Somin W
@sominw.bsky.social
31 followers
71 following
10 posts
cs phd @ northeastern.
opinions on new england & beyond..
Posts
Media
Videos
Starter Packs




Somin W
@sominw.bsky.social
· Feb 11

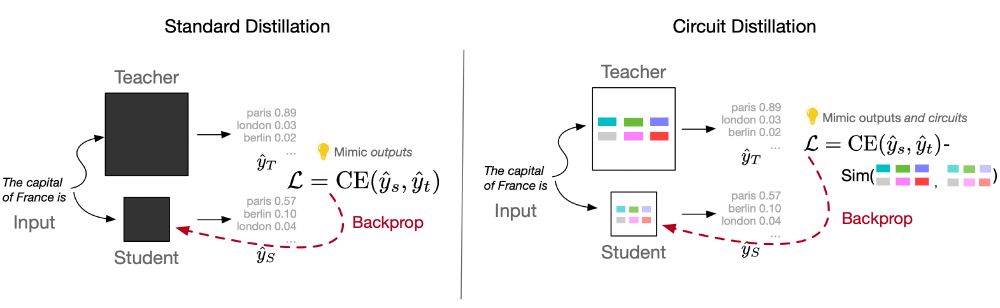
Who Taught You That? Tracing Teachers in Model Distillation
Model distillation -- using outputs from a large teacher model to teach a small student model -- is a practical means of creating efficient models for a particular task. We ask: Can we identify a stud...
arxiv.org
Somin W
@sominw.bsky.social
· Feb 11




Somin W
@sominw.bsky.social
· Feb 11
Who Taught You That? Tracing Teachers in Model Distillation
Model distillation -- using outputs from a large teacher model to teach a small student model -- is a practical means of creating efficient models for a particular task. We ask: Can we identify a stud...
arxiv.org