



Sterling Fluharty
@sterlingfluharty.bsky.social
Independent Scholar. Working in history and data.
Interesting observations. I imagine the committee that produced these guidelines tried to critique techno-optimism, but ended up uncritically incorporating their perception of a critical perspective (“stochastic parrots”). The follow-up event this week hints at an effort to recalibrate the guidance.


September 22, 2025 at 5:16 PM
Interesting observations. I imagine the committee that produced these guidelines tried to critique techno-optimism, but ended up uncritically incorporating their perception of a critical perspective (“stochastic parrots”). The follow-up event this week hints at an effort to recalibrate the guidance.
Agreed. I sometimes wonder how the different constituencies and sides of the issues will learn from each other. We can certainly publish our work, and hope that readers will find it. I’m also a fan of bringing people together. I was excited to see the space given to AI in the 2025 SSHA CFP.

September 8, 2025 at 8:56 PM
Agreed. I sometimes wonder how the different constituencies and sides of the issues will learn from each other. We can certainly publish our work, and hope that readers will find it. I’m also a fan of bringing people together. I was excited to see the space given to AI in the 2025 SSHA CFP.
Tracing copyright ownership is another complexity not fully explored by the proposed settlement. The copyright could be held by an author, heirs, a publisher, or an employer. I also saw no discussion of reversion rights in the court doc, but payouts for books out of print could motivate parties.



September 5, 2025 at 10:13 PM
Tracing copyright ownership is another complexity not fully explored by the proposed settlement. The copyright could be held by an author, heirs, a publisher, or an employer. I also saw no discussion of reversion rights in the court doc, but payouts for books out of print could motivate parties.
Another complication is that many authors of copyrighted books may have passed away. It is possible that many authors with U.S. copyrighted books live outside the country. And I’m not sure the proposed settlement explains the payout for a textbook with multiple editions and ISBNs but one copyright.



September 5, 2025 at 10:06 PM
Another complication is that many authors of copyrighted books may have passed away. It is possible that many authors with U.S. copyrighted books live outside the country. And I’m not sure the proposed settlement explains the payout for a textbook with multiple editions and ISBNs but one copyright.
There will likely be additional complications for this proposed plan. The publishing landscape in the U.S. has seen significant consolidation over the last century, and apparently the fates of publishing houses (e.g., who bought who or was merged into who) isn’t tracked by the U.S. copyright office.


September 5, 2025 at 9:53 PM
There will likely be additional complications for this proposed plan. The publishing landscape in the U.S. has seen significant consolidation over the last century, and apparently the fates of publishing houses (e.g., who bought who or was merged into who) isn’t tracked by the U.S. copyright office.
If approved, Anthropic has 120 days to 2 years to pay out. Authors & publishers can submit claims by mail and online. There will be a campaign via print and online to get word out. After receiving notice from an administrator, a potential claimant has 60 days to opt-out and 120 days to file a claim.




September 5, 2025 at 9:26 PM
If approved, Anthropic has 120 days to 2 years to pay out. Authors & publishers can submit claims by mail and online. There will be a campaign via print and online to get word out. After receiving notice from an administrator, a potential claimant has 60 days to opt-out and 120 days to file a claim.
Anthropic had 7M downloads from pirated books. Metadata, esp. ISBN, was extracted and matched to registration records from U.S. Copyright Office. Dedup, false pos & neg, and other robust checks yielded 465k books on Works List. Anthropic will report by Sept 15 whether it will add additional books.


September 5, 2025 at 9:17 PM
Anthropic had 7M downloads from pirated books. Metadata, esp. ISBN, was extracted and matched to registration records from U.S. Copyright Office. Dedup, false pos & neg, and other robust checks yielded 465k books on Works List. Anthropic will report by Sept 15 whether it will add additional books.
There is a proposed plan of allocation that is designed to help authors and publishers figure out how to split the $3k per pirated book.

September 5, 2025 at 9:11 PM
There is a proposed plan of allocation that is designed to help authors and publishers figure out how to split the $3k per pirated book.
I have questions (below is NYTimes today). Why did Turvey go to publishers vs research libraries? If Anthropic took 500k pirated books, did they buy millions from publishers? How does this impact Public Interest Corpus? Is $3k per pirated book insulting? What kind of response if 500k list released?

September 5, 2025 at 8:12 PM
I have questions (below is NYTimes today). Why did Turvey go to publishers vs research libraries? If Anthropic took 500k pirated books, did they buy millions from publishers? How does this impact Public Interest Corpus? Is $3k per pirated book insulting? What kind of response if 500k list released?
Perplexity also agreed with the assessment that there has been a hardening of views this year and offered a few reasons for the shift in attitudes, some of which seemed to reflect the range of responses yesterday to the AHA's new guidelines for AI in history education.



August 6, 2025 at 12:12 PM
Perplexity also agreed with the assessment that there has been a hardening of views this year and offered a few reasons for the shift in attitudes, some of which seemed to reflect the range of responses yesterday to the AHA's new guidelines for AI in history education.
Thanks for the thoughtful post. I checked with Perplexity and it confirmed there is some survey data for the trends we are seeing. I'll probably update my code for scraping Bluesky to analyze the latest batch of posts. The ideas and issues at stake should enhance the conference paper I'm writing.




August 6, 2025 at 12:04 PM
Thanks for the thoughtful post. I checked with Perplexity and it confirmed there is some survey data for the trends we are seeing. I'll probably update my code for scraping Bluesky to analyze the latest batch of posts. The ideas and issues at stake should enhance the conference paper I'm writing.
There might be some lessons in this announcement a couple weekends ago and the responses it drew:

June 4, 2025 at 3:47 PM
There might be some lessons in this announcement a couple weekends ago and the responses it drew:
The AHA has just reported that it filed yesterday, along with ACLS and MLA, a motion for preliminary injunction on behalf of NEH, in response to the harms done by DOGE. I asked OpenAI’s o3 model to evaluate the motion and the model gives it a 70% chance of success. I hope we prevail in the courts.




May 15, 2025 at 10:00 PM
The AHA has just reported that it filed yesterday, along with ACLS and MLA, a motion for preliminary injunction on behalf of NEH, in response to the harms done by DOGE. I asked OpenAI’s o3 model to evaluate the motion and the model gives it a 70% chance of success. I hope we prevail in the courts.
From my own sleuthing, and according to 4o, it appears a third to two-thirds of the public-domain books are in the Internet Archive. Below are some bullets from 4o that I found useful for developing a coordinated cleaning framework. A pipeline with a model such as Claude could do cleaning at scale.

May 13, 2025 at 9:25 PM
From my own sleuthing, and according to 4o, it appears a third to two-thirds of the public-domain books are in the Internet Archive. Below are some bullets from 4o that I found useful for developing a coordinated cleaning framework. A pipeline with a model such as Claude could do cleaning at scale.
It looks like there at least 6M public-domain books that have been scanned. If more institutions than Harvard could arrange for the release of what Google scanned, perhaps we could coordinate cleaning for these volumes, similar to what Project Gutenberg has done, but maybe in more automated fashion.


May 13, 2025 at 8:35 PM
It looks like there at least 6M public-domain books that have been scanned. If more institutions than Harvard could arrange for the release of what Google scanned, perhaps we could coordinate cleaning for these volumes, similar to what Project Gutenberg has done, but maybe in more automated fashion.
Here are a couple books coming out this summer. I’ll probably read Bender’s book, given the impact her ”stochastic parrots” paper had over the last few years. You can get a preview of the book’s arguments in the interview published in this news article yesterday: www.sfexaminer.com/news/technol...


May 7, 2025 at 9:54 PM
Here are a couple books coming out this summer. I’ll probably read Bender’s book, given the impact her ”stochastic parrots” paper had over the last few years. You can get a preview of the book’s arguments in the interview published in this news article yesterday: www.sfexaminer.com/news/technol...
I think adding the term "interdisciplinary" to Google ngram creates a useful comparison. I also asked the o3 model and it finds that the boundary between the humanities and social sciences was blurred a bit after about the turn of the century by interdisciplinary approaches to problem solving.


May 3, 2025 at 1:27 PM
I think adding the term "interdisciplinary" to Google ngram creates a useful comparison. I also asked the o3 model and it finds that the boundary between the humanities and social sciences was blurred a bit after about the turn of the century by interdisciplinary approaches to problem solving.
Agreed, this is an important development. I asked the o3 model to read the 46-page filing: www.historians.org/wp-content/u.... It said the plaintiffs have a 70-75% of getting a preliminary injunction & a 65-70% chance of receiving a favorable judgement on the merits of the case, which gives me hope.

May 1, 2025 at 8:00 PM
Agreed, this is an important development. I asked the o3 model to read the 46-page filing: www.historians.org/wp-content/u.... It said the plaintiffs have a 70-75% of getting a preliminary injunction & a 65-70% chance of receiving a favorable judgement on the merits of the case, which gives me hope.
I just received this email that the AHA is exploring possible legal action to protect historical funding from the NEH and other agencies. With some help from ChatGPT, I found that similar advocacy at the federal level to protect the work of historians has been successful before. I hope we prevail.




April 17, 2025 at 7:47 PM
I just received this email that the AHA is exploring possible legal action to protect historical funding from the NEH and other agencies. With some help from ChatGPT, I found that similar advocacy at the federal level to protect the work of historians has been successful before. I hope we prevail.
I’m guessing our chats with a hive mind made it likely ;-) It was a bit painful reading about ChroniclingAmericaQA. The authors seem not to realize that text mining can be a dangerous art. I’ll add that Claude’s web search and extended thinking, while polite and deferential, did not find the paper.

April 17, 2025 at 4:27 PM
I’m guessing our chats with a hive mind made it likely ;-) It was a bit painful reading about ChroniclingAmericaQA. The authors seem not to realize that text mining can be a dangerous art. I’ll add that Claude’s web search and extended thinking, while polite and deferential, did not find the paper.
I read "Provocations from the Humanities for Generative AI Research" (arxiv.org/abs/2502.19190). This got me wondering about adding social sciences and focusing on history. I prompted o1 Deep Research to reimagine the paper (chatgpt.com/share/67c0e7...) and generate more provocations (see below):


February 27, 2025 at 10:40 PM
I read "Provocations from the Humanities for Generative AI Research" (arxiv.org/abs/2502.19190). This got me wondering about adding social sciences and focusing on history. I prompted o1 Deep Research to reimagine the paper (chatgpt.com/share/67c0e7...) and generate more provocations (see below):
This post (resobscura.substack.com/p/the-leadin..., HT @nic221.bsky.social) by @resobscura.bsky.social caught my attention. Perhaps taking a cue from the author, I enlisted the help of the o1 model in a close reading of the text. You can peruse the remaining response at chatgpt.com/share/6791ca....




January 23, 2025 at 4:51 AM
This post (resobscura.substack.com/p/the-leadin..., HT @nic221.bsky.social) by @resobscura.bsky.social caught my attention. Perhaps taking a cue from the author, I enlisted the help of the o1 model in a close reading of the text. You can peruse the remaining response at chatgpt.com/share/6791ca....
I’m enjoying today’s episode of the History in Focus podcast, which is a discussion with historians of what AI means for teaching and research:

December 18, 2024 at 2:16 PM
I’m enjoying today’s episode of the History in Focus podcast, which is a discussion with historians of what AI means for teaching and research:
I just tried. I uploaded 300 pages of transcribed chancery court orders from 1846 to 1871 at askyourpdf.com. I then used the plugin for ChatGPT to query the document. Below is my prompt to analyze change and continuity in the document and a few screenshots that illustrate how the model responded.




December 12, 2024 at 4:16 AM
I just tried. I uploaded 300 pages of transcribed chancery court orders from 1846 to 1871 at askyourpdf.com. I then used the plugin for ChatGPT to query the document. Below is my prompt to analyze change and continuity in the document and a few screenshots that illustrate how the model responded.
You can set up a simple workflow after registration of a student. After the login, from the home page there is a button in the top right titled “Quick Text Recognition.” Next is prompt to upload a page. That is followed by automatic detection and the option to open the transcription in an editor.
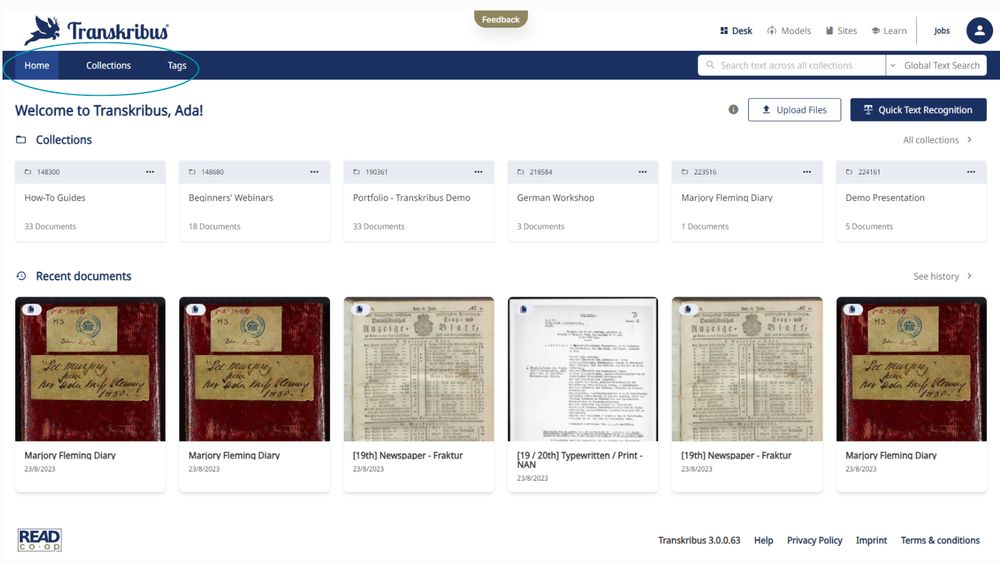
December 11, 2024 at 11:42 PM
You can set up a simple workflow after registration of a student. After the login, from the home page there is a button in the top right titled “Quick Text Recognition.” Next is prompt to upload a page. That is followed by automatic detection and the option to open the transcription in an editor.