Posts
Media
Videos
Starter Packs
Reposted



sta8is.bsky.social
@sta8is.bsky.social
· Feb 26

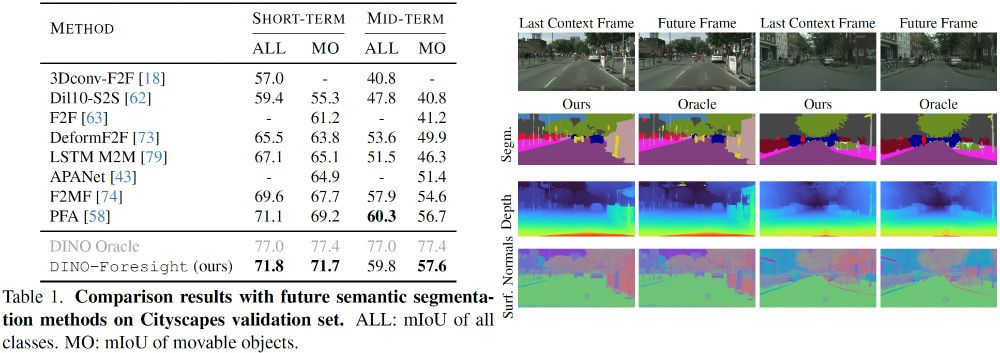
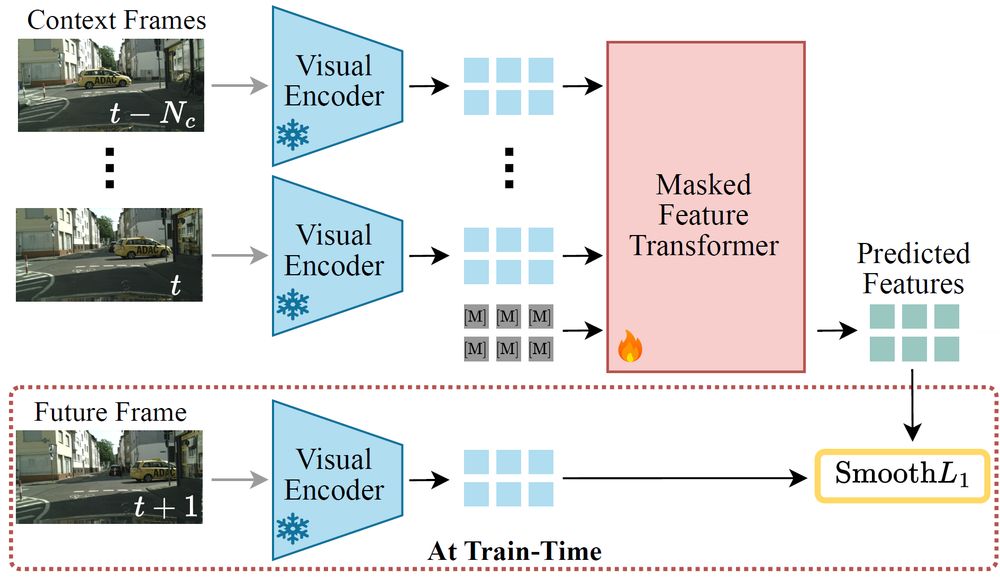
Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers
Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified a...
arxiv.org







Reposted