




Dan Saattrup Smart
@saattrupdan.com
Researcher and consultant in low-resource NLP, with a focus on evaluation. saattrupdan.com
Så langt øjet rækker, vil manglen på it- og STEM-uddannede bare vokse, viser ny analyse fra @ida.dk.
Det kan blive dyrt for samfundet, advarer @forperson.ida.dk.
På ITU må vi hvert år afvise mange ansøgere i døren pga. politisk bestemte rammer... 🤷
#uddpol #dkpol
www.berlingske.dk/virksomheder...
Det kan blive dyrt for samfundet, advarer @forperson.ida.dk.
På ITU må vi hvert år afvise mange ansøgere i døren pga. politisk bestemte rammer... 🤷
#uddpol #dkpol
www.berlingske.dk/virksomheder...

Ny analyse: Danmark vil mangle 20.400 ingeniører og it-kandidater i 2040
Læs mere her.
www.berlingske.dk
May 14, 2025 at 7:51 PM
Reposted by Dan Saattrup Smart

Reposted by Dan Saattrup Smart

Wanna keep up with our @milanlp.bsky.social lab? Here is a starter pack of current and former members:
bsky.app/starter-pack...
bsky.app/starter-pack...
March 5, 2025 at 10:47 AM
Wanna keep up with our @milanlp.bsky.social lab? Here is a starter pack of current and former members:
bsky.app/starter-pack...
bsky.app/starter-pack...
Reposted by Dan Saattrup Smart

NoDaLiDa x Baltic-HLT 2025 is a wrap!
Thank you all for joining for a fruitful conference! Safe trip home and see you in Copenhagen or Vilnius in 2027!!
#nlp #nodalida #baltichlt
Thank you all for joining for a fruitful conference! Safe trip home and see you in Copenhagen or Vilnius in 2027!!
#nlp #nodalida #baltichlt
March 5, 2025 at 3:11 PM
NoDaLiDa x Baltic-HLT 2025 is a wrap!
Thank you all for joining for a fruitful conference! Safe trip home and see you in Copenhagen or Vilnius in 2027!!
#nlp #nodalida #baltichlt
Thank you all for joining for a fruitful conference! Safe trip home and see you in Copenhagen or Vilnius in 2027!!
#nlp #nodalida #baltichlt
Reposted by Dan Saattrup Smart

WebFAQ: Massive Multilingual Q&A Dataset
- 96M QA pairs extracted from schema.org/FAQPage annotations
- 75 languages with standardized structured markup
- Leverages existing web publisher content intent
- No synthetic data generation needed
huggingface.co/datasets/PaD...
- 96M QA pairs extracted from schema.org/FAQPage annotations
- 75 languages with standardized structured markup
- Leverages existing web publisher content intent
- No synthetic data generation needed
huggingface.co/datasets/PaD...

PaDaS-Lab/webfaq · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
March 6, 2025 at 9:18 AM
WebFAQ: Massive Multilingual Q&A Dataset
- 96M QA pairs extracted from schema.org/FAQPage annotations
- 75 languages with standardized structured markup
- Leverages existing web publisher content intent
- No synthetic data generation needed
huggingface.co/datasets/PaD...
- 96M QA pairs extracted from schema.org/FAQPage annotations
- 75 languages with standardized structured markup
- Leverages existing web publisher content intent
- No synthetic data generation needed
huggingface.co/datasets/PaD...
Reposted by Dan Saattrup Smart
🚀 Thank you all for waiting! The full program of NoDaLiDa x Baltic-HLT is online:
www.nodalida-bhlt2025.eu/program
#nodalida #baltichlt #nlp #nlproc
www.nodalida-bhlt2025.eu/program
#nodalida #baltichlt #nlp #nlproc

NoDaLiDa/Baltic-HLT 2025 - Program
All times are local (GMT+2/UTC+2). See detailed program below.
www.nodalida-bhlt2025.eu
February 18, 2025 at 3:27 PM
🚀 Thank you all for waiting! The full program of NoDaLiDa x Baltic-HLT is online:
www.nodalida-bhlt2025.eu/program
#nodalida #baltichlt #nlp #nlproc
www.nodalida-bhlt2025.eu/program
#nodalida #baltichlt #nlp #nlproc
Reposted by Dan Saattrup Smart

⚫⚪ It's coming...SHADES. ⚪⚫
The first ever resource of multilingual, multicultural, and multigeographical stereotypes, built to support nuanced LLM evaluation and bias mitigation. We have been working on this around the world for almost **4 years** and I am thrilled to share it with you all soon.
The first ever resource of multilingual, multicultural, and multigeographical stereotypes, built to support nuanced LLM evaluation and bias mitigation. We have been working on this around the world for almost **4 years** and I am thrilled to share it with you all soon.
February 10, 2025 at 8:28 AM
⚫⚪ It's coming...SHADES. ⚪⚫
The first ever resource of multilingual, multicultural, and multigeographical stereotypes, built to support nuanced LLM evaluation and bias mitigation. We have been working on this around the world for almost **4 years** and I am thrilled to share it with you all soon.
The first ever resource of multilingual, multicultural, and multigeographical stereotypes, built to support nuanced LLM evaluation and bias mitigation. We have been working on this around the world for almost **4 years** and I am thrilled to share it with you all soon.
Some new evaluation results from the European evaluation benchmark ScandEval! This time of the new o3-mini model by OpenAI - how well does it compare to the existing gpt-4o model on English tasks?
(1/4)
#nlp #evaluation #reasoning #llm #o3
(1/4)
#nlp #evaluation #reasoning #llm #o3
February 10, 2025 at 4:33 PM
Some new evaluation results from the European evaluation benchmark ScandEval! This time of the new o3-mini model by OpenAI - how well does it compare to the existing gpt-4o model on English tasks?
(1/4)
#nlp #evaluation #reasoning #llm #o3
(1/4)
#nlp #evaluation #reasoning #llm #o3
Recently, we got a lot of new ScandEval evaluations of large LLMs, including the 405B Llama-3.1 model. So how well does it perform?
A 🧵 (1/n)
#llm #evaluation
A 🧵 (1/n)
#llm #evaluation
January 20, 2025 at 2:01 PM
Recently, we got a lot of new ScandEval evaluations of large LLMs, including the 405B Llama-3.1 model. So how well does it perform?
A 🧵 (1/n)
#llm #evaluation
A 🧵 (1/n)
#llm #evaluation
Reposted by Dan Saattrup Smart
Introducing Scandi-fine-web-cleaner, a decoder model trained to remove low-quality web from FineWeb 2 for Danish and Swedish
- Uses FineWeb-c community annotations
- 90%+ precision + minimal compute required
- Enables efficient filtering of 43M+ documents
huggingface.co/davanstrien/...
- Uses FineWeb-c community annotations
- 90%+ precision + minimal compute required
- Enables efficient filtering of 43M+ documents
huggingface.co/davanstrien/...

January 13, 2025 at 3:48 PM
Introducing Scandi-fine-web-cleaner, a decoder model trained to remove low-quality web from FineWeb 2 for Danish and Swedish
- Uses FineWeb-c community annotations
- 90%+ precision + minimal compute required
- Enables efficient filtering of 43M+ documents
huggingface.co/davanstrien/...
- Uses FineWeb-c community annotations
- 90%+ precision + minimal compute required
- Enables efficient filtering of 43M+ documents
huggingface.co/davanstrien/...
Reposted by Dan Saattrup Smart

Brugerdrevet faktatjek kan betyde, at minoriteters interesser bliver overset, advarer ITU-lektor @lrossi.bsky.social.
Påstande om fx grønlandske forhold risikerer at undslippe faktatjek, simpelthen fordi der er få grønlandske brugere i forhold til andre grupper.
www.berlingske.dk/kultur/faceb...
Påstande om fx grønlandske forhold risikerer at undslippe faktatjek, simpelthen fordi der er få grønlandske brugere i forhold til andre grupper.
www.berlingske.dk/kultur/faceb...
Facebook i kovending: Forvent flere vilde opslag – og forvent at blive dummere, advarer ekspert
Læs mere her.
www.berlingske.dk
January 9, 2025 at 1:12 PM
Brugerdrevet faktatjek kan betyde, at minoriteters interesser bliver overset, advarer ITU-lektor @lrossi.bsky.social.
Påstande om fx grønlandske forhold risikerer at undslippe faktatjek, simpelthen fordi der er få grønlandske brugere i forhold til andre grupper.
www.berlingske.dk/kultur/faceb...
Påstande om fx grønlandske forhold risikerer at undslippe faktatjek, simpelthen fordi der er få grønlandske brugere i forhold til andre grupper.
www.berlingske.dk/kultur/faceb...

📣 Vacancy for Assistant Professor of Cognitive Science at Department of Linguistics, Cognitive Science and Semiotics, Aarhus University, Denmark. (Deadline January 6)
international.au.dk/about/profil...
international.au.dk/about/profil...

Assistant Professor of Cognitive Science at the School of Communication and Culture - Vacancy at Aarhus University
Vacancy at School of Communication and Culture - Linguistics, Cognitive Science and Semiotics, Dept. of, Aarhus University
international.au.dk
December 28, 2024 at 1:14 PM
Reposted by Dan Saattrup Smart

It’s time for THE charger.
Today, the USB-C becomes officially the common standard for charging new mobile electronic devices in the EU.
It means better-charging technology, reduced e-waste, and less fuss to find the chargers you need!
#DigitalEU
Today, the USB-C becomes officially the common standard for charging new mobile electronic devices in the EU.
It means better-charging technology, reduced e-waste, and less fuss to find the chargers you need!
#DigitalEU

December 28, 2024 at 7:09 AM
It’s time for THE charger.
Today, the USB-C becomes officially the common standard for charging new mobile electronic devices in the EU.
It means better-charging technology, reduced e-waste, and less fuss to find the chargers you need!
#DigitalEU
Today, the USB-C becomes officially the common standard for charging new mobile electronic devices in the EU.
It means better-charging technology, reduced e-waste, and less fuss to find the chargers you need!
#DigitalEU
Reposted by Dan Saattrup Smart

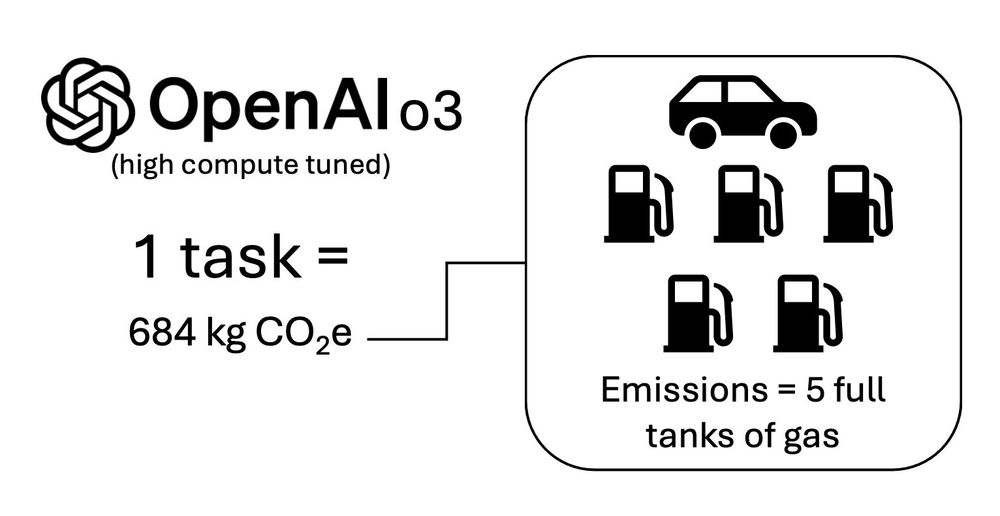
"Each task consumed approximately 1,785 kWh of energy—about the same amount of electricity an average U.S. household uses in two months"
This is one per-task estimate from Salesforce's head of sustainability -->>
www.linkedin.com/posts/bgamaz...
This is one per-task estimate from Salesforce's head of sustainability -->>
www.linkedin.com/posts/bgamaz...
December 28, 2024 at 8:45 AM
"Each task consumed approximately 1,785 kWh of energy—about the same amount of electricity an average U.S. household uses in two months"
This is one per-task estimate from Salesforce's head of sustainability -->>
www.linkedin.com/posts/bgamaz...
This is one per-task estimate from Salesforce's head of sustainability -->>
www.linkedin.com/posts/bgamaz...
Reposted by Dan Saattrup Smart

I'm so impressed with the markview #Neovim plugin. Look at the preview you get out of the box:
github.com/OXY2DEV/mark...
github.com/OXY2DEV/mark...
December 18, 2024 at 10:49 PM
I'm so impressed with the markview #Neovim plugin. Look at the preview you get out of the box:
github.com/OXY2DEV/mark...
github.com/OXY2DEV/mark...
Reposted by Dan Saattrup Smart

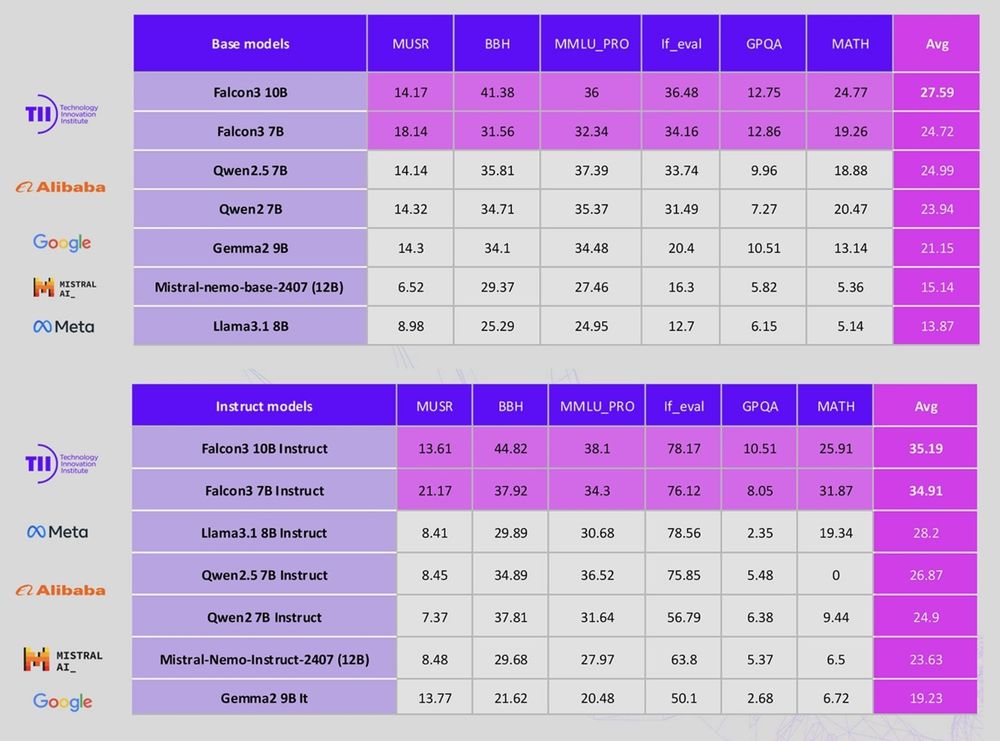
TII UAE's Falcon 3
1B, 3B, 7B, 10B (Base + Instruct) & 7B Mamba, trained on 14 trillion tokens!
- 1B-Base surpasses SmolLM2-1.7B and matches gemma-2-2b
- 3B-Base outperforms larger models like Llama-3.1-8B and Minitron-4B-Base
- 7B-Base is on par with Qwen2.5-7B in the under-9B category
1B, 3B, 7B, 10B (Base + Instruct) & 7B Mamba, trained on 14 trillion tokens!
- 1B-Base surpasses SmolLM2-1.7B and matches gemma-2-2b
- 3B-Base outperforms larger models like Llama-3.1-8B and Minitron-4B-Base
- 7B-Base is on par with Qwen2.5-7B in the under-9B category
December 17, 2024 at 3:07 PM
TII UAE's Falcon 3
1B, 3B, 7B, 10B (Base + Instruct) & 7B Mamba, trained on 14 trillion tokens!
- 1B-Base surpasses SmolLM2-1.7B and matches gemma-2-2b
- 3B-Base outperforms larger models like Llama-3.1-8B and Minitron-4B-Base
- 7B-Base is on par with Qwen2.5-7B in the under-9B category
1B, 3B, 7B, 10B (Base + Instruct) & 7B Mamba, trained on 14 trillion tokens!
- 1B-Base surpasses SmolLM2-1.7B and matches gemma-2-2b
- 3B-Base outperforms larger models like Llama-3.1-8B and Minitron-4B-Base
- 7B-Base is on par with Qwen2.5-7B in the under-9B category
Reposted by Dan Saattrup Smart

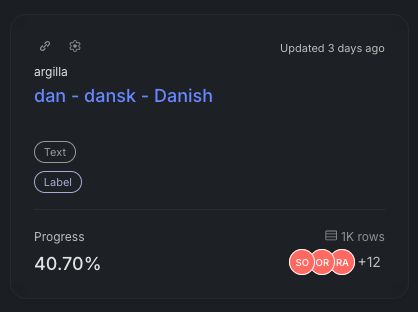
40,7% med hjælp fra 15 annotators! 🇩🇰😎🔥
Vi er kommet langt men ikke helt i mål endnu :) Det drejer sig virkelig ikke om mange annoteringer efterhånden.
Drømmer lidt om at vi kan få en lille slutspurt i løbet af ugen! Hjælp til her: data-is-better-together-fineweb-c.hf.space/dataset/5a58...
Vi er kommet langt men ikke helt i mål endnu :) Det drejer sig virkelig ikke om mange annoteringer efterhånden.
Drømmer lidt om at vi kan få en lille slutspurt i løbet af ugen! Hjælp til her: data-is-better-together-fineweb-c.hf.space/dataset/5a58...
December 16, 2024 at 8:43 AM
40,7% med hjælp fra 15 annotators! 🇩🇰😎🔥
Vi er kommet langt men ikke helt i mål endnu :) Det drejer sig virkelig ikke om mange annoteringer efterhånden.
Drømmer lidt om at vi kan få en lille slutspurt i løbet af ugen! Hjælp til her: data-is-better-together-fineweb-c.hf.space/dataset/5a58...
Vi er kommet langt men ikke helt i mål endnu :) Det drejer sig virkelig ikke om mange annoteringer efterhånden.
Drømmer lidt om at vi kan få en lille slutspurt i løbet af ugen! Hjælp til her: data-is-better-together-fineweb-c.hf.space/dataset/5a58...
December 13, 2024 at 5:32 PM
Reposted by Dan Saattrup Smart
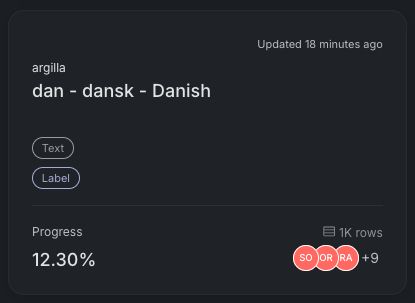
Dansk er gået fra 0.1% -> 12.3% i dag! Det svarer til at 123 tekster er annoteret af 3 personer.
Enhver annotering hjælper os med det første mål på 1000 tekster :)
Hjælp med til at annotere datasættet her: data-is-better-together-fineweb-c.hf.space/dataset/5a58... #dkai
Enhver annotering hjælper os med det første mål på 1000 tekster :)
Hjælp med til at annotere datasættet her: data-is-better-together-fineweb-c.hf.space/dataset/5a58... #dkai
December 12, 2024 at 11:10 AM
Dansk er gået fra 0.1% -> 12.3% i dag! Det svarer til at 123 tekster er annoteret af 3 personer.
Enhver annotering hjælper os med det første mål på 1000 tekster :)
Hjælp med til at annotere datasættet her: data-is-better-together-fineweb-c.hf.space/dataset/5a58... #dkai
Enhver annotering hjælper os med det første mål på 1000 tekster :)
Hjælp med til at annotere datasættet her: data-is-better-together-fineweb-c.hf.space/dataset/5a58... #dkai
Reposted by Dan Saattrup Smart
Vil du hjælpe med at forbedre kvaliteten af danske sprogmodeller?
Vær med til at hjælpe i annoteringssprintet! Det kræver ingen erfaring - bare gå ind på linket og begynd med annotering:)
huggingface.co/spaces/data-... #dkai #dktech
Længere opslag på LinkedIn: www.linkedin.com/posts/rasgaa...
Vær med til at hjælpe i annoteringssprintet! Det kræver ingen erfaring - bare gå ind på linket og begynd med annotering:)
huggingface.co/spaces/data-... #dkai #dktech
Længere opslag på LinkedIn: www.linkedin.com/posts/rasgaa...

December 10, 2024 at 12:11 PM
Vil du hjælpe med at forbedre kvaliteten af danske sprogmodeller?
Vær med til at hjælpe i annoteringssprintet! Det kræver ingen erfaring - bare gå ind på linket og begynd med annotering:)
huggingface.co/spaces/data-... #dkai #dktech
Længere opslag på LinkedIn: www.linkedin.com/posts/rasgaa...
Vær med til at hjælpe i annoteringssprintet! Det kræver ingen erfaring - bare gå ind på linket og begynd med annotering:)
huggingface.co/spaces/data-... #dkai #dktech
Længere opslag på LinkedIn: www.linkedin.com/posts/rasgaa...
Reposted by Dan Saattrup Smart

Danmark Starter Pack för dig i Malmö Öresundsregionen eller bara intresserad av Danmark och danskar.
Nyheter, tidningar, media, politik, organisationer...
#danmark #danskar #köpenhamn #öresund #malmö #skåne #nyheter #tidningar #media #politik #starterpack
go.bsky.app/U2VkkfU
Nyheter, tidningar, media, politik, organisationer...
#danmark #danskar #köpenhamn #öresund #malmö #skåne #nyheter #tidningar #media #politik #starterpack
go.bsky.app/U2VkkfU
December 3, 2024 at 7:11 AM
Danmark Starter Pack för dig i Malmö Öresundsregionen eller bara intresserad av Danmark och danskar.
Nyheter, tidningar, media, politik, organisationer...
#danmark #danskar #köpenhamn #öresund #malmö #skåne #nyheter #tidningar #media #politik #starterpack
go.bsky.app/U2VkkfU
Nyheter, tidningar, media, politik, organisationer...
#danmark #danskar #köpenhamn #öresund #malmö #skåne #nyheter #tidningar #media #politik #starterpack
go.bsky.app/U2VkkfU
Reposted by Dan Saattrup Smart

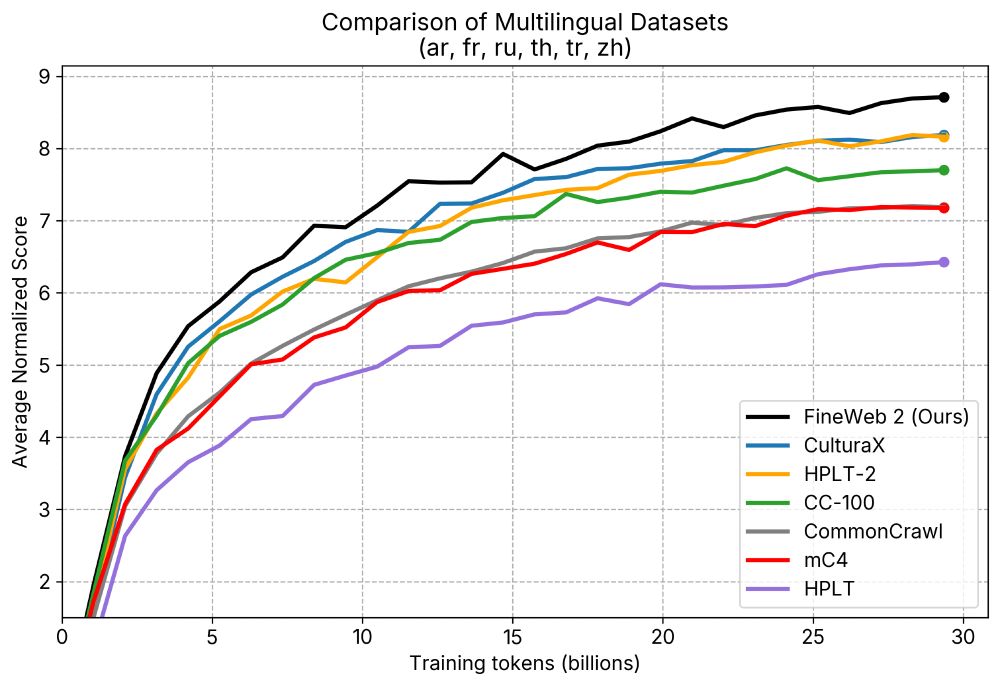
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
December 8, 2024 at 9:19 AM
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
*** New ScandEval evaluation ***
EuroLLM is a new series of European models, trained from scratch! They released both base and instruct models.
The base models can be used commercially, but the instruction models can't be, due to use of OpenAI outputs.
But how do they perform?
#nlp #evaluation
EuroLLM is a new series of European models, trained from scratch! They released both base and instruct models.
The base models can be used commercially, but the instruction models can't be, due to use of OpenAI outputs.
But how do they perform?
#nlp #evaluation
December 6, 2024 at 1:11 PM
*** New ScandEval evaluation ***
EuroLLM is a new series of European models, trained from scratch! They released both base and instruct models.
The base models can be used commercially, but the instruction models can't be, due to use of OpenAI outputs.
But how do they perform?
#nlp #evaluation
EuroLLM is a new series of European models, trained from scratch! They released both base and instruct models.
The base models can be used commercially, but the instruction models can't be, due to use of OpenAI outputs.
But how do they perform?
#nlp #evaluation
Reposted by Dan Saattrup Smart

Is MMLU Western-centric? 🤔
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...

December 5, 2024 at 4:31 PM
Is MMLU Western-centric? 🤔
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...