Romane Cecchi
@romanececchi.bsky.social
80 followers
68 following
11 posts
Postdoc in the Human Reinforcement Learning team led by @stepalminteri.bsky.social at École Normale Supérieure (ENS) in Paris ✨
Posts
Media
Videos
Starter Packs

Romane Cecchi
@romanececchi.bsky.social
· Apr 30
Romane Cecchi
@romanececchi.bsky.social
· Apr 22

Romane Cecchi
@romanececchi.bsky.social
· Apr 22
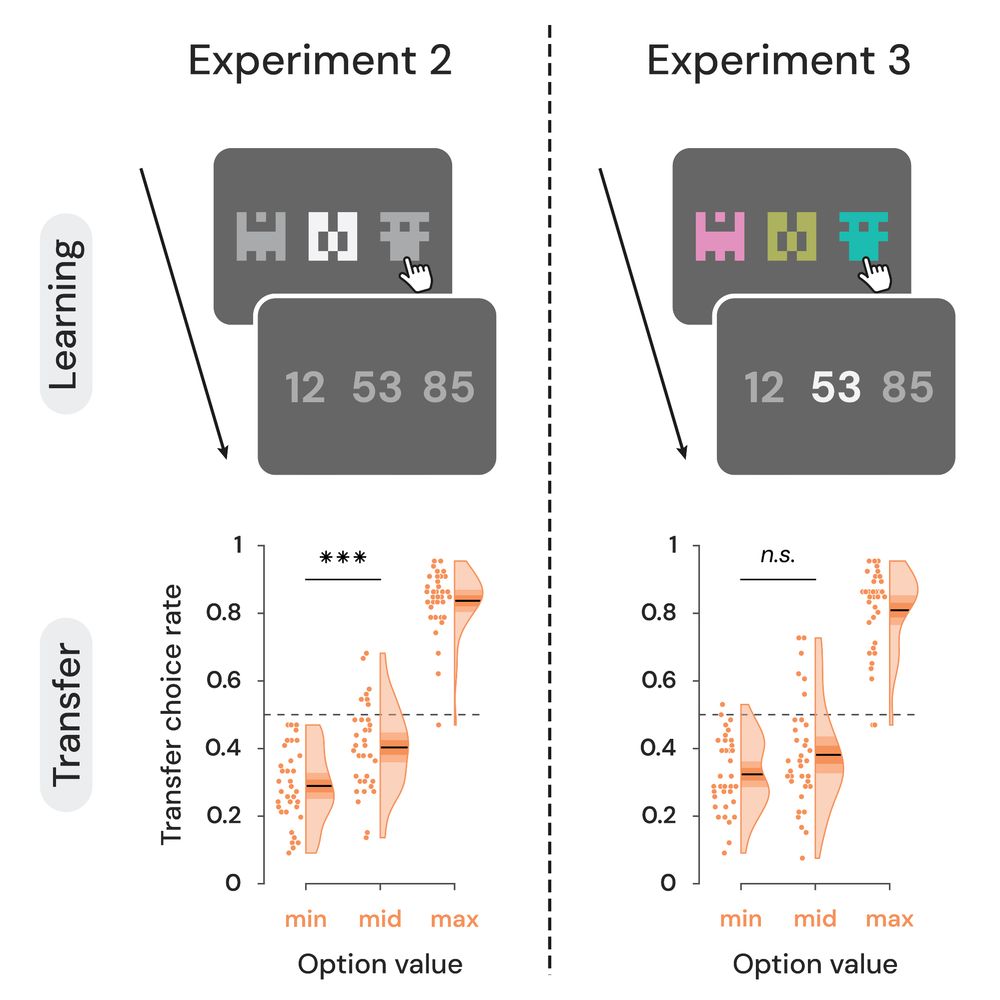


Romane Cecchi
@romanececchi.bsky.social
· Apr 22

Reposted by Romane Cecchi


Reposted by Romane Cecchi

Reposted by Romane Cecchi