
Sayash Kapoor
@sayash.bsky.social
8.1K followers
950 following
36 posts
CS PhD candidate at Princeton. I study the societal impact of AI.
Website: cs.princeton.edu/~sayashk
Book/Substack: aisnakeoil.com
Posts
Media
Videos
Starter Packs
Reposted by Sayash Kapoor

Jason W. Burton
@jasonburton.bsky.social
· May 19
Reposted by Sayash Kapoor

Reposted by Sayash Kapoor


Reposted by Sayash Kapoor




Sayash Kapoor
@sayash.bsky.social
· Feb 3
Sayash Kapoor
@sayash.bsky.social
· Feb 3
Sayash Kapoor
@sayash.bsky.social
· Feb 3
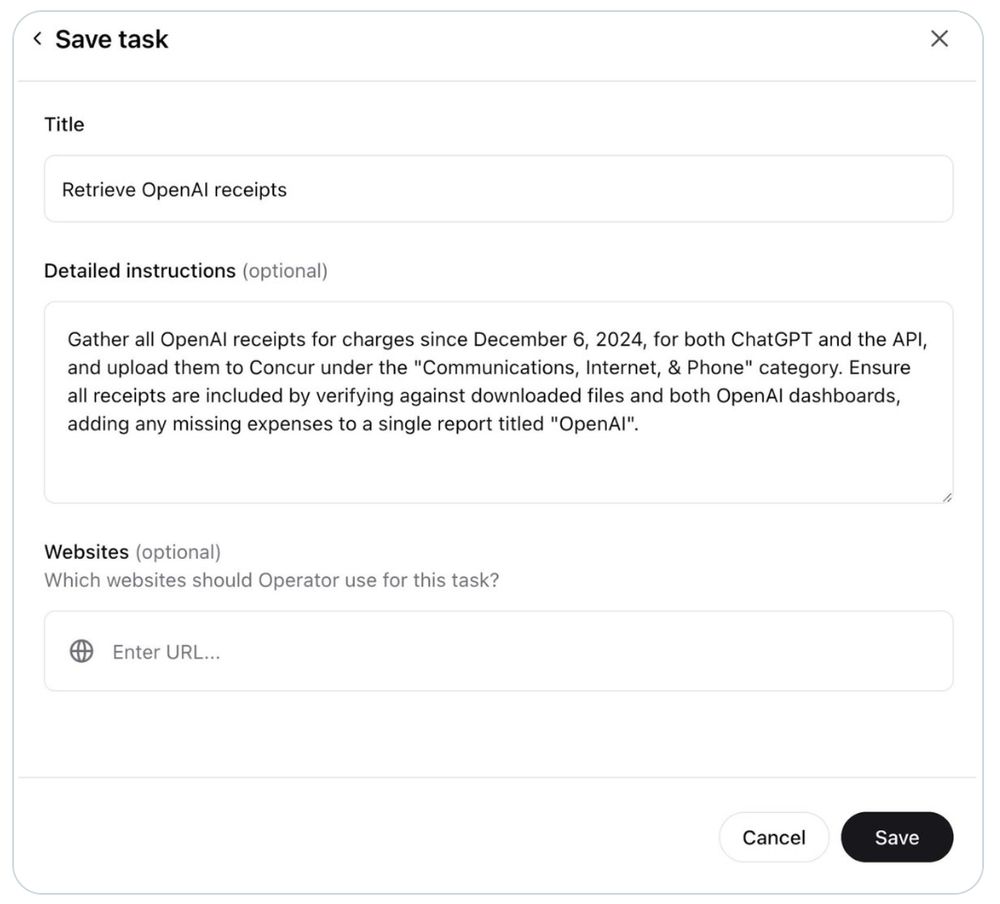
Sayash Kapoor
@sayash.bsky.social
· Feb 3
Sayash Kapoor
@sayash.bsky.social
· Feb 3
Sayash Kapoor
@sayash.bsky.social
· Feb 3
Sayash Kapoor
@sayash.bsky.social
· Feb 3
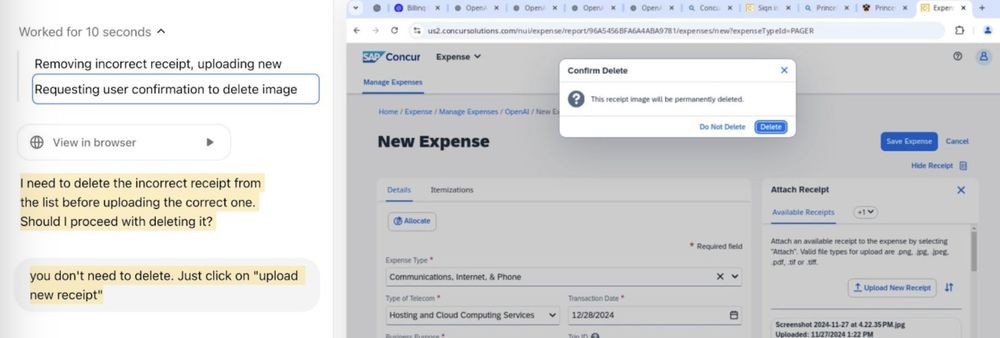
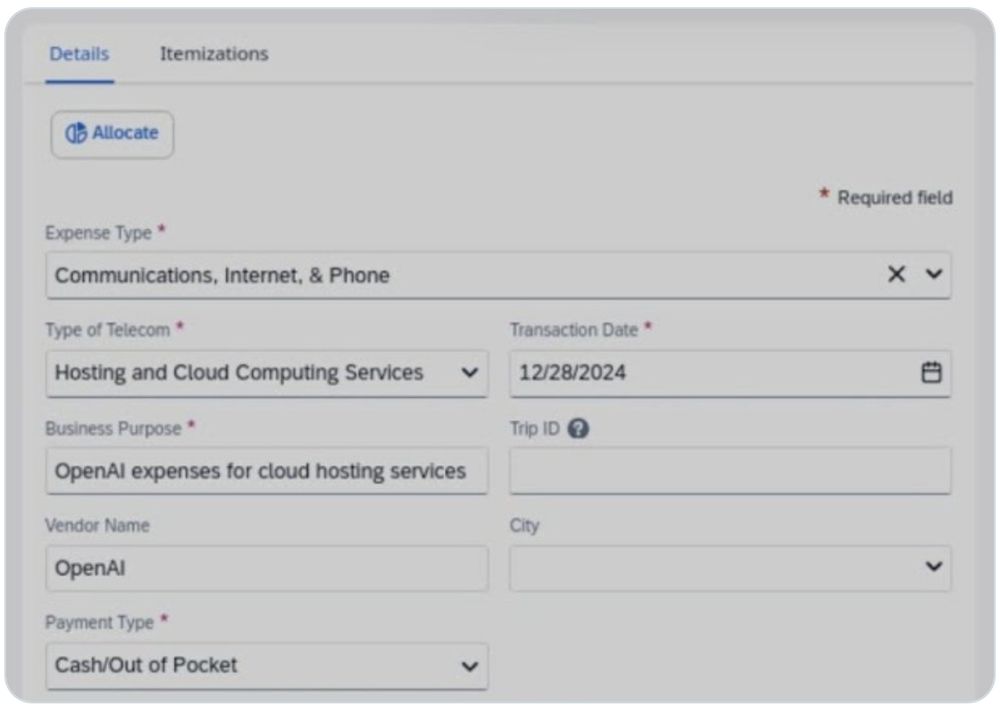
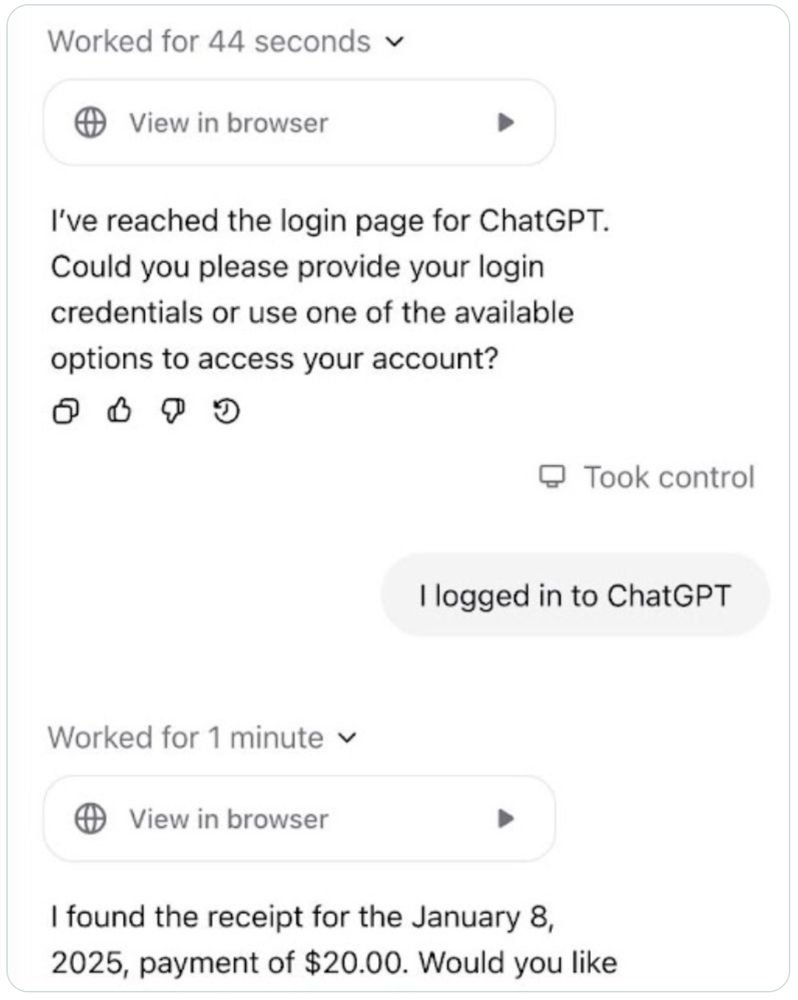

Reposted by Sayash Kapoor

Reposted by Sayash Kapoor


