Sara Hooker
@sarahooker.bsky.social
7.6K followers
160 following
50 posts
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
Posts
Media
Videos
Starter Packs
Reposted by Sara Hooker




Sara Hooker
@sarahooker.bsky.social
· Apr 30





Sara Hooker
@sarahooker.bsky.social
· Apr 30




Reposted by Sara Hooker


Reposted by Sara Hooker


Reposted by Sara Hooker

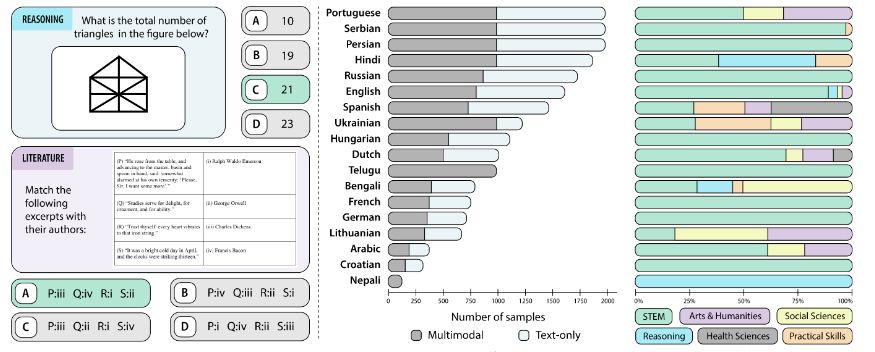




Reposted by Sara Hooker


Reposted by Sara Hooker
Reposted by Sara Hooker

Reposted by Sara Hooker
Reposted by Sara Hooker
Reposted by Sara Hooker

Reposted by Sara Hooker

Reposted by Sara Hooker
