



Shikhar
@shikharb.bsky.social
PhD student WAVLab@LTI, CMU
Multimodality and multilinguality
prev. predoc Google Deepmind
Multimodality and multilinguality
prev. predoc Google Deepmind
Reposted by Shikhar

Can we make discrete speech units lightweight🪶 and streamable🏎? Excited to share our new #Interspeech2025 paper: On-device Streaming Discrete Speech Units arxiv.org/abs/2506.01845 (1/n)

August 15, 2025 at 8:44 PM
Can we make discrete speech units lightweight🪶 and streamable🏎? Excited to share our new #Interspeech2025 paper: On-device Streaming Discrete Speech Units arxiv.org/abs/2506.01845 (1/n)
Meows, music, murmurs and more - we trained a general purpose audio encoder and open sourced the code, checkpoint and evaluation toolkit.

OpenBEATs, an open-source audio encoder, extends BEATs via multi-domain pre-training; achieves state-of-the-art performance on bioacoustics, environmental sound, and reasoning datasets, outperforming larger models.
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Shikhar Bharadwaj, Samuele Cornell, Kwanghee Choi, Satoru Fukayama, Hye-jin Shim, Soham Deshmukh, Shinji Watanabe
arxiv.org
July 22, 2025 at 3:36 AM
Meows, music, murmurs and more - we trained a general purpose audio encoder and open sourced the code, checkpoint and evaluation toolkit.
Reposted by Shikhar

📢 We've open-sourced NatureLM-audio, the first audio-language foundation model for #bioacoustics.
Trained on large-scale animal vocalization, human speech & music datasets, the model enables zero-shot classification, detection & querying across diverse species & environments 👇🏽
Trained on large-scale animal vocalization, human speech & music datasets, the model enables zero-shot classification, detection & querying across diverse species & environments 👇🏽

April 24, 2025 at 3:55 PM
📢 We've open-sourced NatureLM-audio, the first audio-language foundation model for #bioacoustics.
Trained on large-scale animal vocalization, human speech & music datasets, the model enables zero-shot classification, detection & querying across diverse species & environments 👇🏽
Trained on large-scale animal vocalization, human speech & music datasets, the model enables zero-shot classification, detection & querying across diverse species & environments 👇🏽
Reposted by Shikhar

🔗 Resources for ESPnet-SDS:
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
March 17, 2025 at 2:29 PM
🔗 Resources for ESPnet-SDS:
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
Reposted by Shikhar
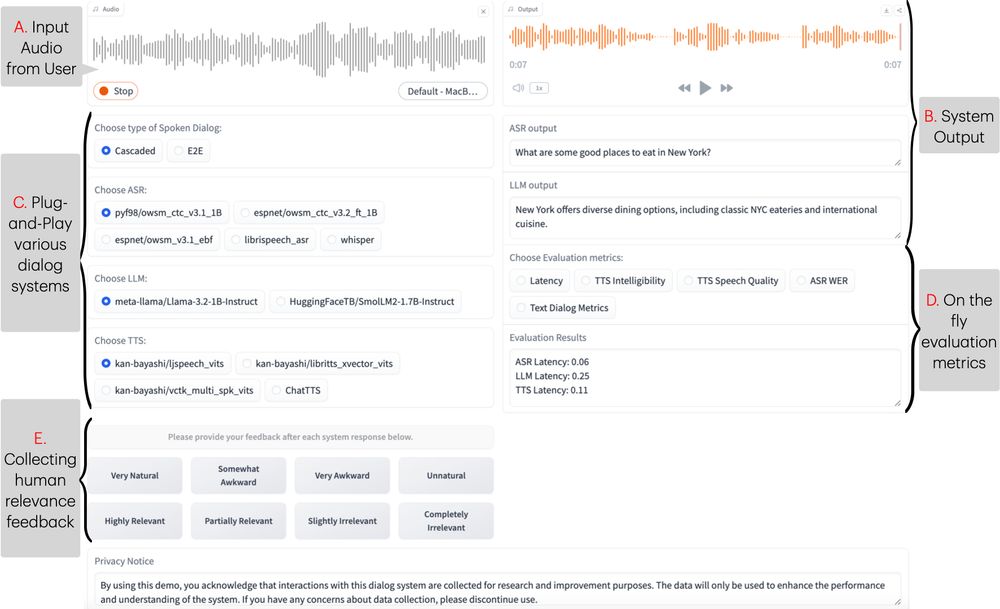
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
March 17, 2025 at 2:29 PM
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
Reposted by Shikhar
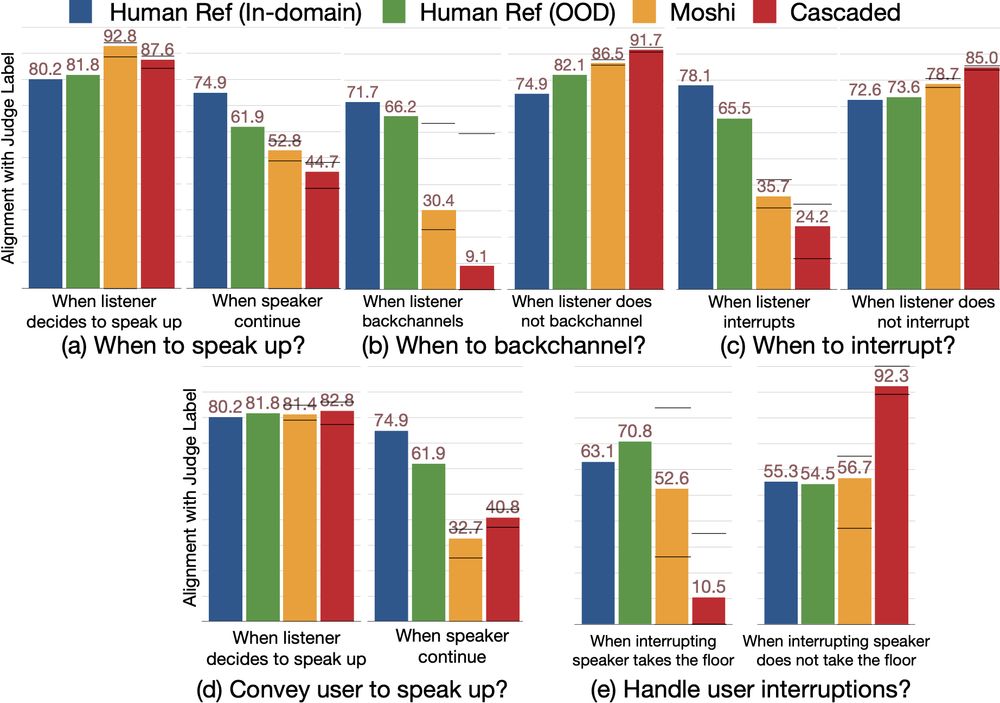
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
March 5, 2025 at 4:03 PM
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
Reposted by Shikhar

Reposted by Shikhar

Philip Whittington, Gregor Bachmann, Tiago Pimentel
Tokenisation is NP-Complete
https://arxiv.org/abs/2412.15210
Tokenisation is NP-Complete
https://arxiv.org/abs/2412.15210
December 20, 2024 at 5:18 AM
Philip Whittington, Gregor Bachmann, Tiago Pimentel
Tokenisation is NP-Complete
https://arxiv.org/abs/2412.15210
Tokenisation is NP-Complete
https://arxiv.org/abs/2412.15210
Reposted by Shikhar
Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇

December 5, 2024 at 12:45 AM
Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇
Reposted by Shikhar

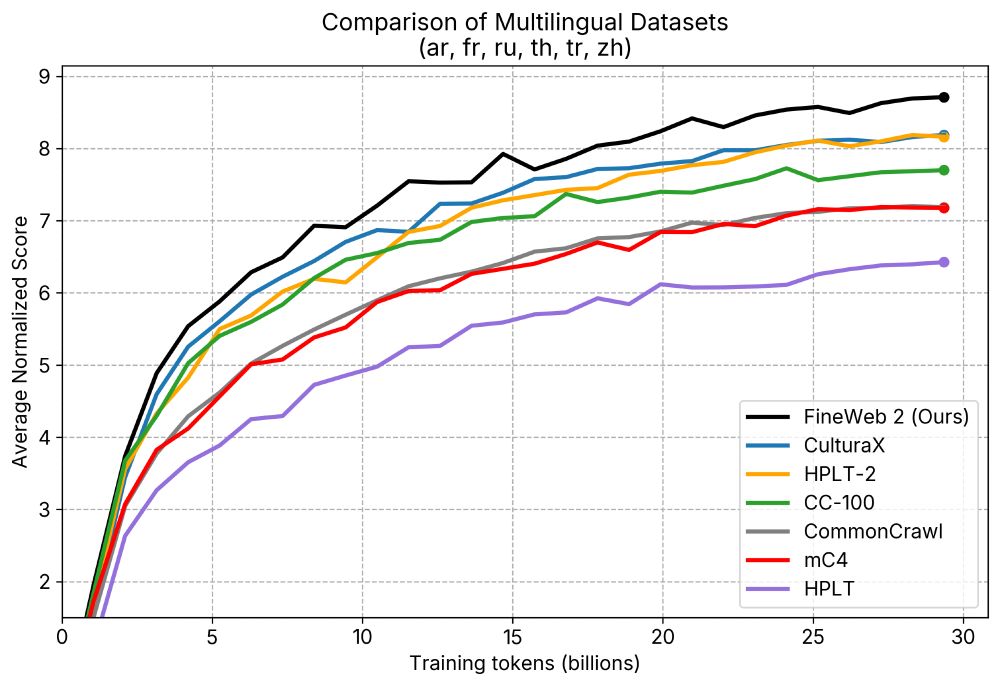
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
December 8, 2024 at 9:19 AM
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
Reposted by Shikhar

WAVLab is up in bsky!
December 6, 2024 at 7:15 PM
WAVLab is up in bsky!
Reposted by Shikhar

We are excited to announce the launch of ML SUPERB 2.0 (multilingual.superbbenchmark.org) as part of the Interspeech 2024 official challenge! We hope this upgraded version of ML SUPERB advances universal access to speech processing worldwide. Please join it!
#Interspeech2025
#Interspeech2025




December 4, 2024 at 2:45 PM
We are excited to announce the launch of ML SUPERB 2.0 (multilingual.superbbenchmark.org) as part of the Interspeech 2024 official challenge! We hope this upgraded version of ML SUPERB advances universal access to speech processing worldwide. Please join it!
#Interspeech2025
#Interspeech2025
Reposted by Shikhar

I've started putting together a starter pack with people working on Speech Technology and Speech Science: go.bsky.app/BQ7mbkA
(Self-)nominations welcome!
(Self-)nominations welcome!
November 19, 2024 at 11:13 AM
I've started putting together a starter pack with people working on Speech Technology and Speech Science: go.bsky.app/BQ7mbkA
(Self-)nominations welcome!
(Self-)nominations welcome!
Reposted by Shikhar

iNatSounds: new dataset from folks @inaturalist.bsky.social & co-authors; looks to be one of the largest public datasets of animal sounds
openreview.net/forum?id=QCY...
github.com/visipedia/in...
#prattle 💬
#bioacoustics
openreview.net/forum?id=QCY...
github.com/visipedia/in...
#prattle 💬
#bioacoustics


November 29, 2024 at 3:30 AM
iNatSounds: new dataset from folks @inaturalist.bsky.social & co-authors; looks to be one of the largest public datasets of animal sounds
openreview.net/forum?id=QCY...
github.com/visipedia/in...
#prattle 💬
#bioacoustics
openreview.net/forum?id=QCY...
github.com/visipedia/in...
#prattle 💬
#bioacoustics
Reposted by Shikhar

We're here too now! 🥳
November 22, 2024 at 2:42 PM
We're here too now! 🥳