a thing in itself or as a phenomenon? What would Kant have to say? ;)
Sorry, I didn't mean to phrase that antagonistically.
I just think that unless we're talking just about anatomy and we're restricting to a direct synaptic pathway (which maybe you are) then it's difficult to make this type of question precise without concluding that everything can query everything
I just think that unless we're talking just about anatomy and we're restricting to a direct synaptic pathway (which maybe you are) then it's difficult to make this type of question precise without concluding that everything can query everything
May 13, 2025 at 3:02 PM
Sorry, I didn't mean to phrase that antagonistically.
I just think that unless we're talking just about anatomy and we're restricting to a direct synaptic pathway (which maybe you are) then it's difficult to make this type of question precise without concluding that everything can query everything
I just think that unless we're talking just about anatomy and we're restricting to a direct synaptic pathway (which maybe you are) then it's difficult to make this type of question precise without concluding that everything can query everything
Unless we're talking about a direct synapse, I don't know how we can expect to answer this question meaningfully when a neuromuscular junction in my pinky toe can "readout" and "query" photoreceptors in my retina.
May 13, 2025 at 2:27 PM
Unless we're talking about a direct synapse, I don't know how we can expect to answer this question meaningfully when a neuromuscular junction in my pinky toe can "readout" and "query" photoreceptors in my retina.
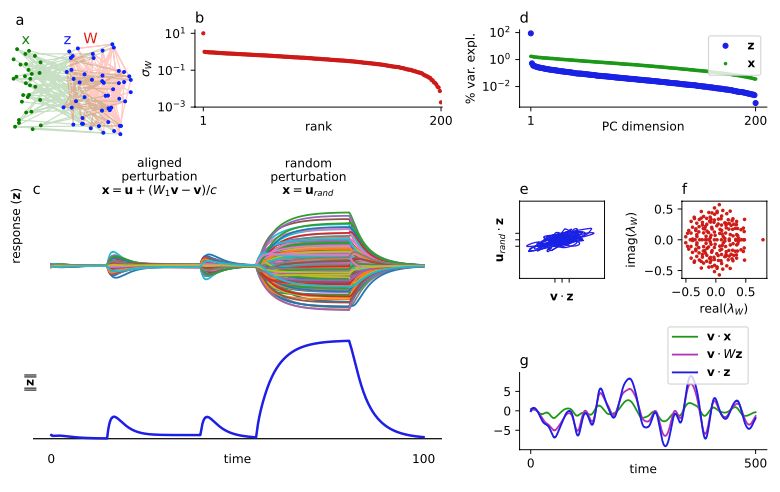
Thanks. Yeah, I think this example helps clarify 2 points:
1) large negative eigenvalues are not necessary for LRS, and
2) high-dim input and stable dynamics are not sufficient for high-dim responses.
Motivated by this conversation, I added eigenvalues to the plot and edited the text a bit, thx!
1) large negative eigenvalues are not necessary for LRS, and
2) high-dim input and stable dynamics are not sufficient for high-dim responses.
Motivated by this conversation, I added eigenvalues to the plot and edited the text a bit, thx!
May 2, 2025 at 4:51 PM
Thanks. Yeah, I think this example helps clarify 2 points:
1) large negative eigenvalues are not necessary for LRS, and
2) high-dim input and stable dynamics are not sufficient for high-dim responses.
Motivated by this conversation, I added eigenvalues to the plot and edited the text a bit, thx!
1) large negative eigenvalues are not necessary for LRS, and
2) high-dim input and stable dynamics are not sufficient for high-dim responses.
Motivated by this conversation, I added eigenvalues to the plot and edited the text a bit, thx!
^ I feel like this is a problem you'd be good at tackling
April 26, 2025 at 1:51 PM
^ I feel like this is a problem you'd be good at tackling
One thing I tried to work out, but couldn't: We assumed a discrete number of large sing vals of W, but what if there a continuous, but slow decay (eg, power law).
How to derive the decay rate of the var expl vals in terms of the sing val decay rate and the overlap matrix?
How to derive the decay rate of the var expl vals in terms of the sing val decay rate and the overlap matrix?
April 26, 2025 at 1:51 PM
One thing I tried to work out, but couldn't: We assumed a discrete number of large sing vals of W, but what if there a continuous, but slow decay (eg, power law).
How to derive the decay rate of the var expl vals in terms of the sing val decay rate and the overlap matrix?
How to derive the decay rate of the var expl vals in terms of the sing val decay rate and the overlap matrix?